 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeITEm: Unsupervised Image-Text Embedding Learning for eCommerce
Oct 22, 2023



Product embedding serves as a cornerstone for a wide range of applications in eCommerce. The product embedding learned from multiple modalities shows significant improvement over that from a single modality, since different modalities provide complementary information. However, some modalities are more informatively dominant than others. How to teach a model to learn embedding from different modalities without neglecting information from the less dominant modality is challenging. We present an image-text embedding model (ITEm), an unsupervised learning method that is designed to better attend to image and text modalities. We extend BERT by (1) learning an embedding from text and image without knowing the regions of interest; (2) training a global representation to predict masked words and to construct masked image patches without their individual representations. We evaluate the pre-trained ITEm on two tasks: the search for extremely similar products and the prediction of product categories, showing substantial gains compared to strong baseline models.
Multi-armed bandits for online optimization of language model pre-training: the use case of dynamic masking
Mar 24, 2022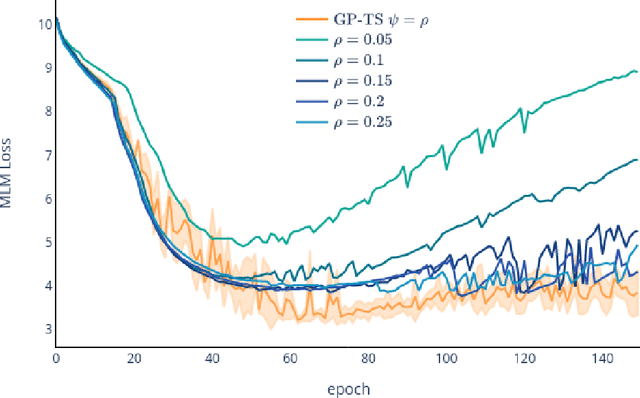
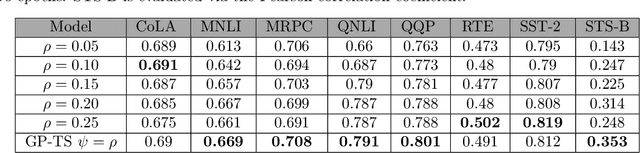
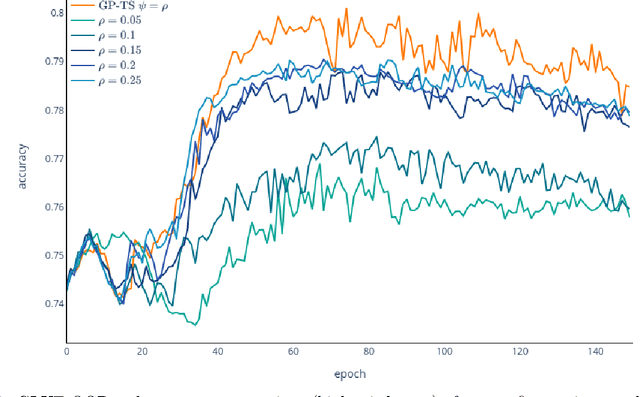

Transformer-based language models (TLMs) provide state-of-the-art performance in many modern natural language processing applications. TLM training is conducted in two phases. First, the model is pre-trained over large volumes of text to minimize a generic objective function, such as the Masked Language Model (MLM). Second, the model is fine-tuned in specific downstream tasks. Pre-training requires large volumes of data and high computational resources, while introducing many still unresolved design choices. For instance, selecting hyperparameters for language model pre-training is often carried out based on heuristics or grid-based searches. In this work, we propose a multi-armed bandit-based online optimization framework for the sequential selection of pre-training hyperparameters to optimize language model performance. We pose the pre-training procedure as a sequential decision-making task, where at each pre-training step, an agent must determine what hyperparameters to use towards optimizing the pre-training objective. We propose a Thompson sampling bandit algorithm, based on a surrogate Gaussian process reward model of the MLM pre-training objective, for its sequential minimization. We empirically show how the proposed Gaussian process based Thompson sampling pre-trains robust and well-performing language models. Namely, by sequentially selecting masking hyperparameters of the TLM, we achieve satisfactory performance in less epochs, not only in terms of the pre-training MLM objective, but in diverse downstream fine-tuning tasks. The proposed bandit-based technique provides an automated hyperparameter selection method for pre-training TLMs of interest to practitioners. In addition, our results indicate that, instead of MLM pre-training with fixed masking probabilities, sequentially adapting the masking hyperparameters improves both pre-training loss and downstream task metrics.
Towards Reinforcement Learning for Pivot-based Neural Machine Translation with Non-autoregressive Transformer
Sep 27, 2021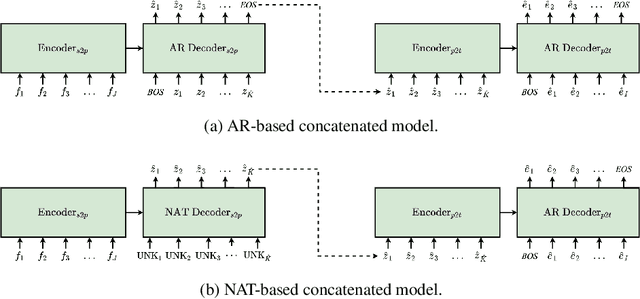
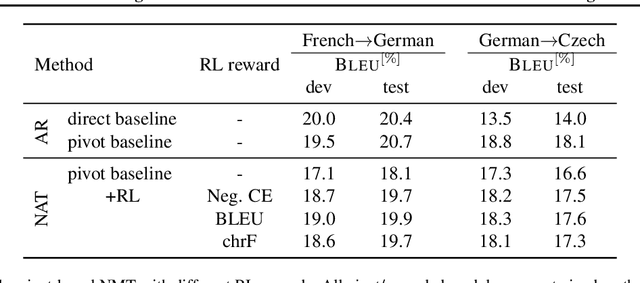
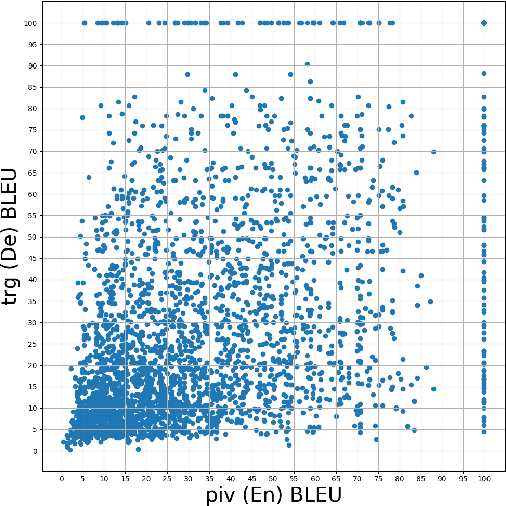
Pivot-based neural machine translation (NMT) is commonly used in low-resource setups, especially for translation between non-English language pairs. It benefits from using high resource source-pivot and pivot-target language pairs and an individual system is trained for both sub-tasks. However, these models have no connection during training, and the source-pivot model is not optimized to produce the best translation for the source-target task. In this work, we propose to train a pivot-based NMT system with the reinforcement learning (RL) approach, which has been investigated for various text generation tasks, including machine translation (MT). We utilize a non-autoregressive transformer and present an end-to-end pivot-based integrated model, enabling training on source-target data.
Integrated Training for Sequence-to-Sequence Models Using Non-Autoregressive Transformer
Sep 27, 2021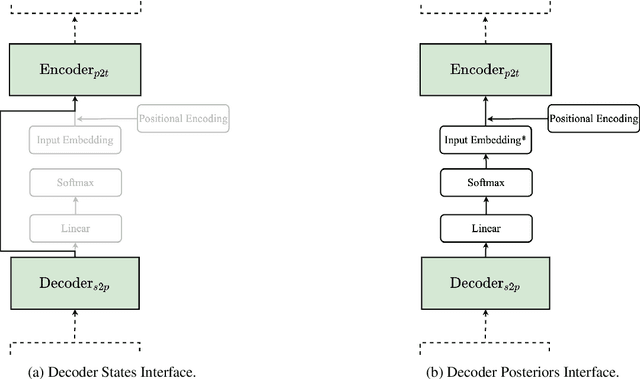
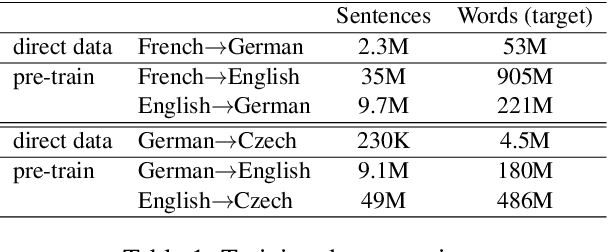
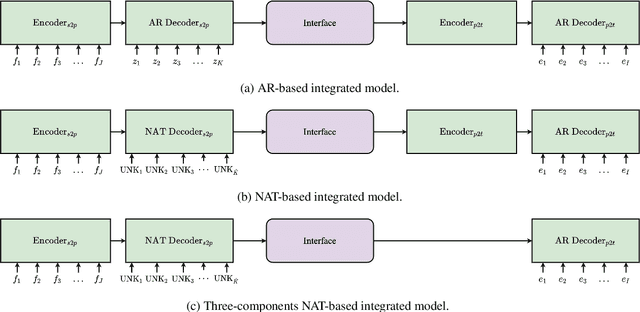
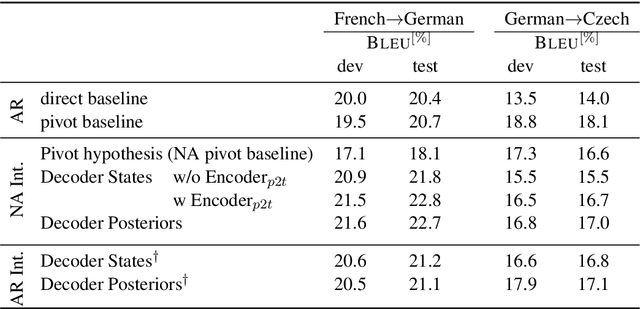
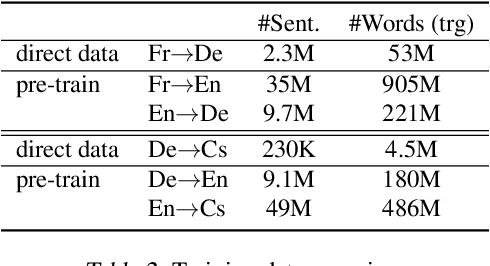
Complex natural language applications such as speech translation or pivot translation traditionally rely on cascaded models. However, cascaded models are known to be prone to error propagation and model discrepancy problems. Furthermore, there is no possibility of using end-to-end training data in conventional cascaded systems, meaning that the training data most suited for the task cannot be used. Previous studies suggested several approaches for integrated end-to-end training to overcome those problems, however they mostly rely on (synthetic or natural) three-way data. We propose a cascaded model based on the non-autoregressive Transformer that enables end-to-end training without the need for an explicit intermediate representation. This new architecture (i) avoids unnecessary early decisions that can cause errors which are then propagated throughout the cascaded models and (ii) utilizes the end-to-end training data directly. We conduct an evaluation on two pivot-based machine translation tasks, namely French-German and German-Czech. Our experimental results show that the proposed architecture yields an improvement of more than 2 BLEU for French-German over the cascaded baseline.
Deploying a BERT-based Query-Title Relevance Classifier in a Production System: a View from the Trenches
Aug 23, 2021
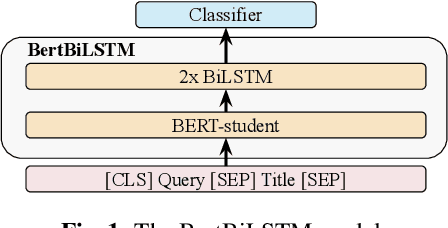

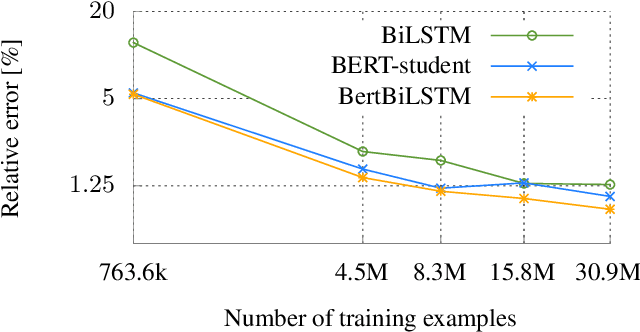
The Bidirectional Encoder Representations from Transformers (BERT) model has been radically improving the performance of many Natural Language Processing (NLP) tasks such as Text Classification and Named Entity Recognition (NER) applications. However, it is challenging to scale BERT for low-latency and high-throughput industrial use cases due to its enormous size. We successfully optimize a Query-Title Relevance (QTR) classifier for deployment via a compact model, which we name BERT Bidirectional Long Short-Term Memory (BertBiLSTM). The model is capable of inferring an input in at most 0.2ms on CPU. BertBiLSTM exceeds the off-the-shelf BERT model's performance in terms of accuracy and efficiency for the aforementioned real-world production task. We achieve this result in two phases. First, we create a pre-trained model, called eBERT, which is the original BERT architecture trained with our unique item title corpus. We then fine-tune eBERT for the QTR task. Second, we train the BertBiLSTM model to mimic the eBERT model's performance through a process called Knowledge Distillation (KD) and show the effect of data augmentation to achieve the resembling goal. Experimental results show that the proposed model outperforms other compact and production-ready models.
Automatic and Simultaneous Adjustment of Learning Rate and Momentum for Stochastic Gradient Descent
Aug 20, 2019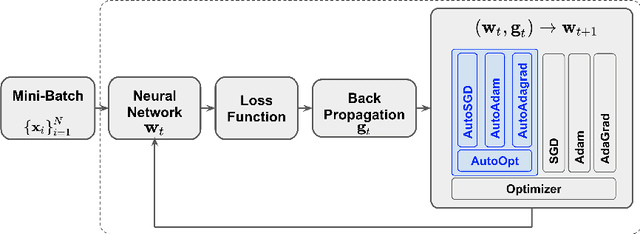

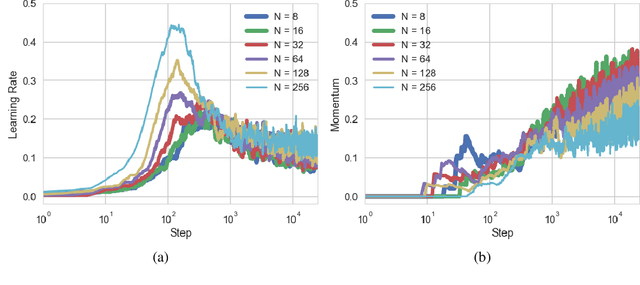

Stochastic Gradient Descent (SGD) methods are prominent for training machine learning and deep learning models. The performance of these techniques depends on their hyperparameter tuning over time and varies for different models and problems. Manual adjustment of hyperparameters is very costly and time-consuming, and even if done correctly, it lacks theoretical justification which inevitably leads to "rule of thumb" settings. In this paper, we propose a generic approach that utilizes the statistics of an unbiased gradient estimator to automatically and simultaneously adjust two paramount hyperparameters: the learning rate and momentum. We deploy the proposed general technique for various SGD methods to train Convolutional Neural Networks (CNN's). The results match the performance of the best settings obtained through an exhaustive search and therefore, removes the need for a tedious manual tuning.