 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJointly Optimizing Translations and Speech Timing to Improve Isochrony in Automatic Dubbing
Feb 25, 2023



Automatic dubbing (AD) is the task of translating the original speech in a video into target language speech. The new target language speech should satisfy isochrony; that is, the new speech should be time aligned with the original video, including mouth movements, pauses, hand gestures, etc. In this paper, we propose training a model that directly optimizes both the translation as well as the speech duration of the generated translations. We show that this system generates speech that better matches the timing of the original speech, compared to prior work, while simplifying the system architecture.
Isometric MT: Neural Machine Translation for Automatic Dubbing
Dec 20, 2021
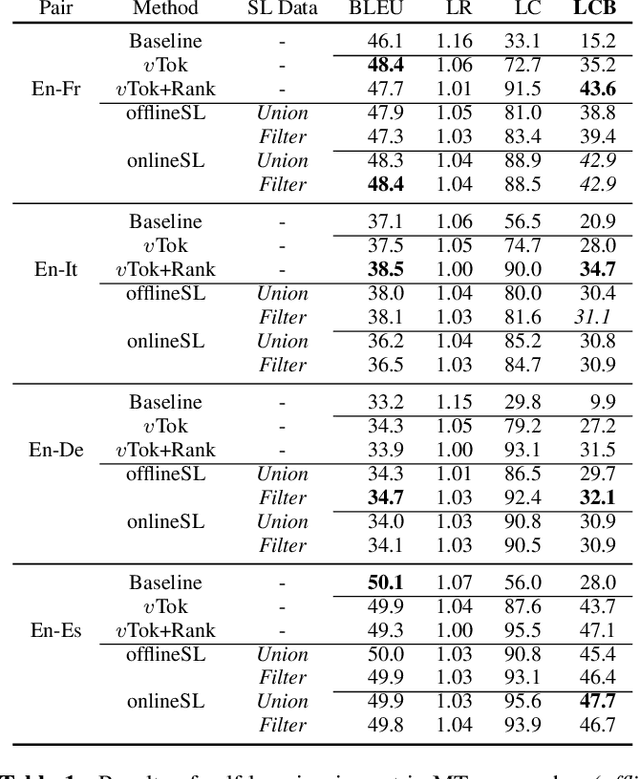
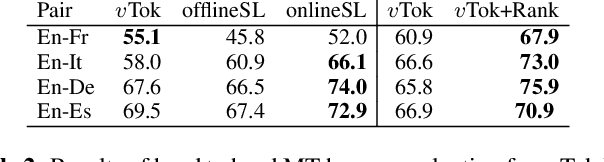
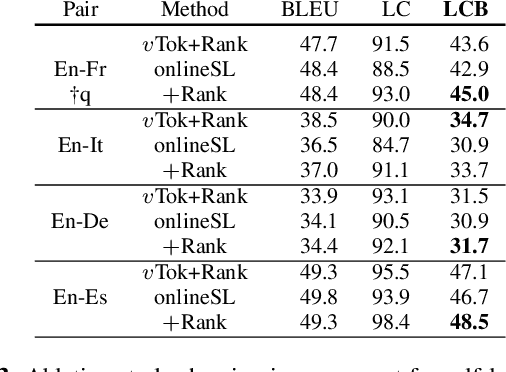
Automatic dubbing (AD) is among the use cases where translations should fit a given length template in order to achieve synchronicity between source and target speech. For neural machine translation (MT), generating translations of length close to the source length (e.g. within +-10% in character count), while preserving quality is a challenging task. Controlling NMT output length comes at a cost to translation quality which is usually mitigated with a two step approach of generation of n-best hypotheses and then re-ranking them based on length and quality. This work, introduces a self-learning approach that allows a transformer model to directly learn to generate outputs that closely match the source length, in short isometric MT. In particular, our approach for isometric MT does not require to generate multiple hypotheses nor any auxiliary scoring function. We report results on four language pairs (English - French, Italian, German, Spanish) with a publicly available benchmark based on TED Talk data. Both automatic and manual evaluations show that our self-learning approach to performs on par with more complex isometric MT approaches.
Prosody-Aware Neural Machine Translation for Dubbing
Dec 16, 2021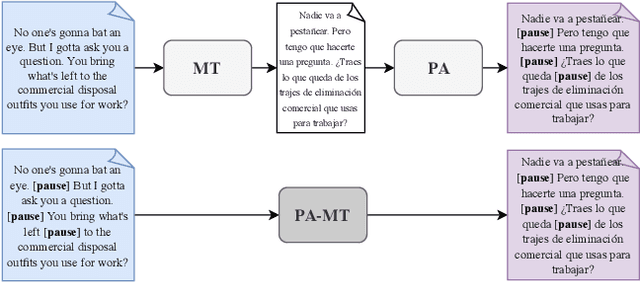
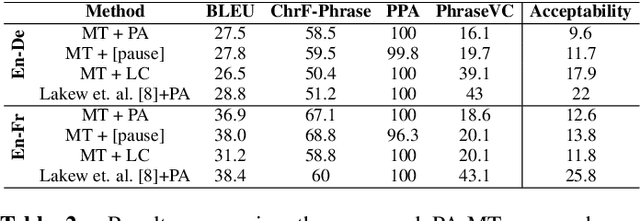
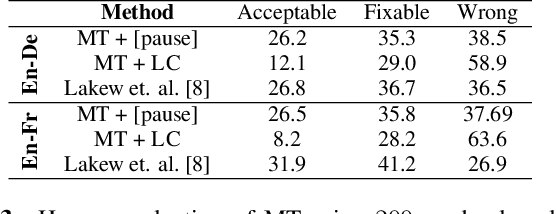

We introduce the task of prosody-aware machine translation which aims at generating translations suitable for dubbing. Dubbing of a spoken sentence requires transferring the content as well as the prosodic structure of the source into the target language to preserve timing information. Practically, this implies correctly projecting pauses from the source to the target and ensuring that target speech segments have roughly the same duration of the corresponding source segments. In this work, we propose an implicit and explicit modeling approaches to integrate prosody information into neural machine translation. Experiments on English-German/French with automatic metrics show that the simplest of the considered approaches works best. Results are confirmed by human evaluations of translations and dubbed videos.
Machine Translation Verbosity Control for Automatic Dubbing
Oct 08, 2021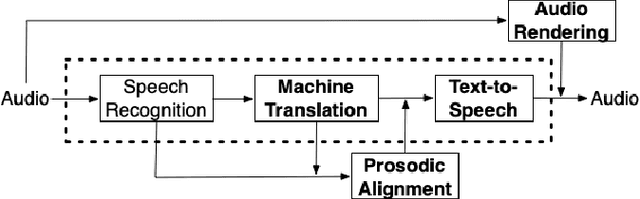
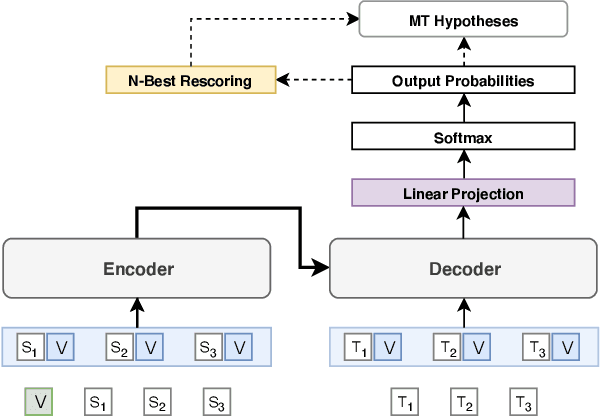
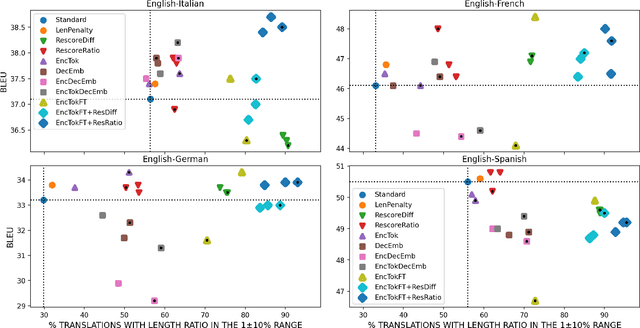
Automatic dubbing aims at seamlessly replacing the speech in a video document with synthetic speech in a different language. The task implies many challenges, one of which is generating translations that not only convey the original content, but also match the duration of the corresponding utterances. In this paper, we focus on the problem of controlling the verbosity of machine translation output, so that subsequent steps of our automatic dubbing pipeline can generate dubs of better quality. We propose new methods to control the verbosity of MT output and compare them against the state of the art with both intrinsic and extrinsic evaluations. For our experiments we use a public data set to dub English speeches into French, Italian, German and Spanish. Finally, we report extensive subjective tests that measure the impact of MT verbosity control on the final quality of dubbed video clips.
Self-Learning for Zero Shot Neural Machine Translation
Mar 10, 2021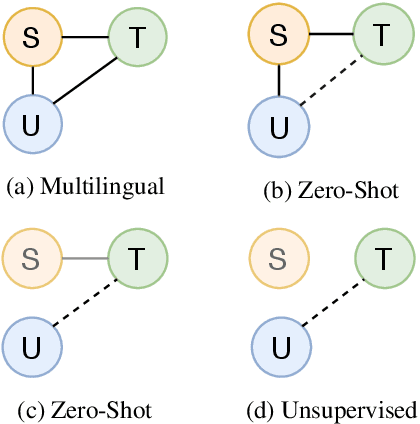

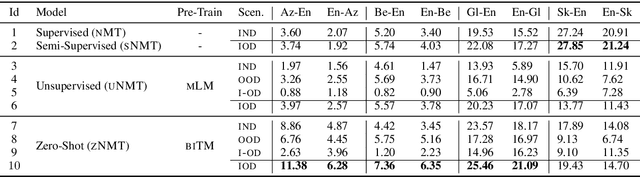
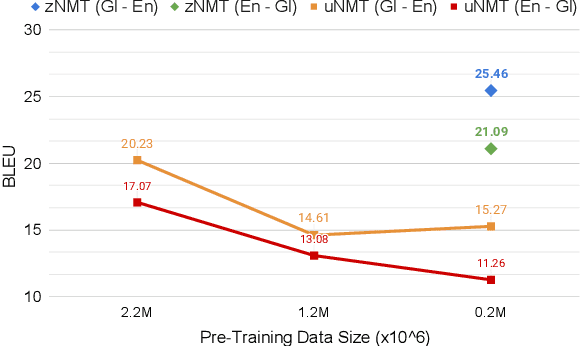
Neural Machine Translation (NMT) approaches employing monolingual data are showing steady improvements in resource rich conditions. However, evaluations using real-world low-resource languages still result in unsatisfactory performance. This work proposes a novel zero-shot NMT modeling approach that learns without the now-standard assumption of a pivot language sharing parallel data with the zero-shot source and target languages. Our approach is based on three stages: initialization from any pre-trained NMT model observing at least the target language, augmentation of source sides leveraging target monolingual data, and learning to optimize the initial model to the zero-shot pair, where the latter two constitute a self-learning cycle. Empirical findings involving four diverse (in terms of a language family, script and relatedness) zero-shot pairs show the effectiveness of our approach with up to +5.93 BLEU improvement against a supervised bilingual baseline. Compared to unsupervised NMT, consistent improvements are observed even in a domain-mismatch setting, attesting to the usability of our method.
Low Resource Neural Machine Translation: A Benchmark for Five African Languages
Mar 31, 2020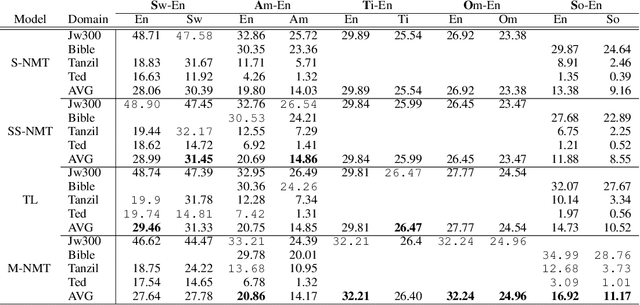
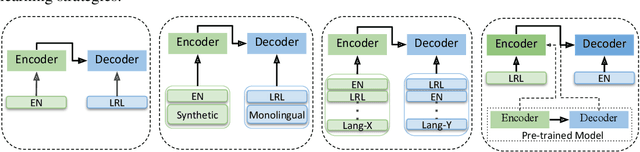

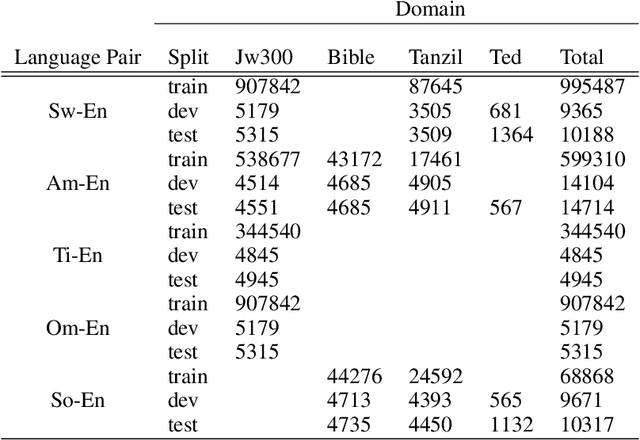
Recent advents in Neural Machine Translation (NMT) have shown improvements in low-resource language (LRL) translation tasks. In this work, we benchmark NMT between English and five African LRL pairs (Swahili, Amharic, Tigrigna, Oromo, Somali [SATOS]). We collected the available resources on the SATOS languages to evaluate the current state of NMT for LRLs. Our evaluation, comparing a baseline single language pair NMT model against semi-supervised learning, transfer learning, and multilingual modeling, shows significant performance improvements both in the En-LRL and LRL-En directions. In terms of averaged BLEU score, the multilingual approach shows the largest gains, up to +5 points, in six out of ten translation directions. To demonstrate the generalization capability of each model, we also report results on multi-domain test sets. We release the standardized experimental data and the test sets for future works addressing the challenges of NMT in under-resourced settings, in particular for the SATOS languages.
Adapting Multilingual Neural Machine Translation to Unseen Languages
Oct 30, 2019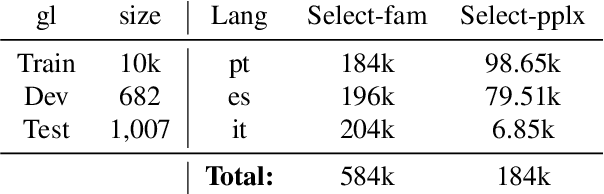
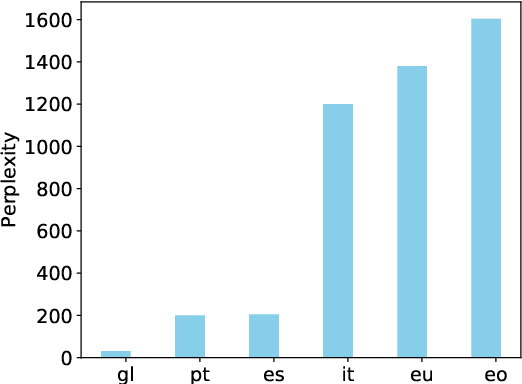
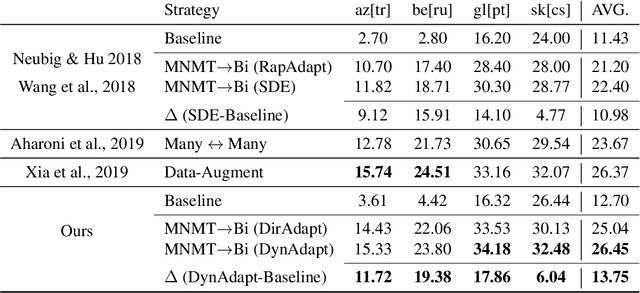
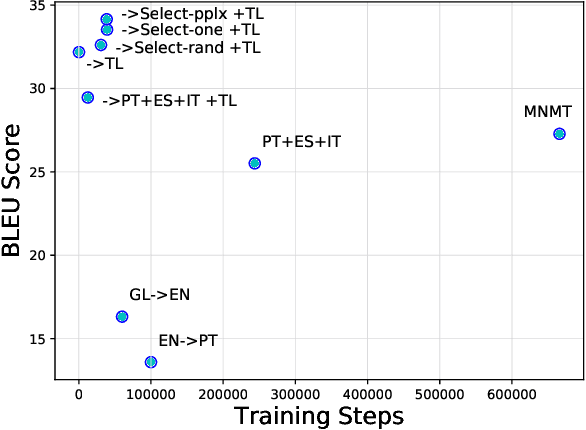
Multilingual Neural Machine Translation (MNMT) for low-resource languages (LRL) can be enhanced by the presence of related high-resource languages (HRL), but the relatedness of HRL usually relies on predefined linguistic assumptions about language similarity. Recently, adapting MNMT to a LRL has shown to greatly improve performance. In this work, we explore the problem of adapting an MNMT model to an unseen LRL using data selection and model adaptation. In order to improve NMT for LRL, we employ perplexity to select HRL data that are most similar to the LRL on the basis of language distance. We extensively explore data selection in popular multilingual NMT settings, namely in (zero-shot) translation, and in adaptation from a multilingual pre-trained model, for both directions (LRL-en). We further show that dynamic adaptation of the model's vocabulary results in a more favourable segmentation for the LRL in comparison with direct adaptation. Experiments show reductions in training time and significant performance gains over LRL baselines, even with zero LRL data (+13.0 BLEU), up to +17.0 BLEU for pre-trained multilingual model dynamic adaptation with related data selection. Our method outperforms current approaches, such as massively multilingual models and data augmentation, on four LRL.
Multilingual Neural Machine Translation for Zero-Resource Languages
Sep 16, 2019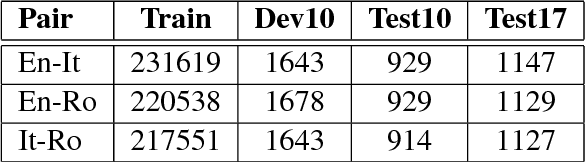
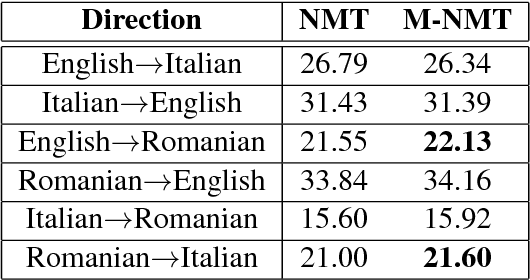
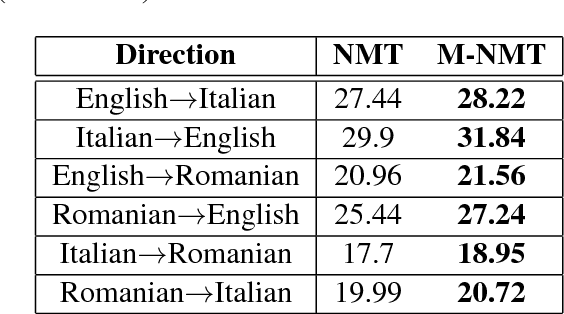
In recent years, Neural Machine Translation (NMT) has been shown to be more effective than phrase-based statistical methods, thus quickly becoming the state of the art in machine translation (MT). However, NMT systems are limited in translating low-resourced languages, due to the significant amount of parallel data that is required to learn useful mappings between languages. In this work, we show how the so-called multilingual NMT can help to tackle the challenges associated with low-resourced language translation. The underlying principle of multilingual NMT is to force the creation of hidden representations of words in a shared semantic space across multiple languages, thus enabling a positive parameter transfer across languages. Along this direction, we present multilingual translation experiments with three languages (English, Italian, Romanian) covering six translation directions, utilizing both recurrent neural networks and transformer (or self-attentive) neural networks. We then focus on the zero-shot translation problem, that is how to leverage multi-lingual data in order to learn translation directions that are not covered by the available training material. To this aim, we introduce our recently proposed iterative self-training method, which incrementally improves a multilingual NMT on a zero-shot direction by just relying on monolingual data. Our results on TED talks data show that multilingual NMT outperforms conventional bilingual NMT, that the transformer NMT outperforms recurrent NMT, and that zero-shot NMT outperforms conventional pivoting methods and even matches the performance of a fully-trained bilingual system.
Improving Zero-Shot Translation of Low-Resource Languages
Nov 04, 2018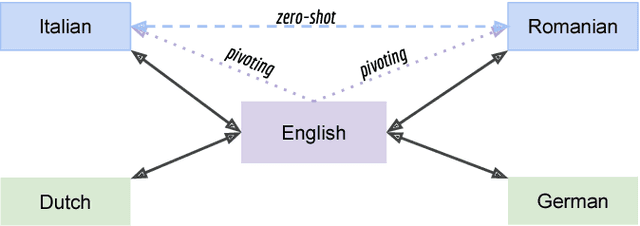

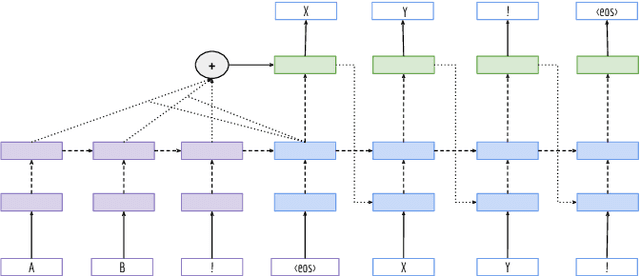
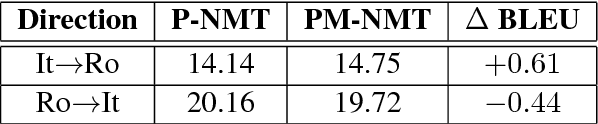
Recent work on multilingual neural machine translation reported competitive performance with respect to bilingual models and surprisingly good performance even on (zeroshot) translation directions not observed at training time. We investigate here a zero-shot translation in a particularly lowresource multilingual setting. We propose a simple iterative training procedure that leverages a duality of translations directly generated by the system for the zero-shot directions. The translations produced by the system (sub-optimal since they contain mixed language from the shared vocabulary), are then used together with the original parallel data to feed and iteratively re-train the multilingual network. Over time, this allows the system to learn from its own generated and increasingly better output. Our approach shows to be effective in improving the two zero-shot directions of our multilingual model. In particular, we observed gains of about 9 BLEU points over a baseline multilingual model and up to 2.08 BLEU over a pivoting mechanism using two bilingual models. Further analysis shows that there is also a slight improvement in the non-zero-shot language directions.
Transfer Learning in Multilingual Neural Machine Translation with Dynamic Vocabulary
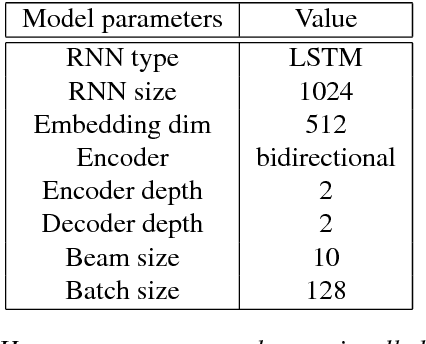
Nov 03, 2018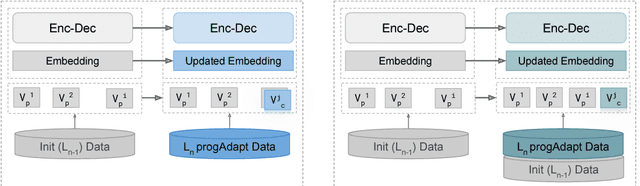
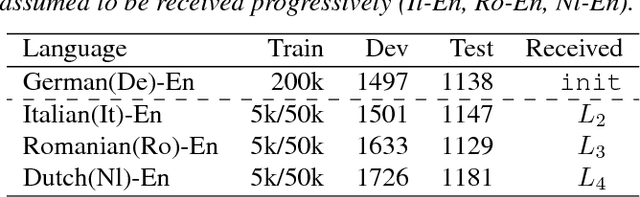
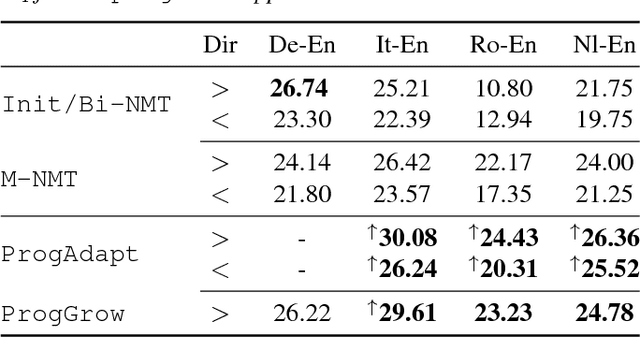
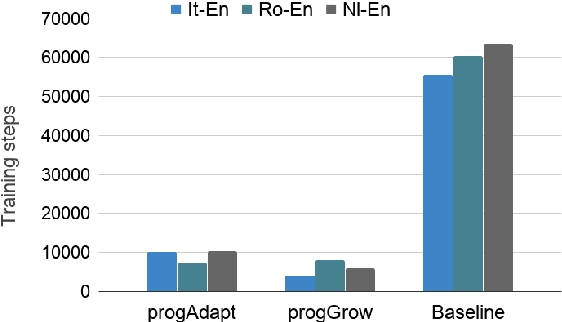
We propose a method to transfer knowledge across neural machine translation (NMT) models by means of a shared dynamic vocabulary. Our approach allows to extend an initial model for a given language pair to cover new languages by adapting its vocabulary as long as new data become available (i.e., introducing new vocabulary items if they are not included in the initial model). The parameter transfer mechanism is evaluated in two scenarios: i) to adapt a trained single language NMT system to work with a new language pair and ii) to continuously add new language pairs to grow to a multilingual NMT system. In both the scenarios our goal is to improve the translation performance, while minimizing the training convergence time. Preliminary experiments spanning five languages with different training data sizes (i.e., 5k and 50k parallel sentences) show a significant performance gain ranging from +3.85 up to +13.63 BLEU in different language directions. Moreover, when compared with training an NMT model from scratch, our transfer-learning approach allows us to reach higher performance after training up to 4% of the total training steps.