 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFindings of the IWSLT 2024 Evaluation Campaign
Nov 07, 2024This paper reports on the shared tasks organized by the 21st IWSLT Conference. The shared tasks address 7 scientific challenges in spoken language translation: simultaneous and offline translation, automatic subtitling and dubbing, speech-to-speech translation, dialect and low-resource speech translation, and Indic languages. The shared tasks attracted 18 teams whose submissions are documented in 26 system papers. The growing interest towards spoken language translation is also witnessed by the constantly increasing number of shared task organizers and contributors to the overview paper, almost evenly distributed across industry and academia.
AppTek's Submission to the IWSLT 2022 Isometric Spoken Language Translation Task
May 12, 2022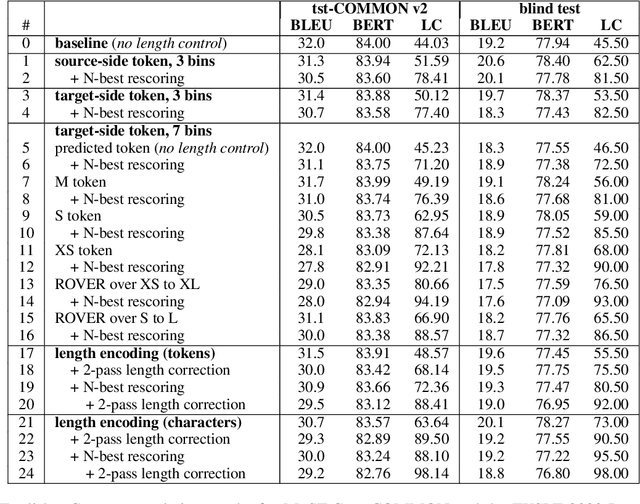
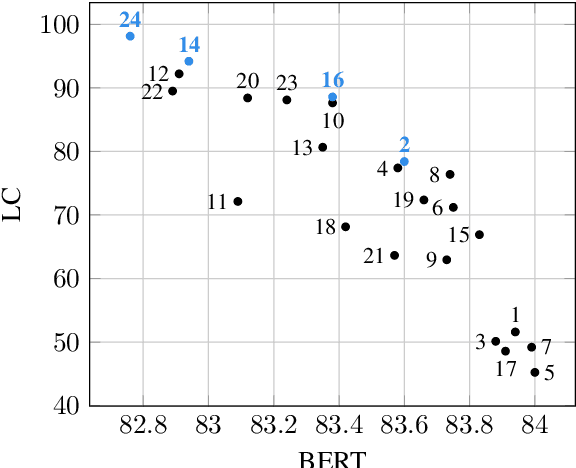
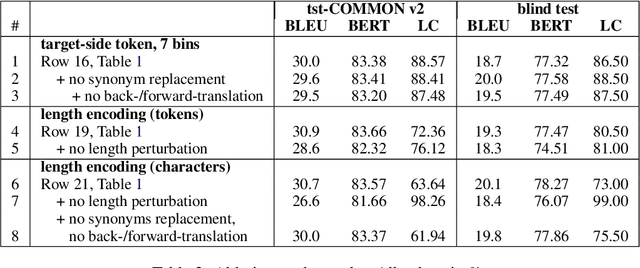
To participate in the Isometric Spoken Language Translation Task of the IWSLT 2022 evaluation, constrained condition, AppTek developed neural Transformer-based systems for English-to-German with various mechanisms of length control, ranging from source-side and target-side pseudo-tokens to encoding of remaining length in characters that replaces positional encoding. We further increased translation length compliance by sentence-level selection of length-compliant hypotheses from different system variants, as well as rescoring of N-best candidates from a single system. Length-compliant back-translated and forward-translated synthetic data, as well as other parallel data variants derived from the original MuST-C training corpus were important for a good quality/desired length trade-off. Our experimental results show that length compliance levels above 90% can be reached while minimizing losses in MT quality as measured in BERT and BLEU scores.
SubER: A Metric for Automatic Evaluation of Subtitle Quality
May 11, 2022



This paper addresses the problem of evaluating the quality of automatically generated subtitles, which includes not only the quality of the machine-transcribed or translated speech, but also the quality of line segmentation and subtitle timing. We propose SubER - a single novel metric based on edit distance with shifts that takes all of these subtitle properties into account. We compare it to existing metrics for evaluating transcription, translation, and subtitle quality. A careful human evaluation in a post-editing scenario shows that the new metric has a high correlation with the post-editing effort and direct human assessment scores, outperforming baseline metrics considering only the subtitle text, such as WER and BLEU, and existing methods to integrate segmentation and timing features.
Neural Simultaneous Speech Translation Using Alignment-Based Chunking
May 29, 2020
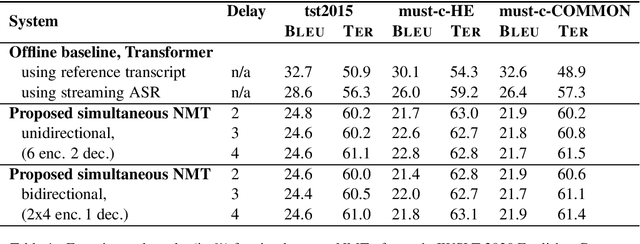
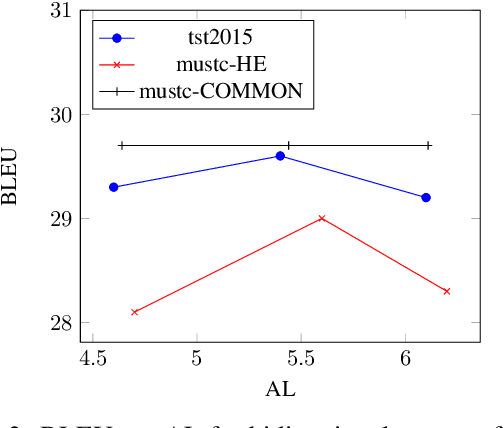
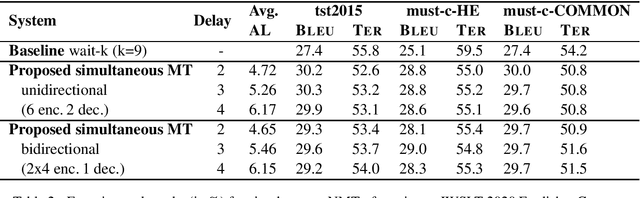
In simultaneous machine translation, the objective is to determine when to produce a partial translation given a continuous stream of source words, with a trade-off between latency and quality. We propose a neural machine translation (NMT) model that makes dynamic decisions when to continue feeding on input or generate output words. The model is composed of two main components: one to dynamically decide on ending a source chunk, and another that translates the consumed chunk. We train the components jointly and in a manner consistent with the inference conditions. To generate chunked training data, we propose a method that utilizes word alignment while also preserving enough context. We compare models with bidirectional and unidirectional encoders of different depths, both on real speech and text input. Our results on the IWSLT 2020 English-to-German task outperform a wait-k baseline by 2.6 to 3.7% BLEU absolute.
Novel Applications of Factored Neural Machine Translation
Oct 09, 2019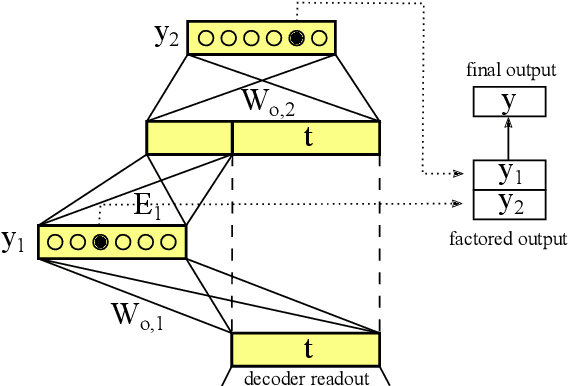
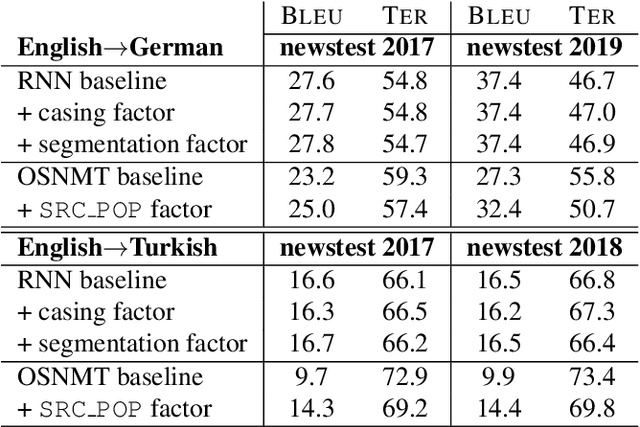


In this work, we explore the usefulness of target factors in neural machine translation (NMT) beyond their original purpose of predicting word lemmas and their inflections, as proposed by Garc\`ia-Mart\`inez et al., 2016. For this, we introduce three novel applications of the factored output architecture: In the first one, we use a factor to explicitly predict the word case separately from the target word itself. This allows for information to be shared between different casing variants of a word. In a second task, we use a factor to predict when two consecutive subwords have to be joined, eliminating the need for target subword joining markers. The third task is the prediction of special tokens of the operation sequence NMT model (OSNMT) of Stahlberg et al., 2018. Automatic evaluation on English-to-German and English-to-Turkish tasks showed that integration of such auxiliary prediction tasks into NMT is at least as good as the standard NMT approach. For the OSNMT, we observed a significant improvement in BLEU over the baseline OSNMT implementation due to a reduced output sequence length that resulted from the introduction of the target factors.
Neural and Statistical Methods for Leveraging Meta-information in Machine Translation
Aug 10, 2017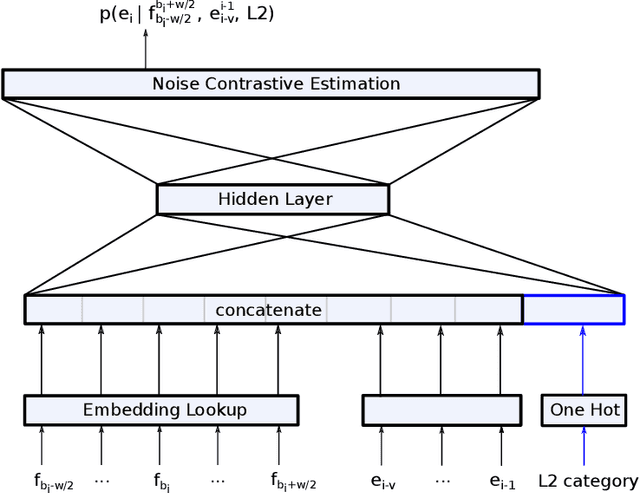
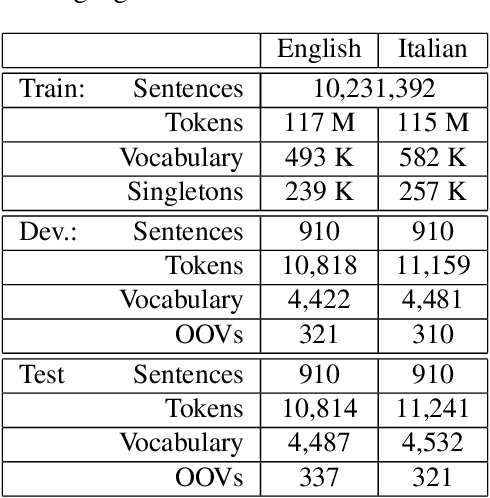
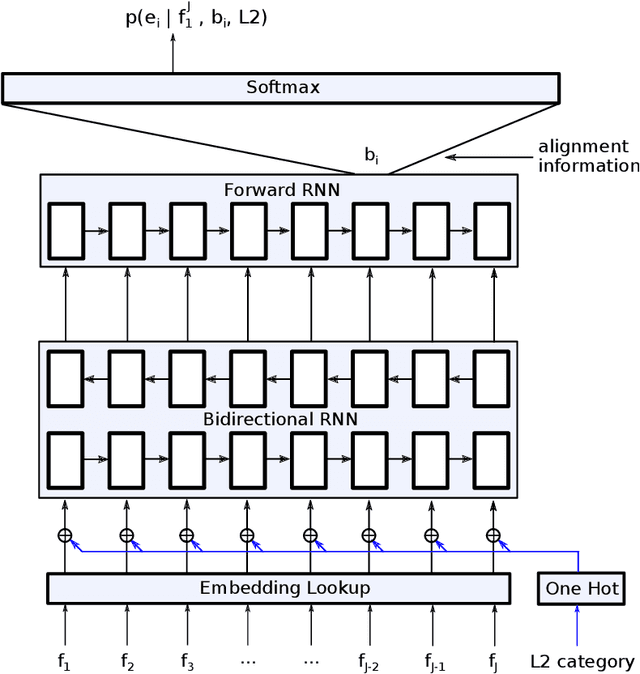
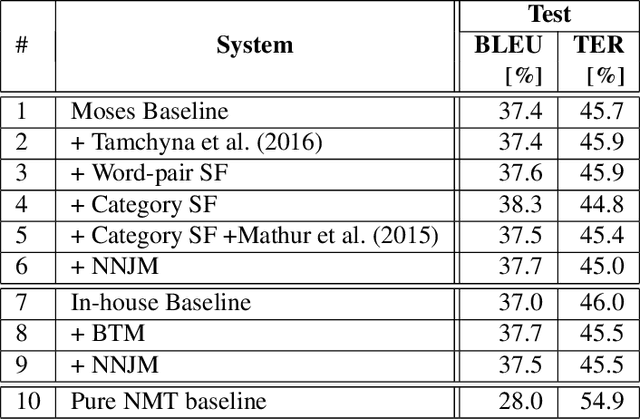
In this paper, we discuss different methods which use meta information and richer context that may accompany source language input to improve machine translation quality. We focus on category information of input text as meta information, but the proposed methods can be extended to all textual and non-textual meta information that might be available for the input text or automatically predicted using the text content. The main novelty of this work is to use state-of-the-art neural network methods to tackle this problem within a statistical machine translation (SMT) framework. We observe translation quality improvements up to 3% in terms of BLEU score in some text categories.