 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Augmentation for Maltese NLP using Transliterated and Machine Translated Arabic Data
Sep 16, 2025Maltese is a unique Semitic language that has evolved under extensive influence from Romance and Germanic languages, particularly Italian and English. Despite its Semitic roots, its orthography is based on the Latin script, creating a gap between it and its closest linguistic relatives in Arabic. In this paper, we explore whether Arabic-language resources can support Maltese natural language processing (NLP) through cross-lingual augmentation techniques. We investigate multiple strategies for aligning Arabic textual data with Maltese, including various transliteration schemes and machine translation (MT) approaches. As part of this, we also introduce novel transliteration systems that better represent Maltese orthography. We evaluate the impact of these augmentations on monolingual and mutlilingual models and demonstrate that Arabic-based augmentation can significantly benefit Maltese NLP tasks.
MELABenchv1: Benchmarking Large Language Models against Smaller Fine-Tuned Models for Low-Resource Maltese NLP
Jun 04, 2025Large Language Models (LLMs) have demonstrated remarkable performance across various Natural Language Processing (NLP) tasks, largely due to their generalisability and ability to perform tasks without additional training. However, their effectiveness for low-resource languages remains limited. In this study, we evaluate the performance of 55 publicly available LLMs on Maltese, a low-resource language, using a newly introduced benchmark covering 11 discriminative and generative tasks. Our experiments highlight that many models perform poorly, particularly on generative tasks, and that smaller fine-tuned models often perform better across all tasks. From our multidimensional analysis, we investigate various factors impacting performance. We conclude that prior exposure to Maltese during pre-training and instruction-tuning emerges as the most important factor. We also examine the trade-offs between fine-tuning and prompting, highlighting that while fine-tuning requires a higher initial cost, it yields better performance and lower inference costs. Through this work, we aim to highlight the need for more inclusive language technologies and recommend that researchers working with low-resource languages consider more "traditional" language modelling approaches.
Findings of the IWSLT 2024 Evaluation Campaign
Nov 07, 2024This paper reports on the shared tasks organized by the 21st IWSLT Conference. The shared tasks address 7 scientific challenges in spoken language translation: simultaneous and offline translation, automatic subtitling and dubbing, speech-to-speech translation, dialect and low-resource speech translation, and Indic languages. The shared tasks attracted 18 teams whose submissions are documented in 26 system papers. The growing interest towards spoken language translation is also witnessed by the constantly increasing number of shared task organizers and contributors to the overview paper, almost evenly distributed across industry and academia.
Cross-Lingual Transfer from Related Languages: Treating Low-Resource Maltese as Multilingual Code-Switching
Feb 03, 2024Although multilingual language models exhibit impressive cross-lingual transfer capabilities on unseen languages, the performance on downstream tasks is impacted when there is a script disparity with the languages used in the multilingual model's pre-training data. Using transliteration offers a straightforward yet effective means to align the script of a resource-rich language with a target language, thereby enhancing cross-lingual transfer capabilities. However, for mixed languages, this approach is suboptimal, since only a subset of the language benefits from the cross-lingual transfer while the remainder is impeded. In this work, we focus on Maltese, a Semitic language, with substantial influences from Arabic, Italian, and English, and notably written in Latin script. We present a novel dataset annotated with word-level etymology. We use this dataset to train a classifier that enables us to make informed decisions regarding the appropriate processing of each token in the Maltese language. We contrast indiscriminate transliteration or translation to mixing processing pipelines that only transliterate words of Arabic origin, thereby resulting in text with a mixture of scripts. We fine-tune the processed data on four downstream tasks and show that conditional transliteration based on word etymology yields the best results, surpassing fine-tuning with raw Maltese or Maltese processed with non-selective pipelines.
Pre-training Data Quality and Quantity for a Low-Resource Language: New Corpus and BERT Models for Maltese
May 26, 2022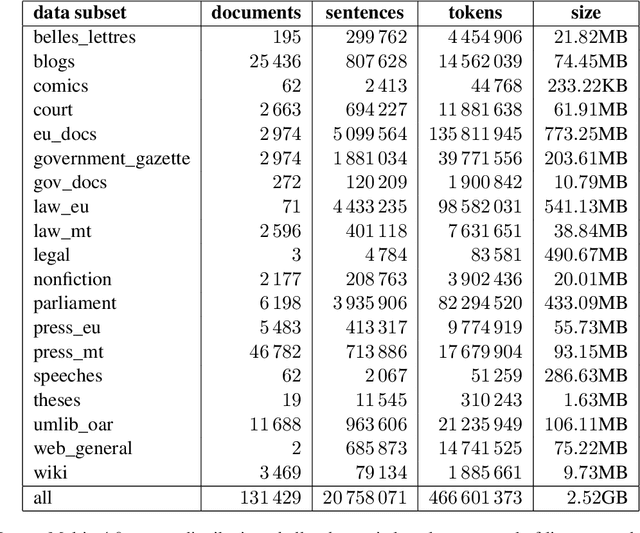
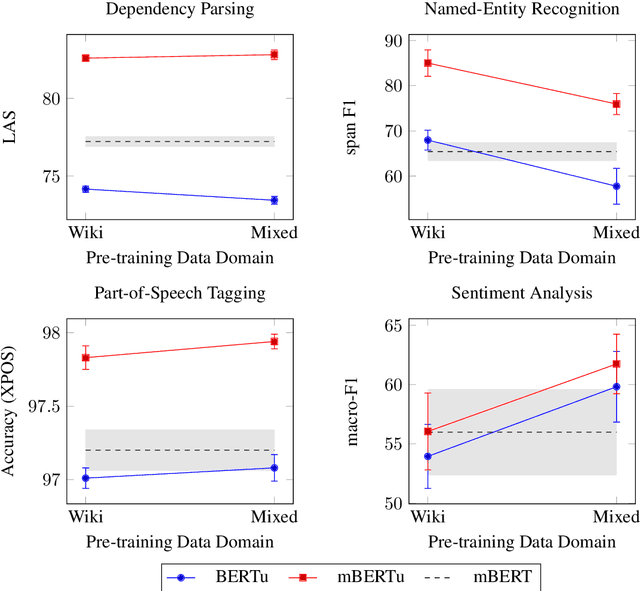
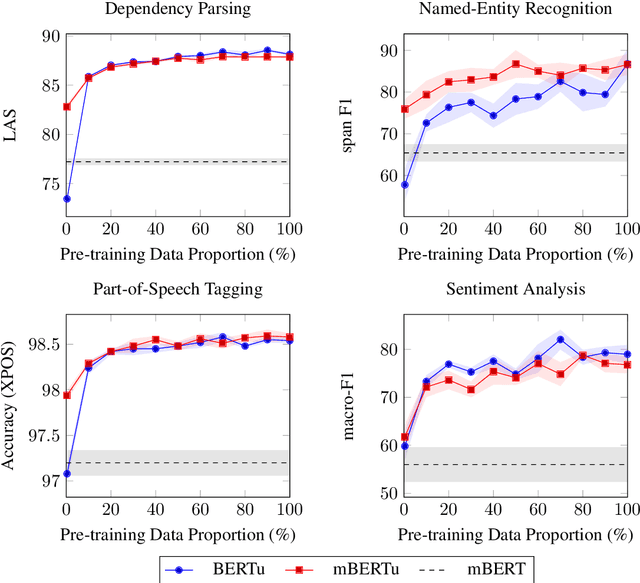
Multilingual language models such as mBERT have seen impressive cross-lingual transfer to a variety of languages, but many languages remain excluded from these models. In this paper, we analyse the effect of pre-training with monolingual data for a low-resource language that is not included in mBERT -- Maltese -- with a range of pre-training set ups. We conduct evaluations with the newly pre-trained models on three morphosyntactic tasks -- dependency parsing, part-of-speech tagging, and named-entity recognition -- and one semantic classification task -- sentiment analysis. We also present a newly created corpus for Maltese, and determine the effect that the pre-training data size and domain have on the downstream performance. Our results show that using a mixture of pre-training domains is often superior to using Wikipedia text only. We also find that a fraction of this corpus is enough to make significant leaps in performance over Wikipedia-trained models. We pre-train and compare two models on the new corpus: a monolingual BERT model trained from scratch (BERTu), and a further pre-trained multilingual BERT (mBERTu). The models achieve state-of-the-art performance on these tasks, despite the new corpus being considerably smaller than typically used corpora for high-resourced languages. On average, BERTu outperforms or performs competitively with mBERTu, and the largest gains are observed for higher-level tasks.
Face2Text revisited: Improved data set and baseline results
May 24, 2022
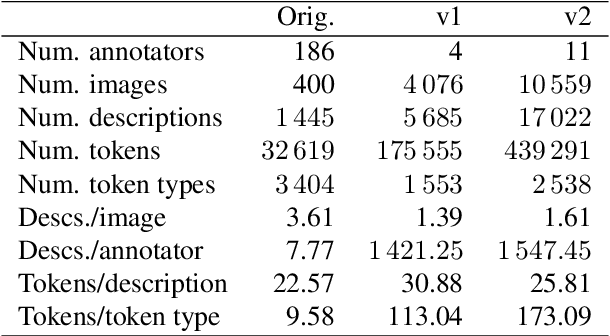

Current image description generation models do not transfer well to the task of describing human faces. To encourage the development of more human-focused descriptions, we developed a new data set of facial descriptions based on the CelebA image data set. We describe the properties of this data set, and present results from a face description generator trained on it, which explores the feasibility of using transfer learning from VGGFace/ResNet CNNs. Comparisons are drawn through both automated metrics and human evaluation by 76 English-speaking participants. The descriptions generated by the VGGFace-LSTM + Attention model are closest to the ground truth according to human evaluation whilst the ResNet-LSTM + Attention model obtained the highest CIDEr and CIDEr-D results (1.252 and 0.686 respectively). Together, the new data set and these experimental results provide data and baselines for future work in this area.
Data Augmentation for Speech Recognition in Maltese: A Low-Resource Perspective
Nov 15, 2021


Developing speech technologies is a challenge for low-resource languages for which both annotated and raw speech data is sparse. Maltese is one such language. Recent years have seen an increased interest in the computational processing of Maltese, including speech technologies, but resources for the latter remain sparse. In this paper, we consider data augmentation techniques for improving speech recognition for such languages, focusing on Maltese as a test case. We consider three different types of data augmentation: unsupervised training, multilingual training and the use of synthesized speech as training data. The goal is to determine which of these techniques, or combination of them, is the most effective to improve speech recognition for languages where the starting point is a small corpus of approximately 7 hours of transcribed speech. Our results show that combining the three data augmentation techniques studied here lead us to an absolute WER improvement of 15% without the use of a language model.
On the Language-specificity of Multilingual BERT and the Impact of Fine-tuning
Sep 14, 2021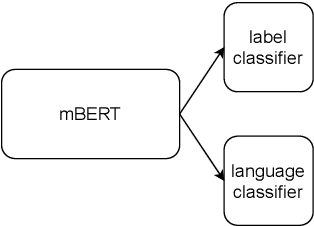
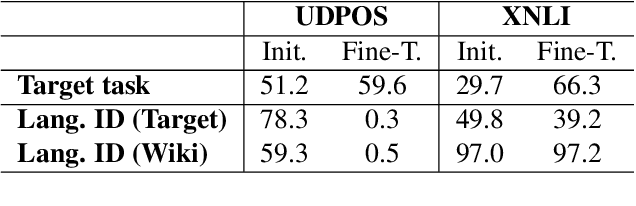
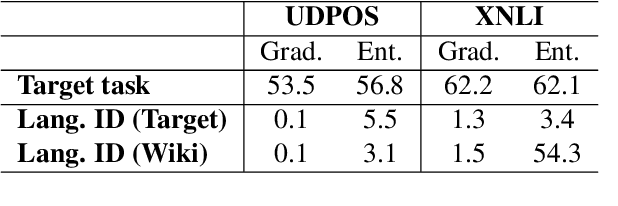

Recent work has shown evidence that the knowledge acquired by multilingual BERT (mBERT) has two components: a language-specific and a language-neutral one. This paper analyses the relationship between them, in the context of fine-tuning on two tasks -- POS tagging and natural language inference -- which require the model to bring to bear different degrees of language-specific knowledge. Visualisations reveal that mBERT loses the ability to cluster representations by language after fine-tuning, a result that is supported by evidence from language identification experiments. However, further experiments on 'unlearning' language-specific representations using gradient reversal and iterative adversarial learning are shown not to add further improvement to the language-independent component over and above the effect of fine-tuning. The results presented here suggest that the process of fine-tuning causes a reorganisation of the model's limited representational capacity, enhancing language-independent representations at the expense of language-specific ones.
MASRI-HEADSET: A Maltese Corpus for Speech Recognition
Aug 13, 2020
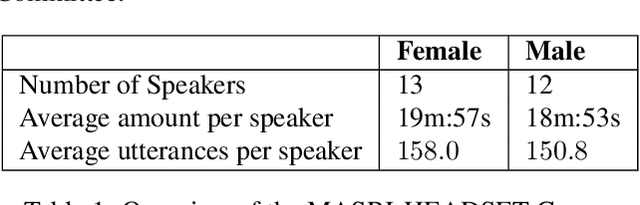
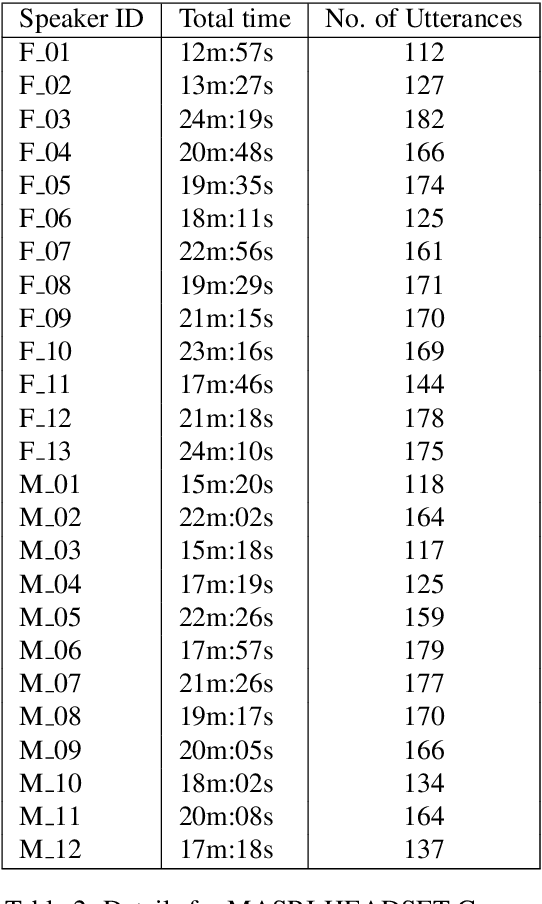
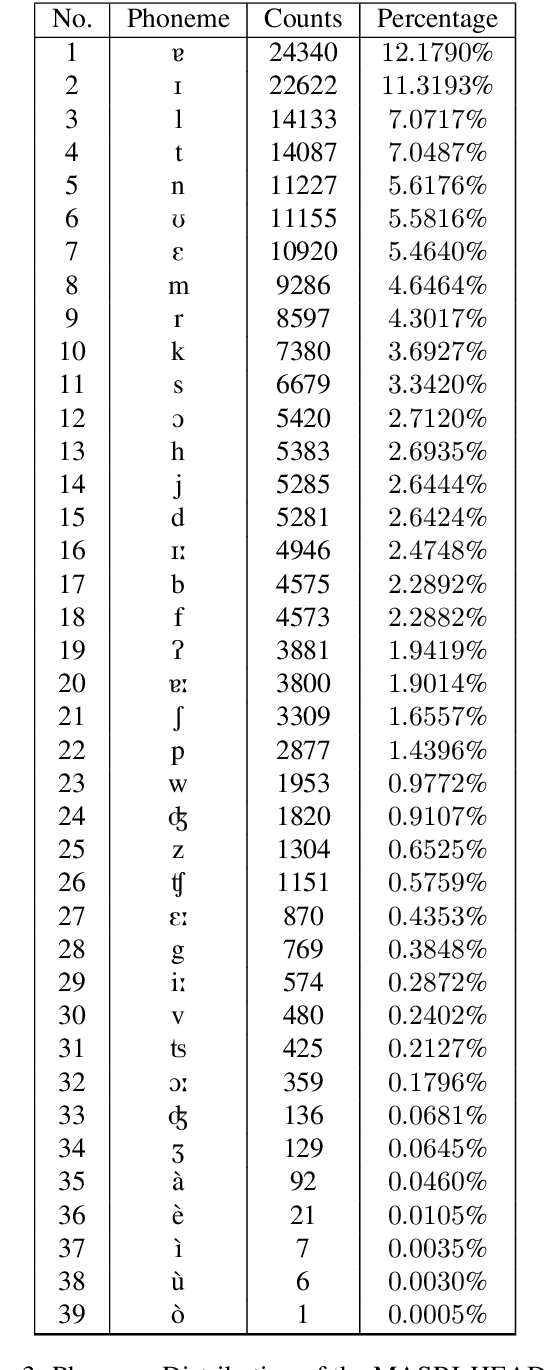
Maltese, the national language of Malta, is spoken by approximately 500,000 people. Speech processing for Maltese is still in its early stages of development. In this paper, we present the first spoken Maltese corpus designed purposely for Automatic Speech Recognition (ASR). The MASRI-HEADSET corpus was developed by the MASRI project at the University of Malta. It consists of 8 hours of speech paired with text, recorded by using short text snippets in a laboratory environment. The speakers were recruited from different geographical locations all over the Maltese islands, and were roughly evenly distributed by gender. This paper also presents some initial results achieved in baseline experiments for Maltese ASR using Sphinx and Kaldi. The MASRI-HEADSET Corpus is publicly available for research/academic purposes.
Face2Text: Collecting an Annotated Image Description Corpus for the Generation of Rich Face Descriptions
Mar 10, 2018
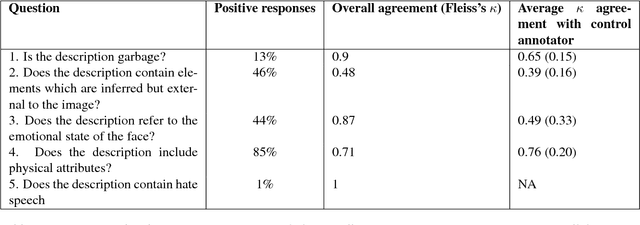
The past few years have witnessed renewed interest in NLP tasks at the interface between vision and language. One intensively-studied problem is that of automatically generating text from images. In this paper, we extend this problem to the more specific domain of face description. Unlike scene descriptions, face descriptions are more fine-grained and rely on attributes extracted from the image, rather than objects and relations. Given that no data exists for this task, we present an ongoing crowdsourcing study to collect a corpus of descriptions of face images taken `in the wild'. To gain a better understanding of the variation we find in face description and the possible issues that this may raise, we also conducted an annotation study on a subset of the corpus. Primarily, we found descriptions to refer to a mixture of attributes, not only physical, but also emotional and inferential, which is bound to create further challenges for current image-to-text methods.