 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAntCritic: Argument Mining for Free-Form and Visually-Rich Financial Comments
Aug 20, 2022

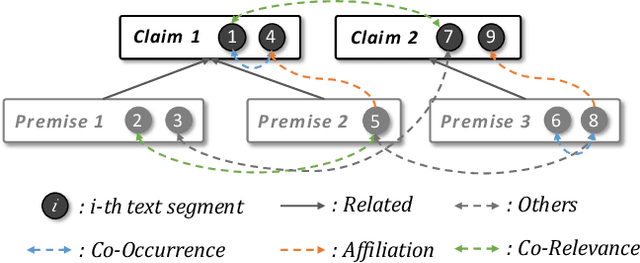

The task of argument mining aims to detect all possible argumentative components and identify their relationships automatically. As a thriving field in natural language processing, there has been a large amount of corpus for academic study and application development in argument mining. However, the research in this area is still constrained by the inherent limitations of existing datasets. Specifically, all the publicly available datasets are relatively small in scale, and few of them provide information from other modalities to facilitate the learning process. Moreover, the statements and expressions in these corpora are usually in a compact form, which means non-adjacent clauses or text segments will always be regarded as multiple individual components, thus restricting the generalization ability of models. To this end, we collect and contribute a novel dataset AntCritic to serve as a helpful complement to this area, which consists of about 10k free-form and visually-rich financial comments and supports both argument component detection and argument relation prediction tasks. Besides, in order to cope with the challenges and difficulties brought by scenario expansion and problem setting modification, we thoroughly explore the fine-grained relation prediction and structure reconstruction scheme for free-form documents and discuss the encoding mechanism for visual styles and layouts. And based on these analyses, we design two simple but effective model architectures and conduct various experiments on this dataset to provide benchmark performances as a reference and verify the practicability of our proposed architecture.
Diving Deep into Context-Aware Neural Machine Translation
Oct 19, 2020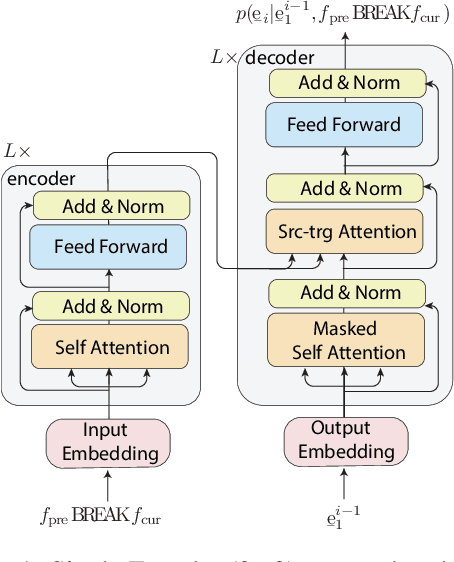

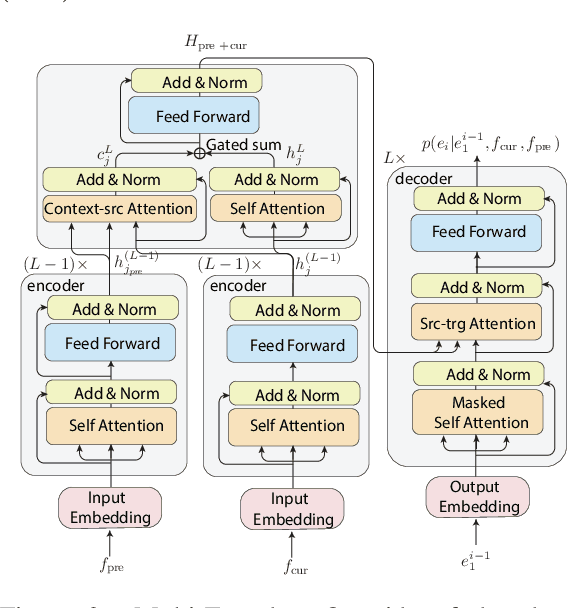
Context-aware neural machine translation (NMT) is a promising direction to improve the translation quality by making use of the additional context, e.g., document-level translation, or having meta-information. Although there exist various architectures and analyses, the effectiveness of different context-aware NMT models is not well explored yet. This paper analyzes the performance of document-level NMT models on four diverse domains with a varied amount of parallel document-level bilingual data. We conduct a comprehensive set of experiments to investigate the impact of document-level NMT. We find that there is no single best approach to document-level NMT, but rather that different architectures come out on top on different tasks. Looking at task-specific problems, such as pronoun resolution or headline translation, we find improvements in the context-aware systems, even in cases where the corpus-level metrics like BLEU show no significant improvement. We also show that document-level back-translation significantly helps to compensate for the lack of document-level bi-texts.
Investigation of Large-Margin Softmax in Neural Language Modeling
May 20, 2020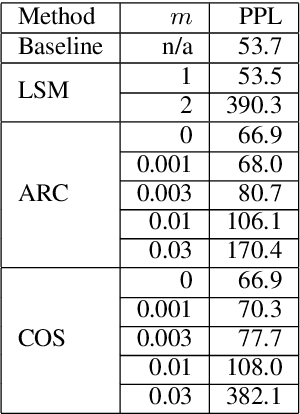
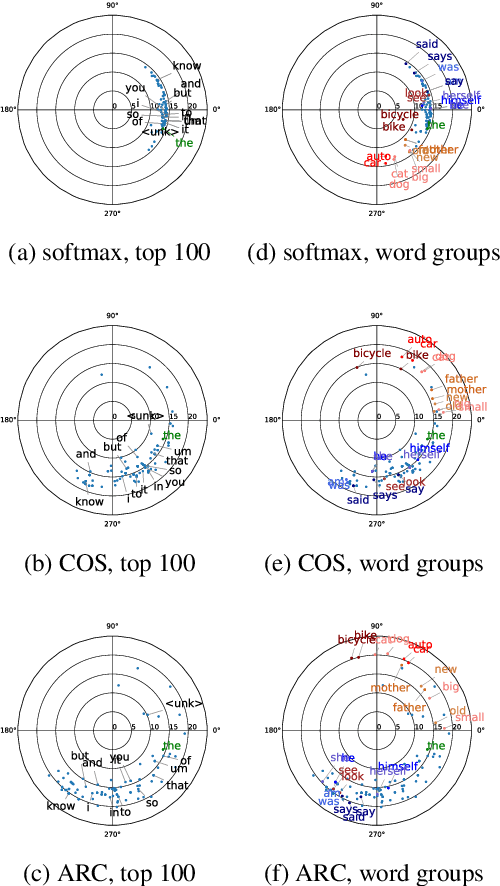
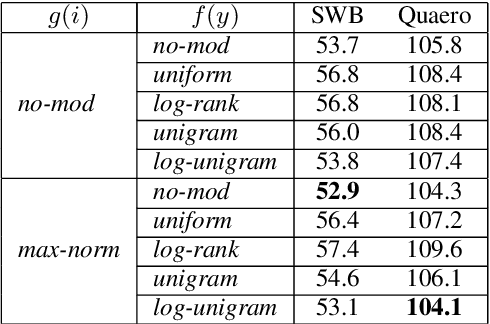
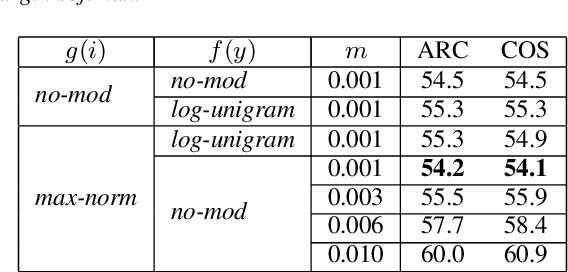
To encourage intra-class compactness and inter-class separability among trainable feature vectors, large-margin softmax methods are developed and widely applied in the face recognition community. The introduction of the large-margin concept into the softmax is reported to have good properties such as enhanced discriminative power, less overfitting and well-defined geometric intuitions. Nowadays, language modeling is commonly approached with neural networks using softmax and cross entropy. In this work, we are curious to see if introducing large-margins to neural language models would improve the perplexity and consequently word error rate in automatic speech recognition. Specifically, we first implement and test various types of conventional margins following the previous works in face recognition. To address the distribution of natural language data, we then compare different strategies for word vector norm-scaling. After that, we apply the best norm-scaling setup in combination with various margins and conduct neural language models rescoring experiments in automatic speech recognition. We find that although perplexity is slightly deteriorated, neural language models with large-margin softmax can yield word error rate similar to that of the standard softmax baseline. Finally, expected margins are analyzed through visualization of word vectors, showing that the syntactic and semantic relationships are also preserved.