 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePre-training Data Quality and Quantity for a Low-Resource Language: New Corpus and BERT Models for Maltese
May 26, 2022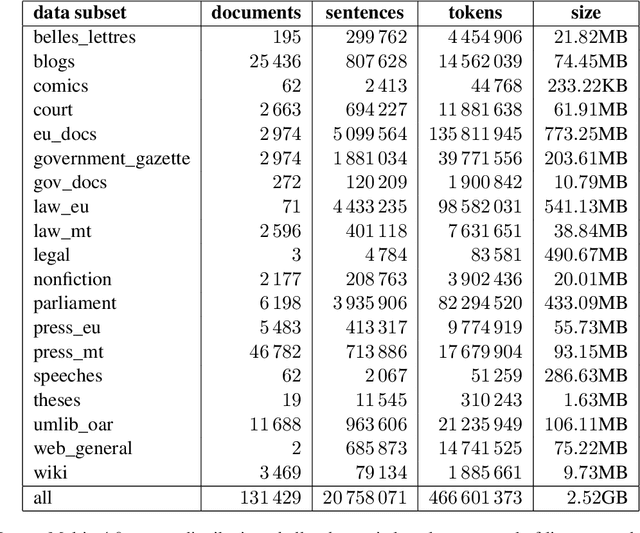
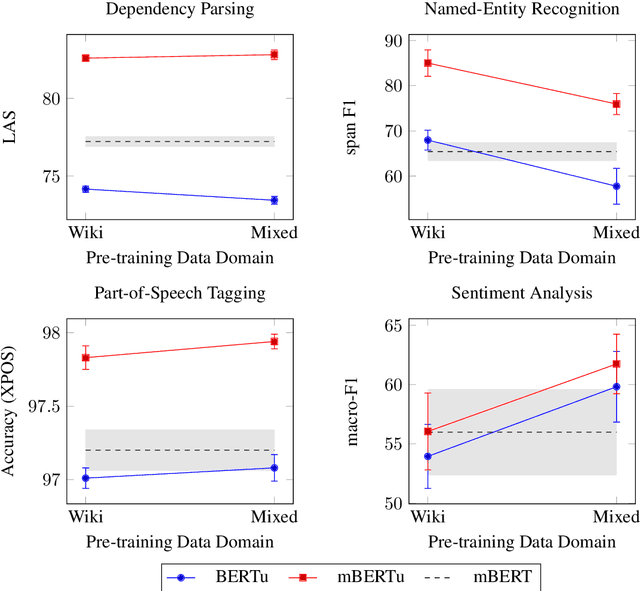
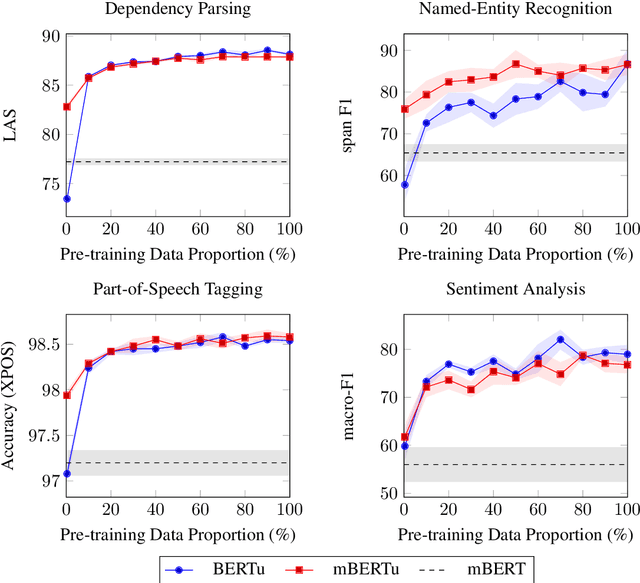
Multilingual language models such as mBERT have seen impressive cross-lingual transfer to a variety of languages, but many languages remain excluded from these models. In this paper, we analyse the effect of pre-training with monolingual data for a low-resource language that is not included in mBERT -- Maltese -- with a range of pre-training set ups. We conduct evaluations with the newly pre-trained models on three morphosyntactic tasks -- dependency parsing, part-of-speech tagging, and named-entity recognition -- and one semantic classification task -- sentiment analysis. We also present a newly created corpus for Maltese, and determine the effect that the pre-training data size and domain have on the downstream performance. Our results show that using a mixture of pre-training domains is often superior to using Wikipedia text only. We also find that a fraction of this corpus is enough to make significant leaps in performance over Wikipedia-trained models. We pre-train and compare two models on the new corpus: a monolingual BERT model trained from scratch (BERTu), and a further pre-trained multilingual BERT (mBERTu). The models achieve state-of-the-art performance on these tasks, despite the new corpus being considerably smaller than typically used corpora for high-resourced languages. On average, BERTu outperforms or performs competitively with mBERTu, and the largest gains are observed for higher-level tasks.
Face2Text revisited: Improved data set and baseline results
May 24, 2022
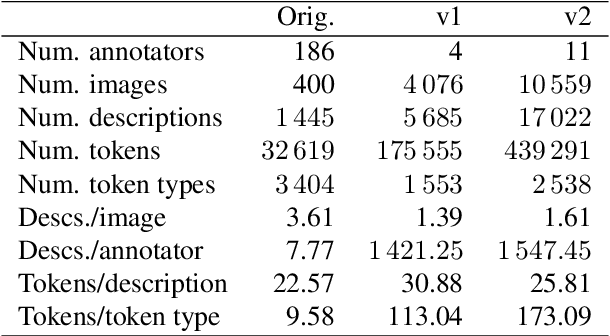

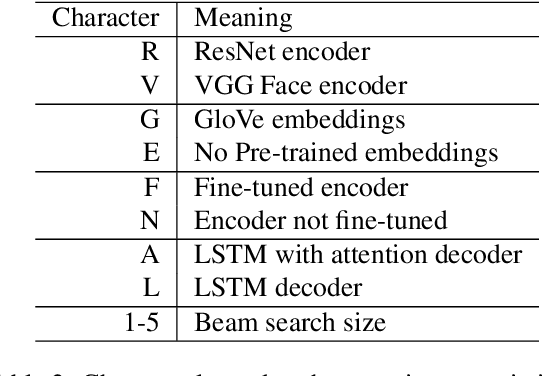
Current image description generation models do not transfer well to the task of describing human faces. To encourage the development of more human-focused descriptions, we developed a new data set of facial descriptions based on the CelebA image data set. We describe the properties of this data set, and present results from a face description generator trained on it, which explores the feasibility of using transfer learning from VGGFace/ResNet CNNs. Comparisons are drawn through both automated metrics and human evaluation by 76 English-speaking participants. The descriptions generated by the VGGFace-LSTM + Attention model are closest to the ground truth according to human evaluation whilst the ResNet-LSTM + Attention model obtained the highest CIDEr and CIDEr-D results (1.252 and 0.686 respectively). Together, the new data set and these experimental results provide data and baselines for future work in this area.
On the Language-specificity of Multilingual BERT and the Impact of Fine-tuning
Sep 14, 2021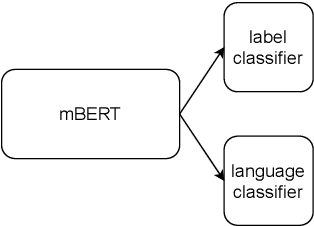
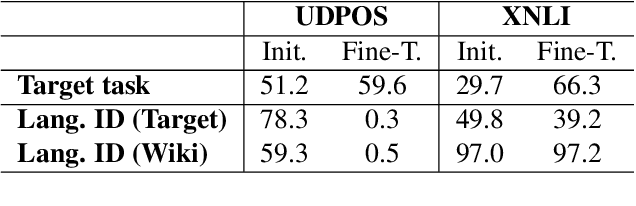
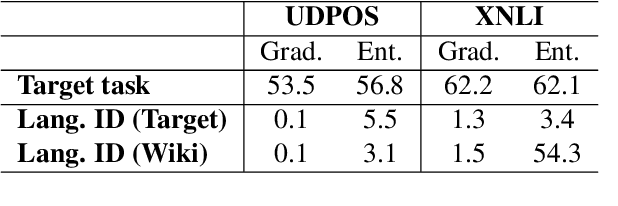

Recent work has shown evidence that the knowledge acquired by multilingual BERT (mBERT) has two components: a language-specific and a language-neutral one. This paper analyses the relationship between them, in the context of fine-tuning on two tasks -- POS tagging and natural language inference -- which require the model to bring to bear different degrees of language-specific knowledge. Visualisations reveal that mBERT loses the ability to cluster representations by language after fine-tuning, a result that is supported by evidence from language identification experiments. However, further experiments on 'unlearning' language-specific representations using gradient reversal and iterative adversarial learning are shown not to add further improvement to the language-independent component over and above the effect of fine-tuning. The results presented here suggest that the process of fine-tuning causes a reorganisation of the model's limited representational capacity, enhancing language-independent representations at the expense of language-specific ones.
Automated segmentation of microtomography imaging of Egyptian mummies
May 14, 2021

Propagation Phase Contrast Synchrotron Microtomography (PPC-SR${\mu}$CT) is the gold standard for non-invasive and non-destructive access to internal structures of archaeological remains. In this analysis, the virtual specimen needs to be segmented to separate different parts or materials, a process that normally requires considerable human effort. In the Automated SEgmentation of Microtomography Imaging (ASEMI) project, we developed a tool to automatically segment these volumetric images, using manually segmented samples to tune and train a machine learning model. For a set of four specimens of ancient Egyptian animal mummies we achieve an overall accuracy of 94-98% when compared with manually segmented slices, approaching the results of off-the-shelf commercial software using deep learning (97-99%) at much lower complexity. A qualitative analysis of the segmented output shows that our results are close in term of usability to those from deep learning, justifying the use of these techniques.
On Architectures for Including Visual Information in Neural Language Models for Image Description
Nov 09, 2019
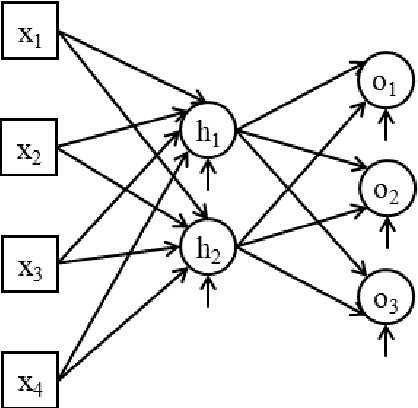

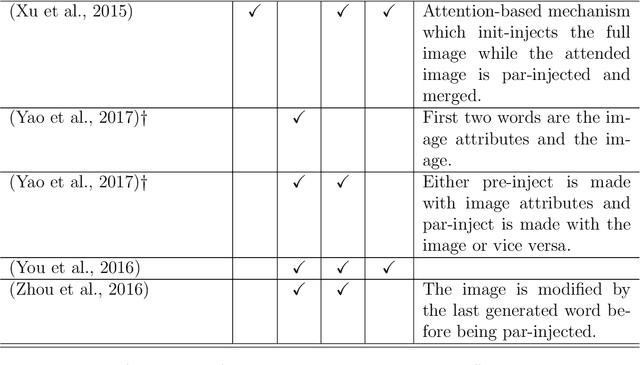
A neural language model can be conditioned into generating descriptions for images by providing visual information apart from the sentence prefix. This visual information can be included into the language model through different points of entry resulting in different neural architectures. We identify four main architectures which we call init-inject, pre-inject, par-inject, and merge. We analyse these four architectures and conclude that the best performing one is init-inject, which is when the visual information is injected into the initial state of the recurrent neural network. We confirm this using both automatic evaluation measures and human annotation. We then analyse how much influence the images have on each architecture. This is done by measuring how different the output probabilities of a model are when a partial sentence is combined with a completely different image from the one it is meant to be combined with. We find that init-inject tends to quickly become less influenced by the image as more words are generated. A different architecture called merge, which is when the visual information is merged with the recurrent neural network's hidden state vector prior to output, loses visual influence much more slowly, suggesting that it would work better for generating longer sentences. We also observe that the merge architecture can have its recurrent neural network pre-trained in a text-only language model (transfer learning) rather than be initialised randomly as usual. This results in even better performance than the other architectures, provided that the source language model is not too good at language modelling or it will overspecialise and be less effective at image description generation. Our work opens up new avenues of research in neural architectures, explainable AI, and transfer learning.
Visuallly Grounded Generation of Entailments from Premises
Sep 21, 2019
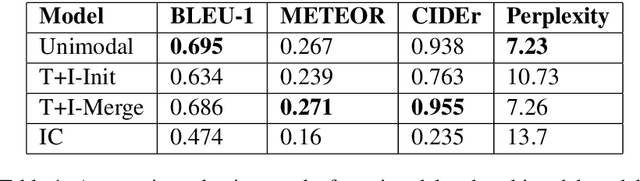
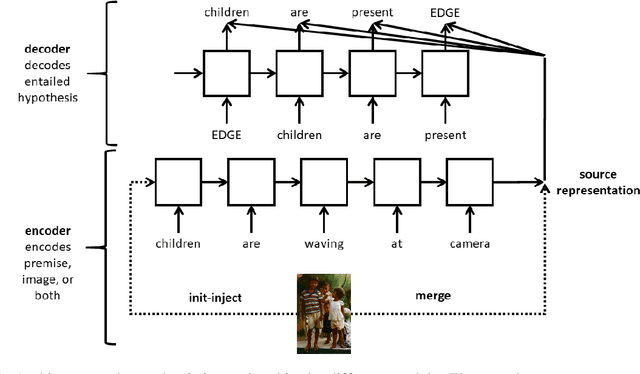

Natural Language Inference (NLI) is the task of determining the semantic relationship between a premise and a hypothesis. In this paper, we focus on the {\em generation} of hypotheses from premises in a multimodal setting, to generate a sentence (hypothesis) given an image and/or its description (premise) as the input. The main goals of this paper are (a) to investigate whether it is reasonable to frame NLI as a generation task; and (b) to consider the degree to which grounding textual premises in visual information is beneficial to generation. We compare different neural architectures, showing through automatic and human evaluation that entailments can indeed be generated successfully. We also show that multimodal models outperform unimodal models in this task, albeit marginally.
Transfer learning from language models to image caption generators: Better models may not transfer better
Jan 01, 2019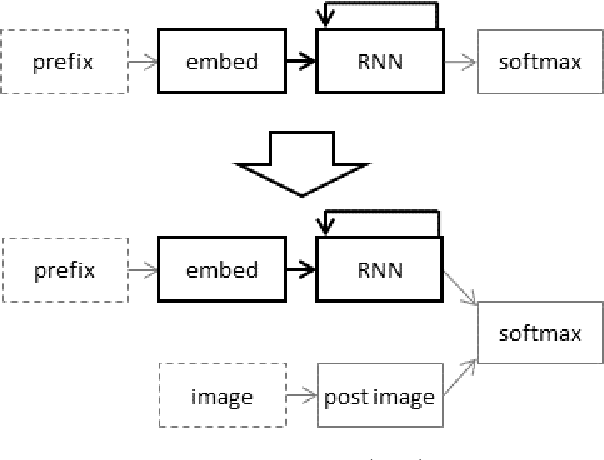

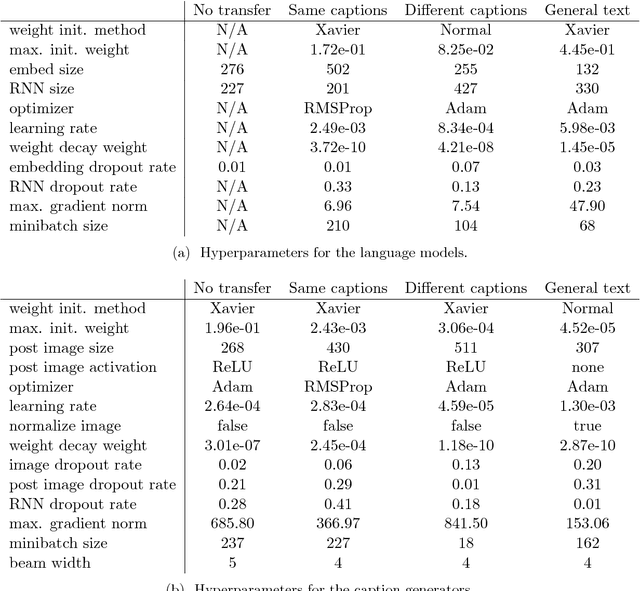
When designing a neural caption generator, a convolutional neural network can be used to extract image features. Is it possible to also use a neural language model to extract sentence prefix features? We answer this question by trying different ways to transfer the recurrent neural network and embedding layer from a neural language model to an image caption generator. We find that image caption generators with transferred parameters perform better than those trained from scratch, even when simply pre-training them on the text of the same captions dataset it will later be trained on. We also find that the best language models (in terms of perplexity) do not result in the best caption generators after transfer learning.
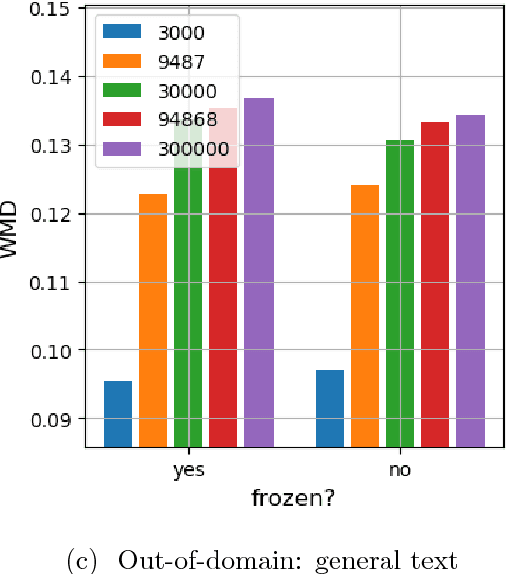
Quantifying the amount of visual information used by neural caption generators
Oct 12, 2018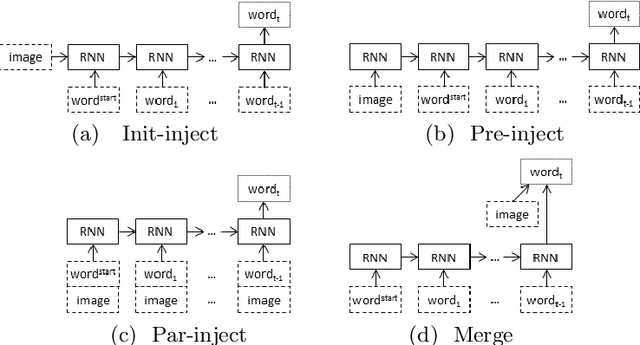
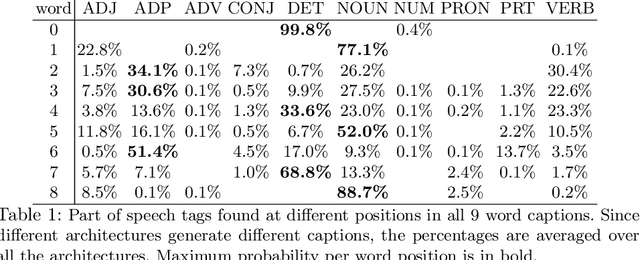
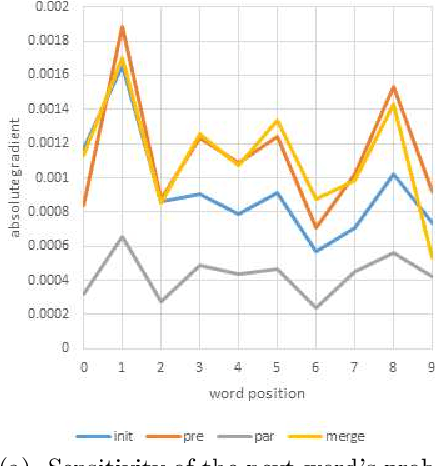
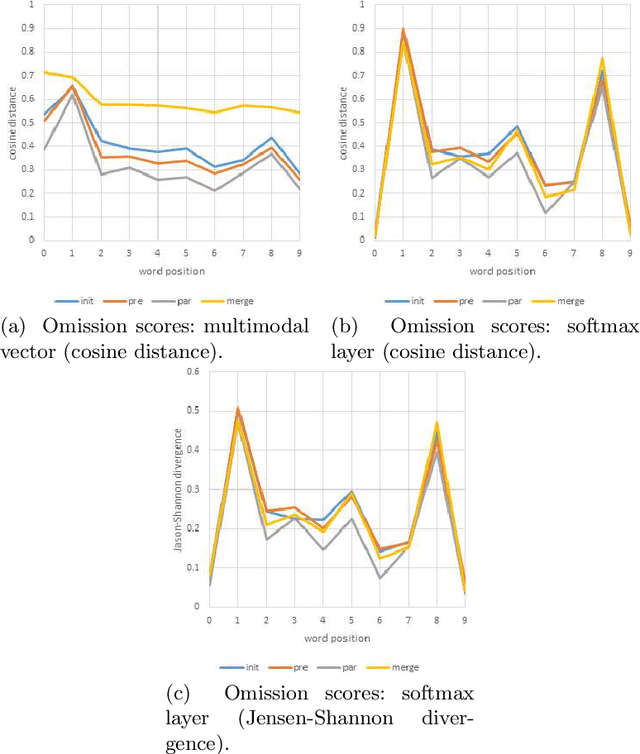
This paper addresses the sensitivity of neural image caption generators to their visual input. A sensitivity analysis and omission analysis based on image foils is reported, showing that the extent to which image captioning architectures retain and are sensitive to visual information varies depending on the type of word being generated and the position in the caption as a whole. We motivate this work in the context of broader goals in the field to achieve more explainability in AI.
Pre-gen metrics: Predicting caption quality metrics without generating captions
Oct 12, 2018Image caption generation systems are typically evaluated against reference outputs. We show that it is possible to predict output quality without generating the captions, based on the probability assigned by the neural model to the reference captions. Such pre-gen metrics are strongly correlated to standard evaluation metrics.
Grounded Textual Entailment
Jun 14, 2018
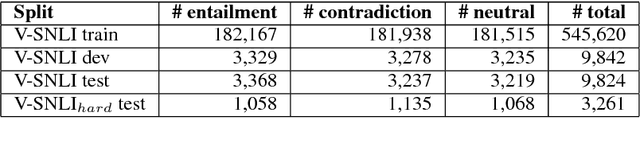

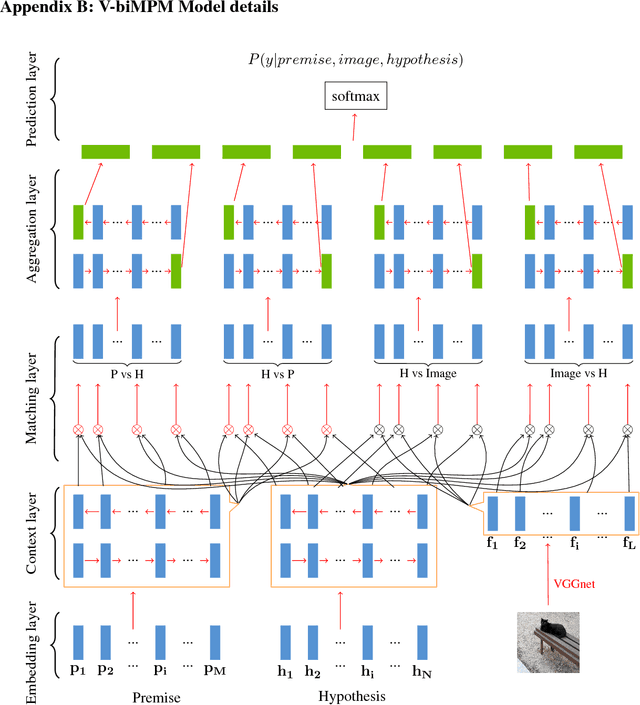
Capturing semantic relations between sentences, such as entailment, is a long-standing challenge for computational semantics. Logic-based models analyse entailment in terms of possible worlds (interpretations, or situations) where a premise P entails a hypothesis H iff in all worlds where P is true, H is also true. Statistical models view this relationship probabilistically, addressing it in terms of whether a human would likely infer H from P. In this paper, we wish to bridge these two perspectives, by arguing for a visually-grounded version of the Textual Entailment task. Specifically, we ask whether models can perform better if, in addition to P and H, there is also an image (corresponding to the relevant "world" or "situation"). We use a multimodal version of the SNLI dataset (Bowman et al., 2015) and we compare "blind" and visually-augmented models of textual entailment. We show that visual information is beneficial, but we also conduct an in-depth error analysis that reveals that current multimodal models are not performing "grounding" in an optimal fashion.