 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransfer Learning in Multilingual Neural Machine Translation with Dynamic Vocabulary
Nov 03, 2018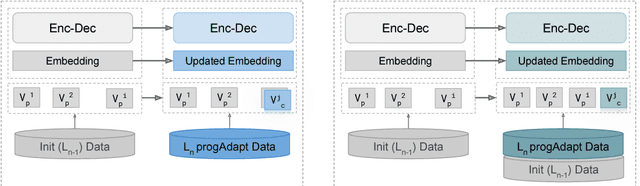
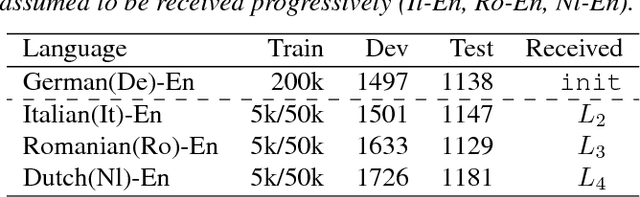
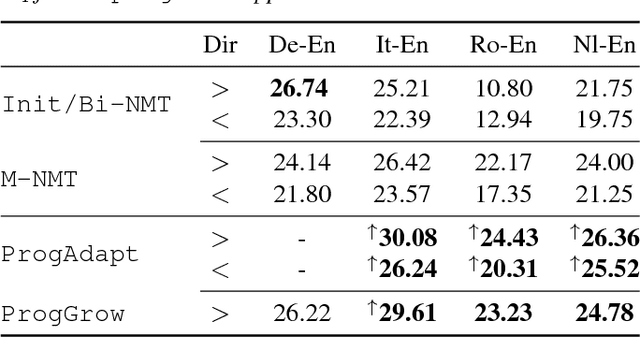
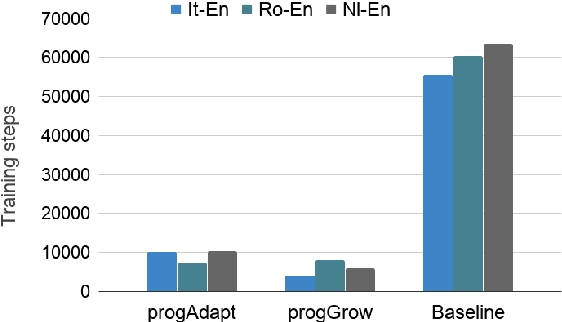
We propose a method to transfer knowledge across neural machine translation (NMT) models by means of a shared dynamic vocabulary. Our approach allows to extend an initial model for a given language pair to cover new languages by adapting its vocabulary as long as new data become available (i.e., introducing new vocabulary items if they are not included in the initial model). The parameter transfer mechanism is evaluated in two scenarios: i) to adapt a trained single language NMT system to work with a new language pair and ii) to continuously add new language pairs to grow to a multilingual NMT system. In both the scenarios our goal is to improve the translation performance, while minimizing the training convergence time. Preliminary experiments spanning five languages with different training data sizes (i.e., 5k and 50k parallel sentences) show a significant performance gain ranging from +3.85 up to +13.63 BLEU in different language directions. Moreover, when compared with training an NMT model from scratch, our transfer-learning approach allows us to reach higher performance after training up to 4% of the total training steps.
Neural Machine Translation into Language Varieties
Nov 02, 2018

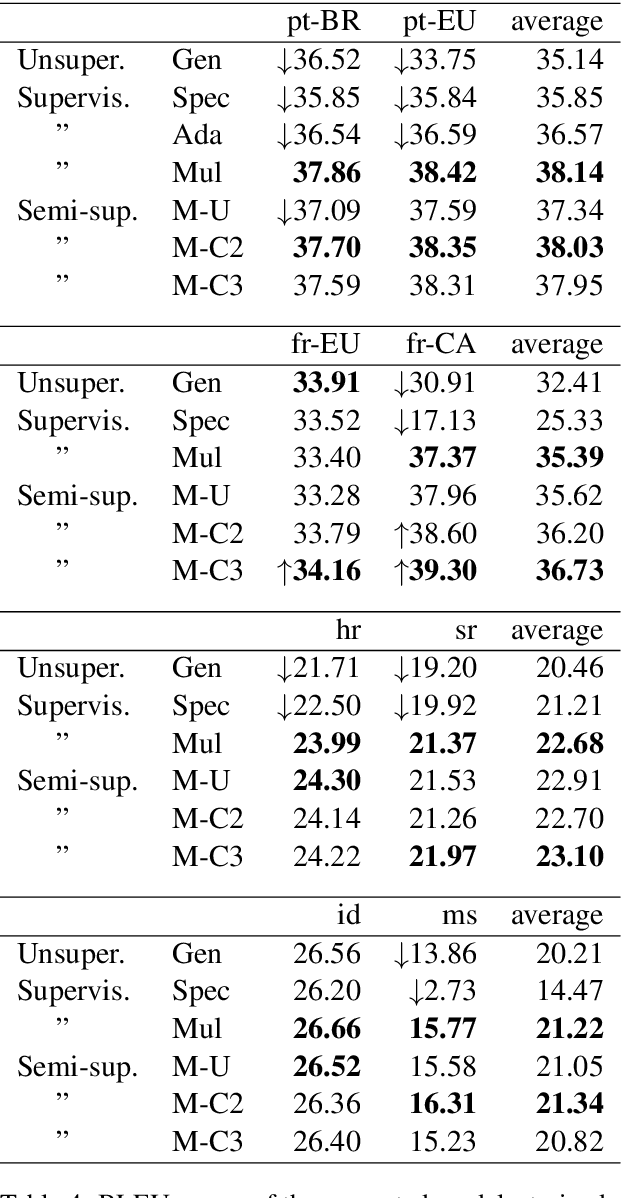
Both research and commercial machine translation have so far neglected the importance of properly handling the spelling, lexical and grammar divergences occurring among language varieties. Notable cases are standard national varieties such as Brazilian and European Portuguese, and Canadian and European French, which popular online machine translation services are not keeping distinct. We show that an evident side effect of modeling such varieties as unique classes is the generation of inconsistent translations. In this work, we investigate the problem of training neural machine translation from English to specific pairs of language varieties, assuming both labeled and unlabeled parallel texts, and low-resource conditions. We report experiments from English to two pairs of dialects, EuropeanBrazilian Portuguese and European-Canadian French, and two pairs of standardized varieties, Croatian-Serbian and Indonesian-Malay. We show significant BLEU score improvements over baseline systems when translation into similar languages is learned as a multilingual task with shared representations.
Grounded Textual Entailment
Jun 14, 2018
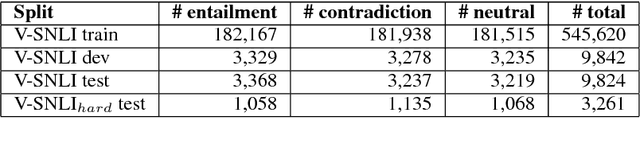

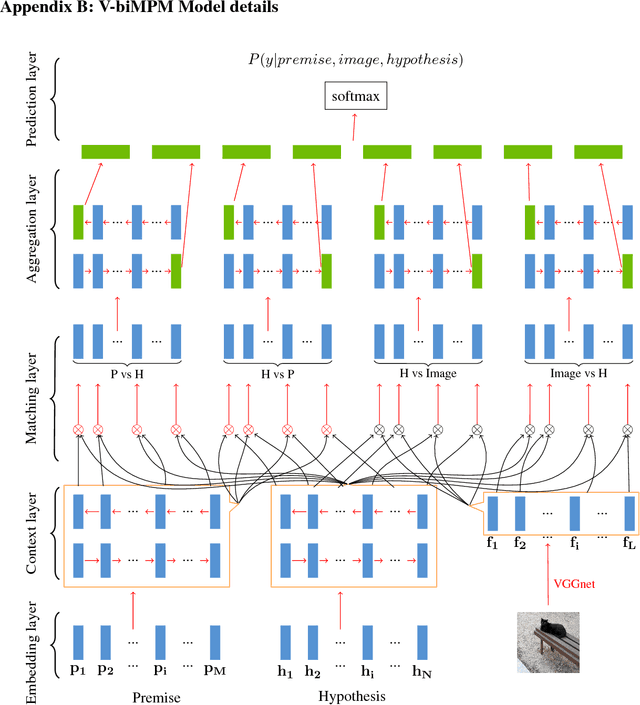
Capturing semantic relations between sentences, such as entailment, is a long-standing challenge for computational semantics. Logic-based models analyse entailment in terms of possible worlds (interpretations, or situations) where a premise P entails a hypothesis H iff in all worlds where P is true, H is also true. Statistical models view this relationship probabilistically, addressing it in terms of whether a human would likely infer H from P. In this paper, we wish to bridge these two perspectives, by arguing for a visually-grounded version of the Textual Entailment task. Specifically, we ask whether models can perform better if, in addition to P and H, there is also an image (corresponding to the relevant "world" or "situation"). We use a multimodal version of the SNLI dataset (Bowman et al., 2015) and we compare "blind" and visually-augmented models of textual entailment. We show that visual information is beneficial, but we also conduct an in-depth error analysis that reveals that current multimodal models are not performing "grounding" in an optimal fashion.