 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeITEm: Unsupervised Image-Text Embedding Learning for eCommerce
Oct 22, 2023



Product embedding serves as a cornerstone for a wide range of applications in eCommerce. The product embedding learned from multiple modalities shows significant improvement over that from a single modality, since different modalities provide complementary information. However, some modalities are more informatively dominant than others. How to teach a model to learn embedding from different modalities without neglecting information from the less dominant modality is challenging. We present an image-text embedding model (ITEm), an unsupervised learning method that is designed to better attend to image and text modalities. We extend BERT by (1) learning an embedding from text and image without knowing the regions of interest; (2) training a global representation to predict masked words and to construct masked image patches without their individual representations. We evaluate the pre-trained ITEm on two tasks: the search for extremely similar products and the prediction of product categories, showing substantial gains compared to strong baseline models.
Mask More and Mask Later: Efficient Pre-training of Masked Language Models by Disentangling the Token
Nov 15, 2022The pre-training of masked language models (MLMs) consumes massive computation to achieve good results on downstream NLP tasks, resulting in a large carbon footprint. In the vanilla MLM, the virtual tokens, [MASK]s, act as placeholders and gather the contextualized information from unmasked tokens to restore the corrupted information. It raises the question of whether we can append [MASK]s at a later layer, to reduce the sequence length for earlier layers and make the pre-training more efficient. We show: (1) [MASK]s can indeed be appended at a later layer, being disentangled from the word embedding; (2) The gathering of contextualized information from unmasked tokens can be conducted with a few layers. By further increasing the masking rate from 15% to 50%, we can pre-train RoBERTa-base and RoBERTa-large from scratch with only 78% and 68% of the original computational budget without any degradation on the GLUE benchmark. When pre-training with the original budget, our method outperforms RoBERTa for 6 out of 8 GLUE tasks, on average by 0.4%.
Back-translation for Large-Scale Multilingual Machine Translation
Sep 17, 2021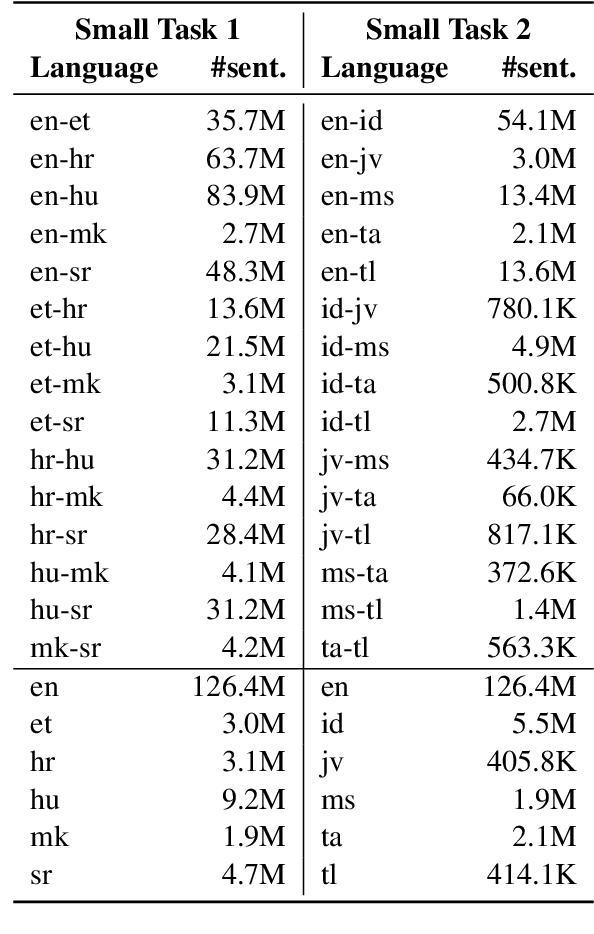
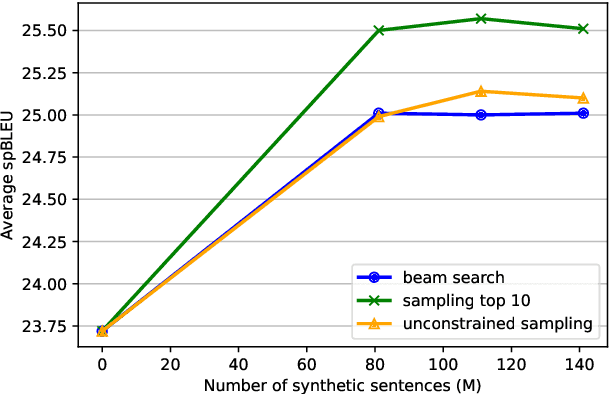


This paper illustrates our approach to the shared task on large-scale multilingual machine translation in the sixth conference on machine translation (WMT-21). This work aims to build a single multilingual translation system with a hypothesis that a universal cross-language representation leads to better multilingual translation performance. We extend the exploration of different back-translation methods from bilingual translation to multilingual translation. Better performance is obtained by the constrained sampling method, which is different from the finding of the bilingual translation. Besides, we also explore the effect of vocabularies and the amount of synthetic data. Surprisingly, the smaller size of vocabularies perform better, and the extensive monolingual English data offers a modest improvement. We submitted to both the small tasks and achieved the second place.
Word-based Domain Adaptation for Neural Machine Translation
Jun 07, 2019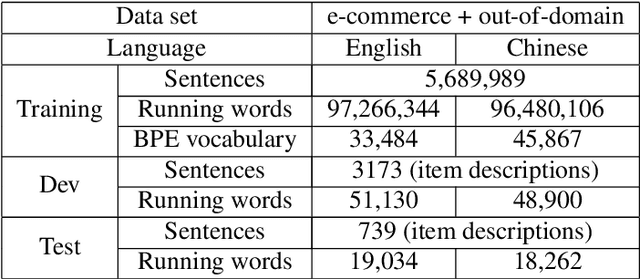
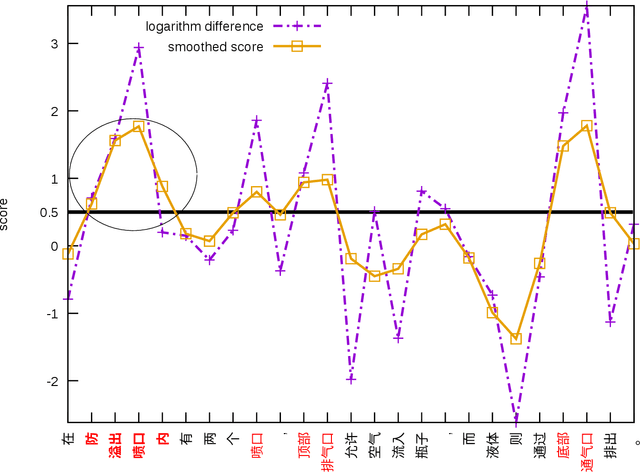
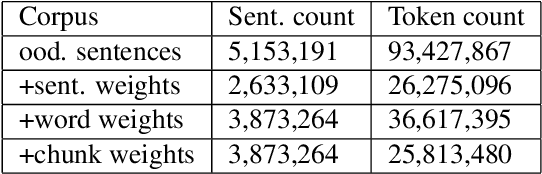
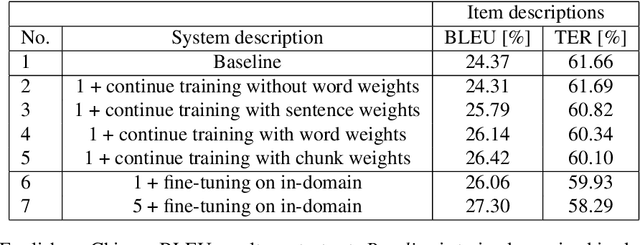
In this paper, we empirically investigate applying word-level weights to adapt neural machine translation to e-commerce domains, where small e-commerce datasets and large out-of-domain datasets are available. In order to mine in-domain like words in the out-of-domain datasets, we compute word weights by using a domain-specific and a non-domain-specific language model followed by smoothing and binary quantization. The baseline model is trained on mixed in-domain and out-of-domain datasets. Experimental results on English to Chinese e-commerce domain translation show that compared to continuing training without word weights, it improves MT quality by up to 2.11% BLEU absolute and 1.59% TER. We have also trained models using fine-tuning on the in-domain data. Pre-training a model with word weights improves fine-tuning up to 1.24% BLEU absolute and 1.64% TER, respectively.
* Published on the proceedings of the International Workshop on Spoken Language Translation (IWSLT), 2018
Towards Semantic Query Segmentation
Jul 25, 2017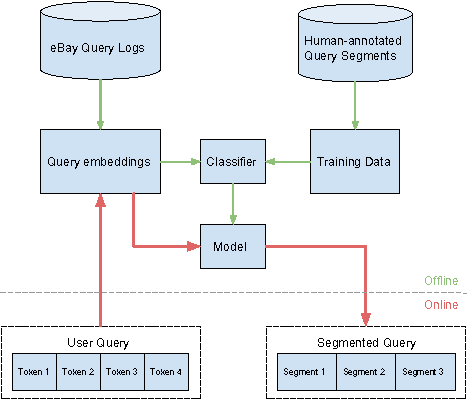

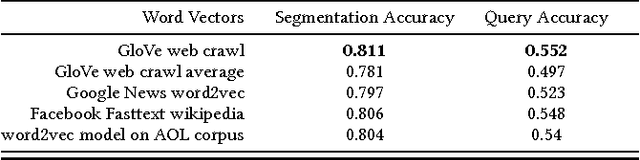
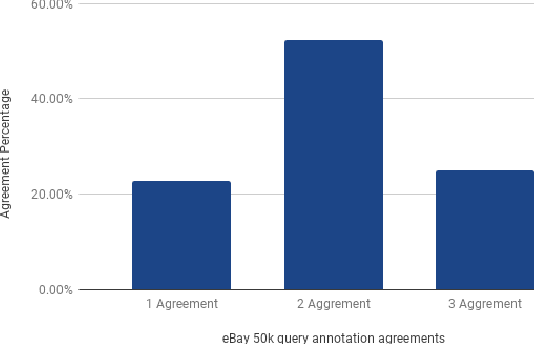
Query Segmentation is one of the critical components for understanding users' search intent in Information Retrieval tasks. It involves grouping tokens in the search query into meaningful phrases which help downstream tasks like search relevance and query understanding. In this paper, we propose a novel approach to segment user queries using distributed query embeddings. Our key contribution is a supervised approach to the segmentation task using low-dimensional feature vectors for queries, getting rid of traditional hand tuned and heuristic NLP features which are quite expensive. We benchmark on a 50,000 human-annotated web search engine query corpus achieving comparable accuracy to state-of-the-art techniques. The advantage of our technique is its fast and does not use external knowledge-base like Wikipedia for score boosting. This helps us generalize our approach to other domains like eCommerce without any fine-tuning. We demonstrate the effectiveness of this method on another 50,000 human-annotated eCommerce query corpus from eBay search logs. Our approach is easy to implement and generalizes well across different search domains proving the power of low-dimensional embeddings in query segmentation task, opening up a new direction of research for this problem.