 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeploying a BERT-based Query-Title Relevance Classifier in a Production System: a View from the Trenches
Aug 23, 2021
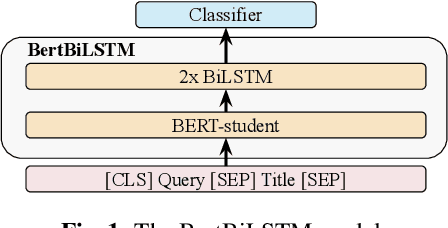

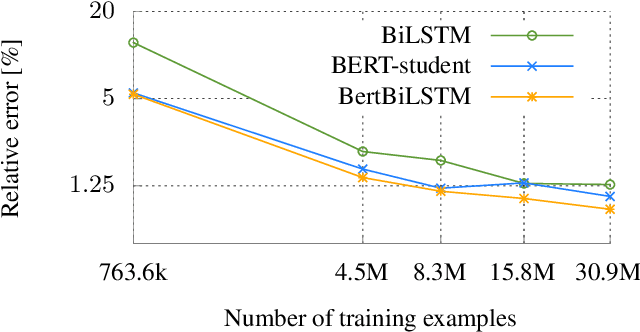
The Bidirectional Encoder Representations from Transformers (BERT) model has been radically improving the performance of many Natural Language Processing (NLP) tasks such as Text Classification and Named Entity Recognition (NER) applications. However, it is challenging to scale BERT for low-latency and high-throughput industrial use cases due to its enormous size. We successfully optimize a Query-Title Relevance (QTR) classifier for deployment via a compact model, which we name BERT Bidirectional Long Short-Term Memory (BertBiLSTM). The model is capable of inferring an input in at most 0.2ms on CPU. BertBiLSTM exceeds the off-the-shelf BERT model's performance in terms of accuracy and efficiency for the aforementioned real-world production task. We achieve this result in two phases. First, we create a pre-trained model, called eBERT, which is the original BERT architecture trained with our unique item title corpus. We then fine-tune eBERT for the QTR task. Second, we train the BertBiLSTM model to mimic the eBERT model's performance through a process called Knowledge Distillation (KD) and show the effect of data augmentation to achieve the resembling goal. Experimental results show that the proposed model outperforms other compact and production-ready models.
Diving Deep into Context-Aware Neural Machine Translation
Oct 19, 2020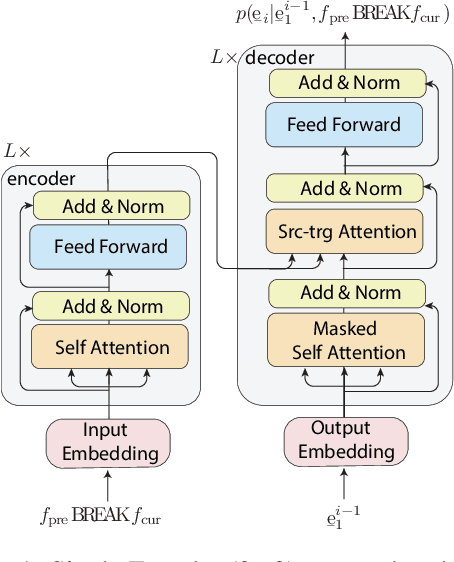

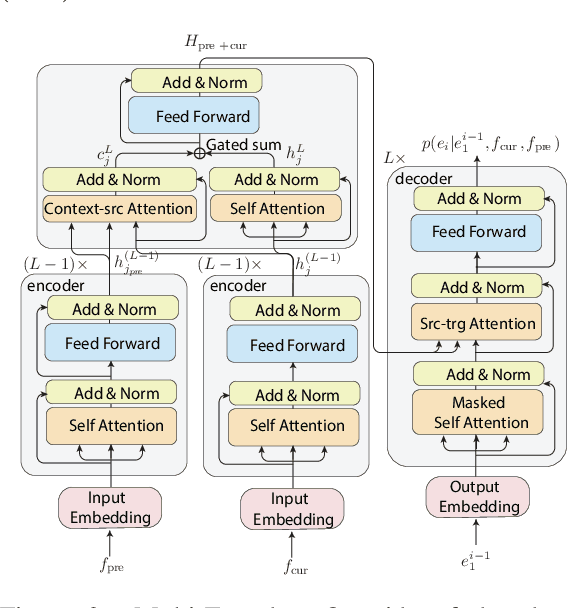
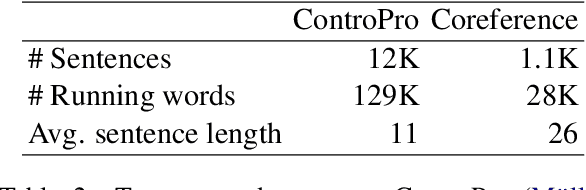
Context-aware neural machine translation (NMT) is a promising direction to improve the translation quality by making use of the additional context, e.g., document-level translation, or having meta-information. Although there exist various architectures and analyses, the effectiveness of different context-aware NMT models is not well explored yet. This paper analyzes the performance of document-level NMT models on four diverse domains with a varied amount of parallel document-level bilingual data. We conduct a comprehensive set of experiments to investigate the impact of document-level NMT. We find that there is no single best approach to document-level NMT, but rather that different architectures come out on top on different tasks. Looking at task-specific problems, such as pronoun resolution or headline translation, we find improvements in the context-aware systems, even in cases where the corpus-level metrics like BLEU show no significant improvement. We also show that document-level back-translation significantly helps to compensate for the lack of document-level bi-texts.
Word-based Domain Adaptation for Neural Machine Translation
Jun 07, 2019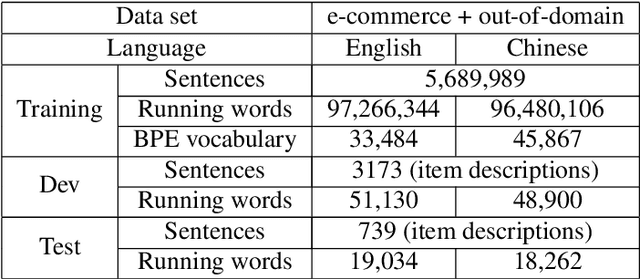
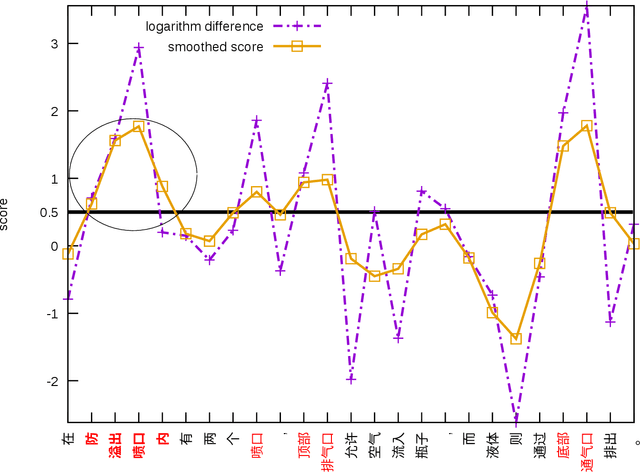
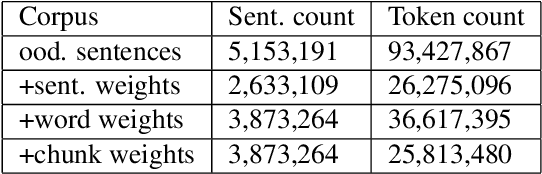
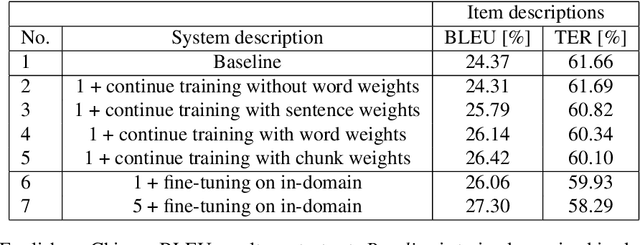
In this paper, we empirically investigate applying word-level weights to adapt neural machine translation to e-commerce domains, where small e-commerce datasets and large out-of-domain datasets are available. In order to mine in-domain like words in the out-of-domain datasets, we compute word weights by using a domain-specific and a non-domain-specific language model followed by smoothing and binary quantization. The baseline model is trained on mixed in-domain and out-of-domain datasets. Experimental results on English to Chinese e-commerce domain translation show that compared to continuing training without word weights, it improves MT quality by up to 2.11% BLEU absolute and 1.59% TER. We have also trained models using fine-tuning on the in-domain data. Pre-training a model with word weights improves fine-tuning up to 1.24% BLEU absolute and 1.64% TER, respectively.
* Published on the proceedings of the International Workshop on Spoken Language Translation (IWSLT), 2018
Neural Machine Translation Leveraging Phrase-based Models in a Hybrid Search
Aug 10, 2017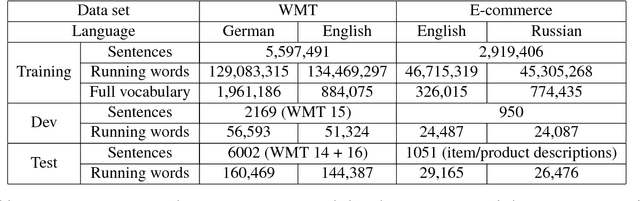
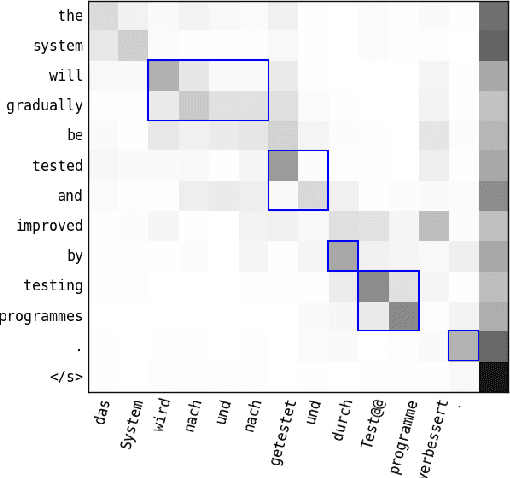
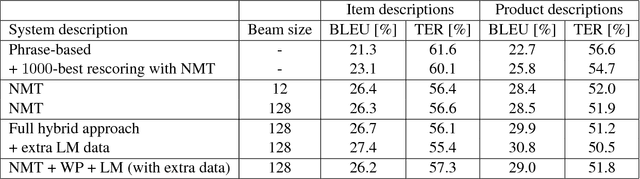
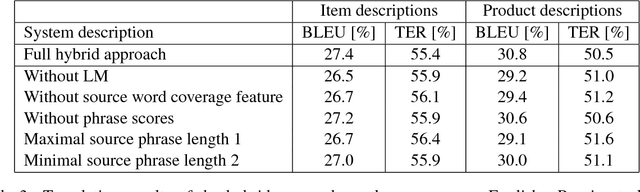
In this paper, we introduce a hybrid search for attention-based neural machine translation (NMT). A target phrase learned with statistical MT models extends a hypothesis in the NMT beam search when the attention of the NMT model focuses on the source words translated by this phrase. Phrases added in this way are scored with the NMT model, but also with SMT features including phrase-level translation probabilities and a target language model. Experimental results on German->English news domain and English->Russian e-commerce domain translation tasks show that using phrase-based models in NMT search improves MT quality by up to 2.3% BLEU absolute as compared to a strong NMT baseline.
Neural and Statistical Methods for Leveraging Meta-information in Machine Translation
Aug 10, 2017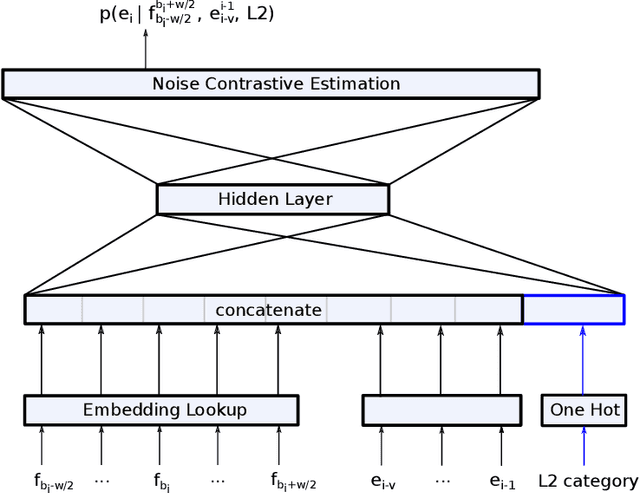
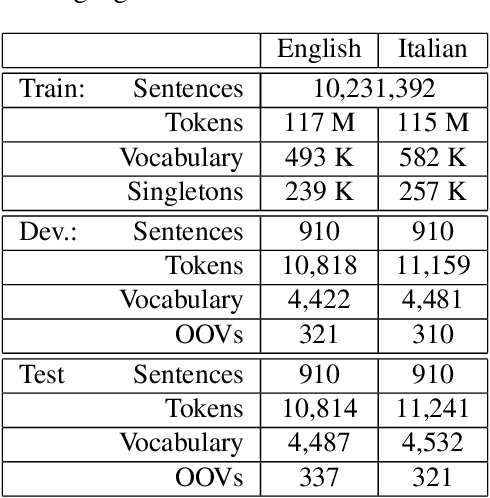
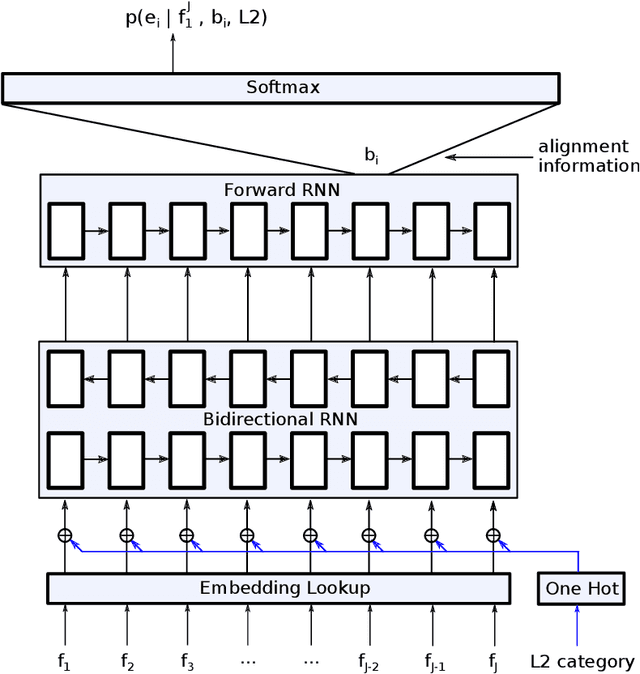
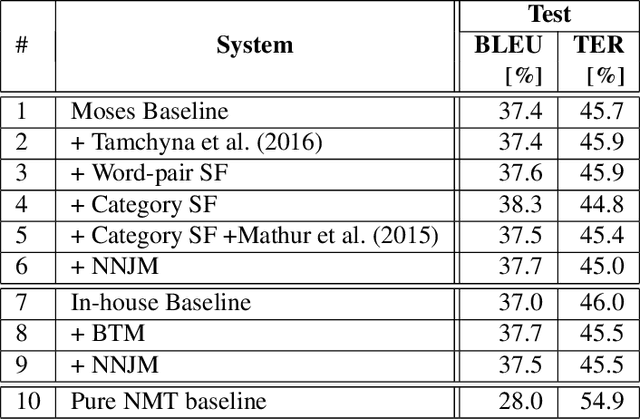
In this paper, we discuss different methods which use meta information and richer context that may accompany source language input to improve machine translation quality. We focus on category information of input text as meta information, but the proposed methods can be extended to all textual and non-textual meta information that might be available for the input text or automatically predicted using the text content. The main novelty of this work is to use state-of-the-art neural network methods to tackle this problem within a statistical machine translation (SMT) framework. We observe translation quality improvements up to 3% in terms of BLEU score in some text categories.