 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified Embedding Based Personalized Retrieval in Etsy Search
Jun 07, 2023
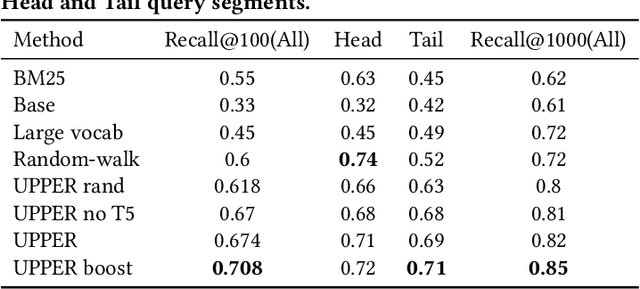
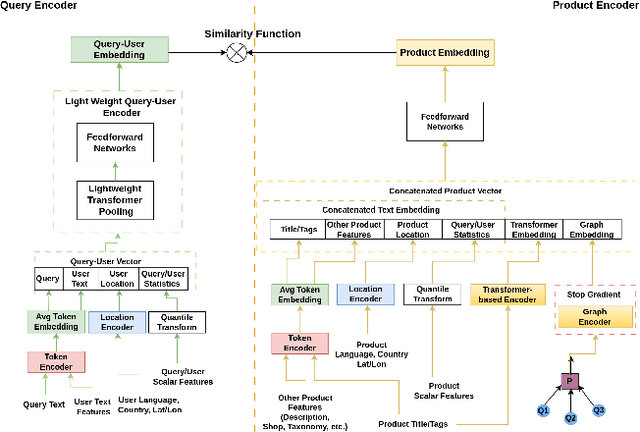

Embedding-based neural retrieval is a prevalent approach to address the semantic gap problem which often arises in product search on tail queries. In contrast, popular queries typically lack context and have a broad intent where additional context from users historical interaction can be helpful. In this paper, we share our novel approach to address both: the semantic gap problem followed by an end to end trained model for personalized semantic retrieval. We propose learning a unified embedding model incorporating graph, transformer and term-based embeddings end to end and share our design choices for optimal tradeoff between performance and efficiency. We share our learnings in feature engineering, hard negative sampling strategy, and application of transformer model, including a novel pre-training strategy and other tricks for improving search relevance and deploying such a model at industry scale. Our personalized retrieval model significantly improves the overall search experience, as measured by a 5.58% increase in search purchase rate and a 2.63% increase in site-wide conversion rate, aggregated across multiple A/B tests - on live traffic.
Towards Semantic Query Segmentation
Jul 25, 2017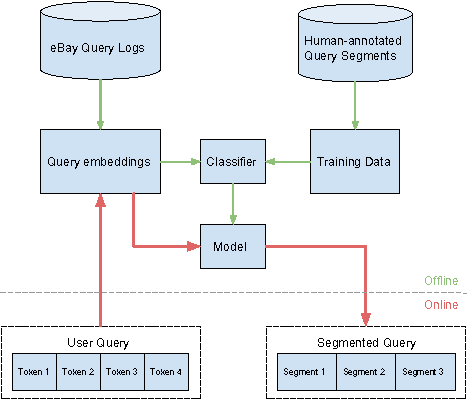

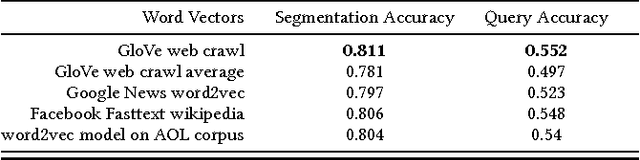
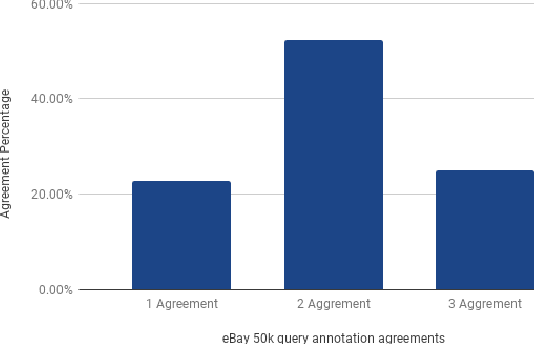
Query Segmentation is one of the critical components for understanding users' search intent in Information Retrieval tasks. It involves grouping tokens in the search query into meaningful phrases which help downstream tasks like search relevance and query understanding. In this paper, we propose a novel approach to segment user queries using distributed query embeddings. Our key contribution is a supervised approach to the segmentation task using low-dimensional feature vectors for queries, getting rid of traditional hand tuned and heuristic NLP features which are quite expensive. We benchmark on a 50,000 human-annotated web search engine query corpus achieving comparable accuracy to state-of-the-art techniques. The advantage of our technique is its fast and does not use external knowledge-base like Wikipedia for score boosting. This helps us generalize our approach to other domains like eCommerce without any fine-tuning. We demonstrate the effectiveness of this method on another 50,000 human-annotated eCommerce query corpus from eBay search logs. Our approach is easy to implement and generalizes well across different search domains proving the power of low-dimensional embeddings in query segmentation task, opening up a new direction of research for this problem.