 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain Adaptation of Foundation LLMs for e-Commerce
Jan 16, 2025We present the e-Llama models: 8 billion and 70 billion parameter large language models that are adapted towards the e-commerce domain. These models are meant as foundation models with deep knowledge about e-commerce, that form a base for instruction- and fine-tuning. The e-Llama models are obtained by continuously pretraining the Llama 3.1 base models on 1 trillion tokens of domain-specific data. We discuss our approach and motivate our choice of hyperparameters with a series of ablation studies. To quantify how well the models have been adapted to the e-commerce domain, we define and implement a set of multilingual, e-commerce specific evaluation tasks. We show that, when carefully choosing the training setup, the Llama 3.1 models can be adapted towards the new domain without sacrificing significant performance on general domain tasks. We also explore the possibility of merging the adapted model and the base model for a better control of the performance trade-off between domains.
LiLiuM: eBay's Large Language Models for e-commerce
Jun 17, 2024



We introduce the LiLiuM series of large language models (LLMs): 1B, 7B, and 13B parameter models developed 100% in-house to fit eBay's specific needs in the e-commerce domain. This gives eBay full control over all aspects of the models including license, data, vocabulary, and architecture. We expect these models to be used as a foundation for fine-tuning and instruction-tuning, eliminating dependencies to external models. The LiLiuM LLMs have been trained on 3 trillion tokens of multilingual text from general and e-commerce domain. They perform similar to the popular LLaMA-2 models on English natural language understanding (NLU) benchmarks. At the same time, we outperform LLaMA-2 on non-English NLU tasks, machine translation and on e-commerce specific downstream tasks. As part of our data mixture, we utilize the newly released RedPajama-V2 dataset for training and share our insights regarding data filtering and deduplication. We also discuss in detail how to serialize structured data for use in autoregressive language modeling. We provide insights on the effects of including code and parallel machine translation data in pre-training. Furthermore, we develop our own tokenizer and model vocabulary, customized towards e-commerce. This way, we can achieve up to 34% speed-up in text generation on eBay-specific downstream tasks compared to LLaMA-2. Finally, in relation to LLM pretraining, we show that checkpoint averaging can further improve over the best individual model checkpoint.
Document-Level Language Models for Machine Translation
Oct 18, 2023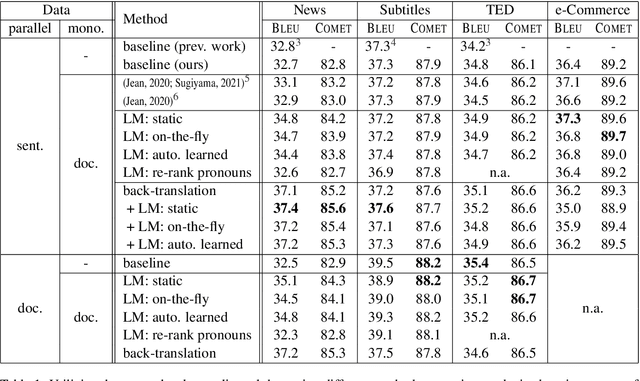
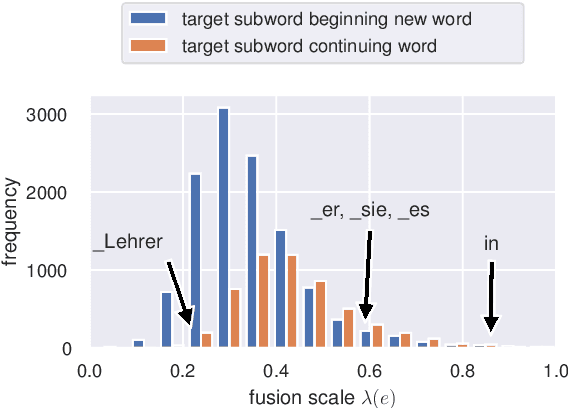
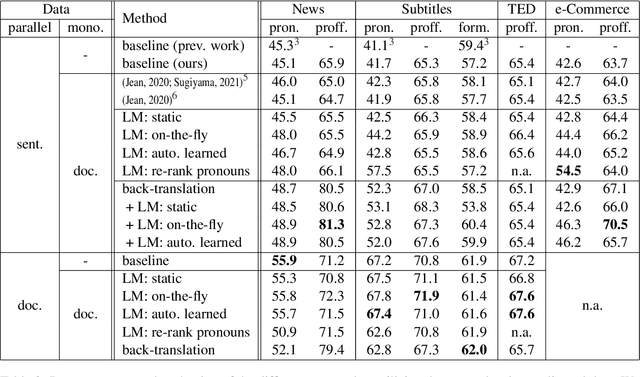
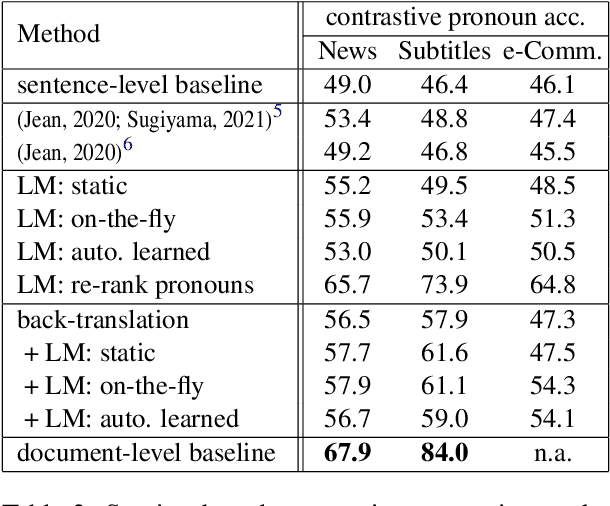
Despite the known limitations, most machine translation systems today still operate on the sentence-level. One reason for this is, that most parallel training data is only sentence-level aligned, without document-level meta information available. In this work, we set out to build context-aware translation systems utilizing document-level monolingual data instead. This can be achieved by combining any existing sentence-level translation model with a document-level language model. We improve existing approaches by leveraging recent advancements in model combination. Additionally, we propose novel weighting techniques that make the system combination more flexible and significantly reduce computational overhead. In a comprehensive evaluation on four diverse translation tasks, we show that our extensions improve document-targeted scores substantially and are also computationally more efficient. However, we also find that in most scenarios, back-translation gives even better results, at the cost of having to re-train the translation system. Finally, we explore language model fusion in the light of recent advancements in large language models. Our findings suggest that there might be strong potential in utilizing large language models via model combination.
Towards Reinforcement Learning for Pivot-based Neural Machine Translation with Non-autoregressive Transformer
Sep 27, 2021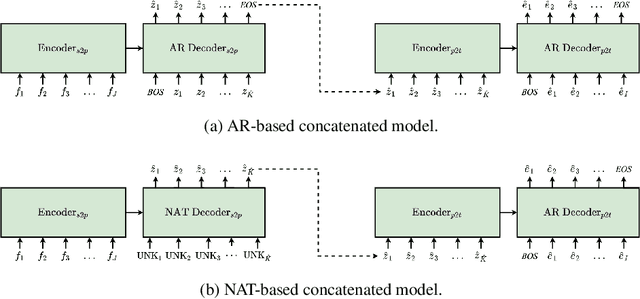
Pivot-based neural machine translation (NMT) is commonly used in low-resource setups, especially for translation between non-English language pairs. It benefits from using high resource source-pivot and pivot-target language pairs and an individual system is trained for both sub-tasks. However, these models have no connection during training, and the source-pivot model is not optimized to produce the best translation for the source-target task. In this work, we propose to train a pivot-based NMT system with the reinforcement learning (RL) approach, which has been investigated for various text generation tasks, including machine translation (MT). We utilize a non-autoregressive transformer and present an end-to-end pivot-based integrated model, enabling training on source-target data.
Integrated Training for Sequence-to-Sequence Models Using Non-Autoregressive Transformer
Sep 27, 2021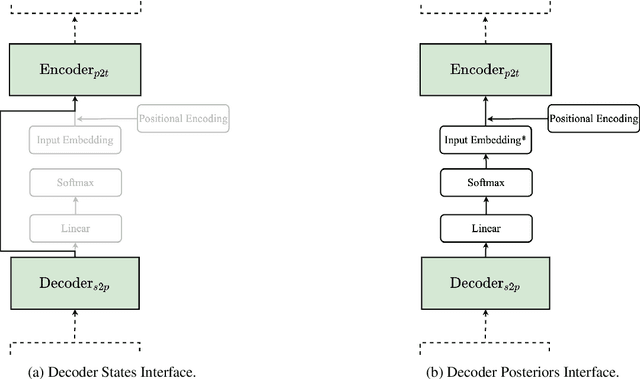
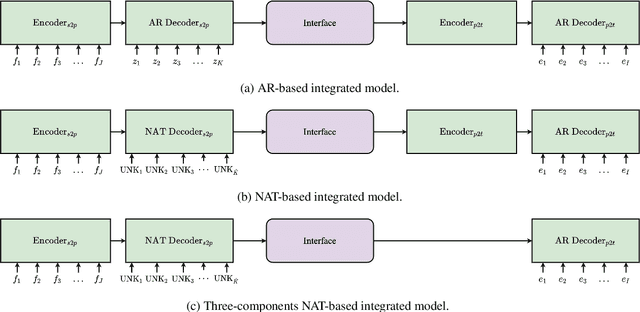
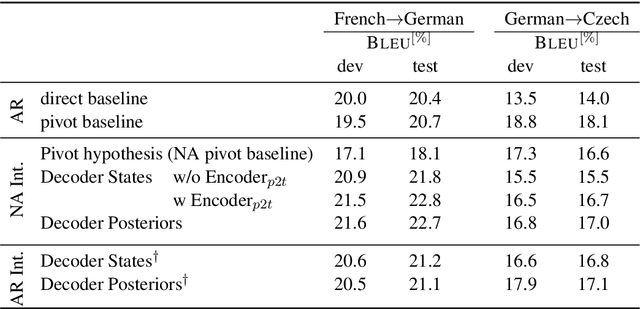
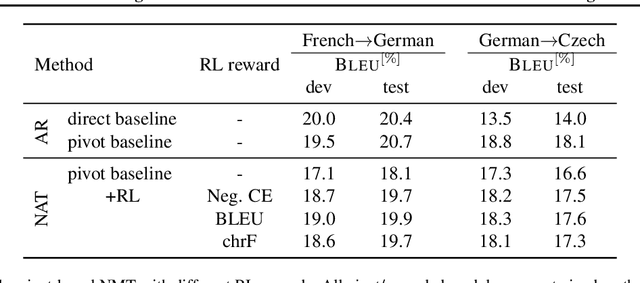
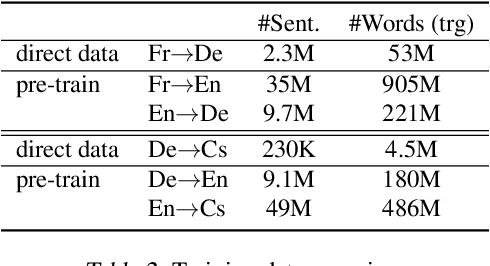
Complex natural language applications such as speech translation or pivot translation traditionally rely on cascaded models. However, cascaded models are known to be prone to error propagation and model discrepancy problems. Furthermore, there is no possibility of using end-to-end training data in conventional cascaded systems, meaning that the training data most suited for the task cannot be used. Previous studies suggested several approaches for integrated end-to-end training to overcome those problems, however they mostly rely on (synthetic or natural) three-way data. We propose a cascaded model based on the non-autoregressive Transformer that enables end-to-end training without the need for an explicit intermediate representation. This new architecture (i) avoids unnecessary early decisions that can cause errors which are then propagated throughout the cascaded models and (ii) utilizes the end-to-end training data directly. We conduct an evaluation on two pivot-based machine translation tasks, namely French-German and German-Czech. Our experimental results show that the proposed architecture yields an improvement of more than 2 BLEU for French-German over the cascaded baseline.
Pivot-based Transfer Learning for Neural Machine Translation between Non-English Languages
Sep 20, 2019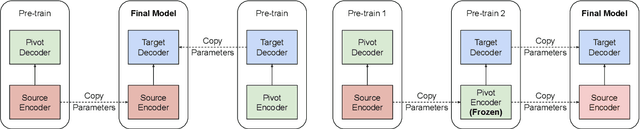
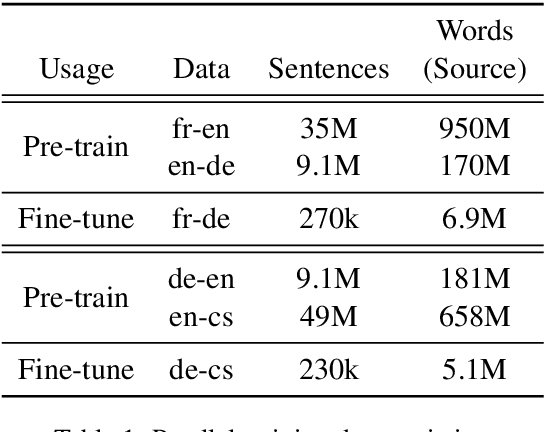
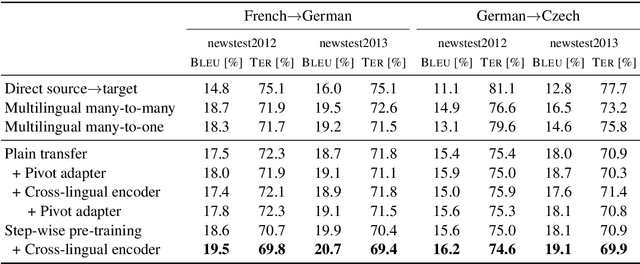
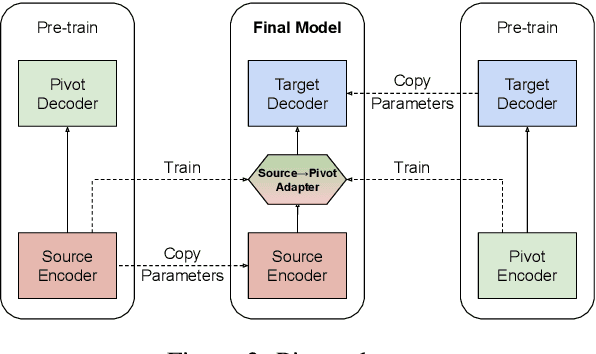
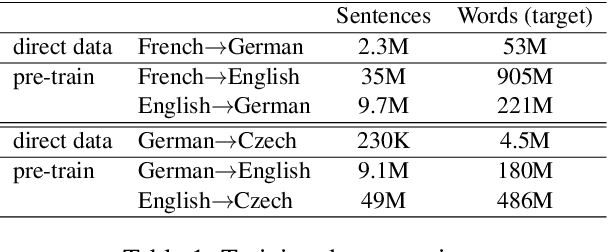
We present effective pre-training strategies for neural machine translation (NMT) using parallel corpora involving a pivot language, i.e., source-pivot and pivot-target, leading to a significant improvement in source-target translation. We propose three methods to increase the relation among source, pivot, and target languages in the pre-training: 1) step-wise training of a single model for different language pairs, 2) additional adapter component to smoothly connect pre-trained encoder and decoder, and 3) cross-lingual encoder training via autoencoding of the pivot language. Our methods greatly outperform multilingual models up to +2.6% BLEU in WMT 2019 French-German and German-Czech tasks. We show that our improvements are valid also in zero-shot/zero-resource scenarios.
Word-based Domain Adaptation for Neural Machine Translation
Jun 07, 2019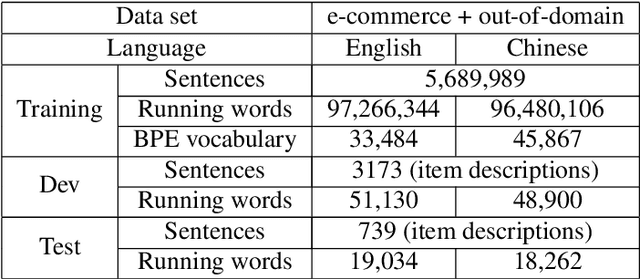
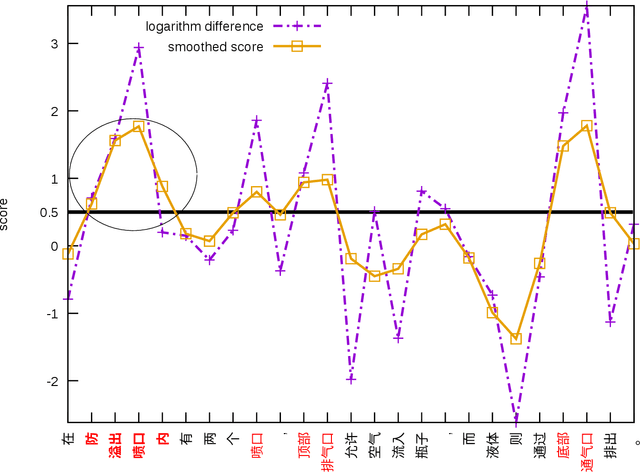
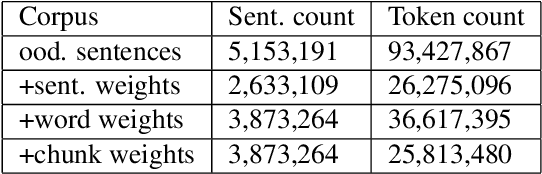
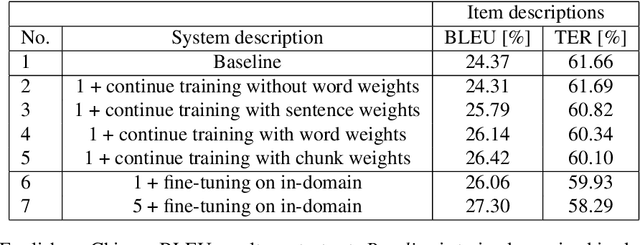
In this paper, we empirically investigate applying word-level weights to adapt neural machine translation to e-commerce domains, where small e-commerce datasets and large out-of-domain datasets are available. In order to mine in-domain like words in the out-of-domain datasets, we compute word weights by using a domain-specific and a non-domain-specific language model followed by smoothing and binary quantization. The baseline model is trained on mixed in-domain and out-of-domain datasets. Experimental results on English to Chinese e-commerce domain translation show that compared to continuing training without word weights, it improves MT quality by up to 2.11% BLEU absolute and 1.59% TER. We have also trained models using fine-tuning on the in-domain data. Pre-training a model with word weights improves fine-tuning up to 1.24% BLEU absolute and 1.64% TER, respectively.
* Published on the proceedings of the International Workshop on Spoken Language Translation (IWSLT), 2018
Learning from Chunk-based Feedback in Neural Machine Translation
Jun 19, 2018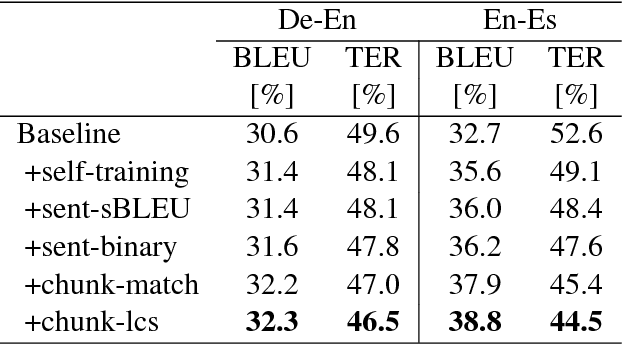
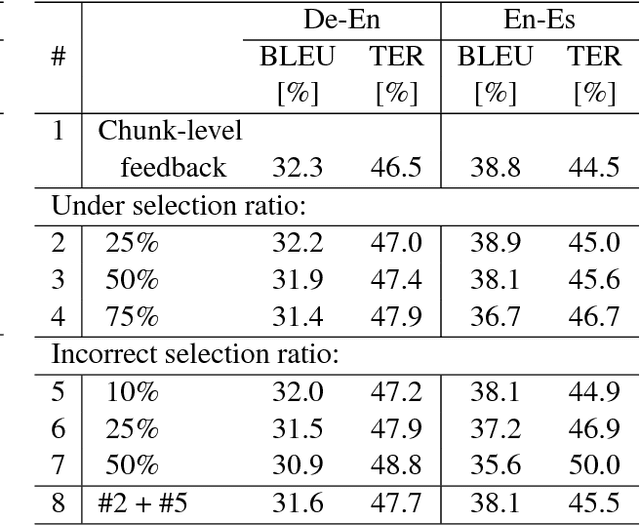
We empirically investigate learning from partial feedback in neural machine translation (NMT), when partial feedback is collected by asking users to highlight a correct chunk of a translation. We propose a simple and effective way of utilizing such feedback in NMT training. We demonstrate how the common machine translation problem of domain mismatch between training and deployment can be reduced solely based on chunk-level user feedback. We conduct a series of simulation experiments to test the effectiveness of the proposed method. Our results show that chunk-level feedback outperforms sentence based feedback by up to 2.61% BLEU absolute.
Neural Machine Translation Leveraging Phrase-based Models in a Hybrid Search
Aug 10, 2017
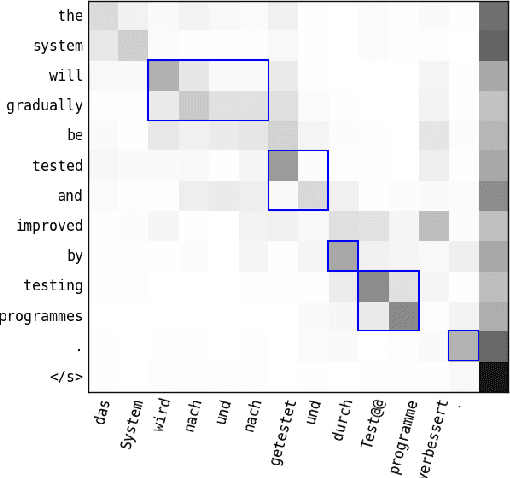
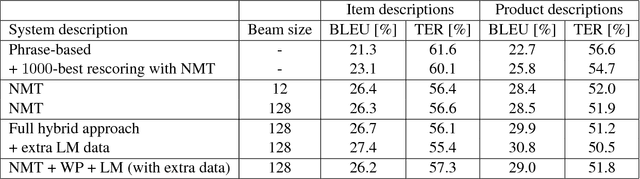
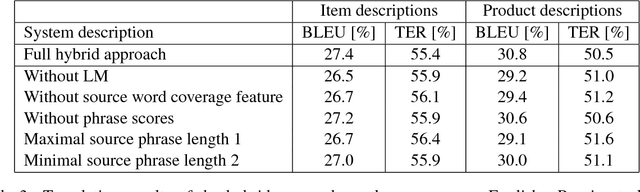
In this paper, we introduce a hybrid search for attention-based neural machine translation (NMT). A target phrase learned with statistical MT models extends a hypothesis in the NMT beam search when the attention of the NMT model focuses on the source words translated by this phrase. Phrases added in this way are scored with the NMT model, but also with SMT features including phrase-level translation probabilities and a target language model. Experimental results on German->English news domain and English->Russian e-commerce domain translation tasks show that using phrase-based models in NMT search improves MT quality by up to 2.3% BLEU absolute as compared to a strong NMT baseline.