 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIsometric MT: Neural Machine Translation for Automatic Dubbing
Paper and Code

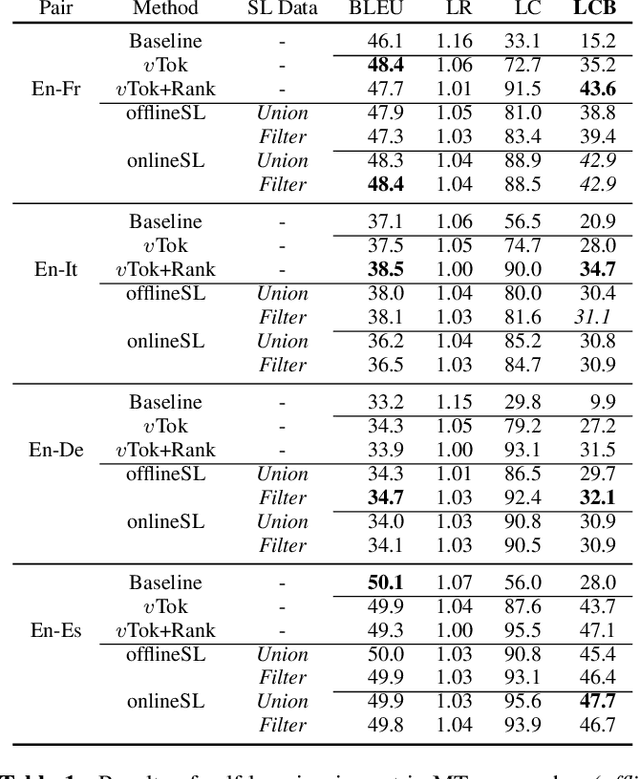
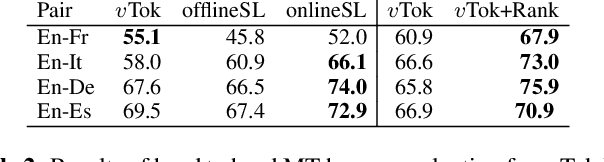
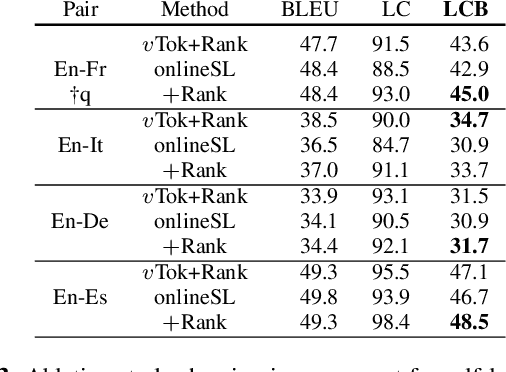
Automatic dubbing (AD) is among the use cases where translations should fit a given length template in order to achieve synchronicity between source and target speech. For neural machine translation (MT), generating translations of length close to the source length (e.g. within +-10% in character count), while preserving quality is a challenging task. Controlling NMT output length comes at a cost to translation quality which is usually mitigated with a two step approach of generation of n-best hypotheses and then re-ranking them based on length and quality. This work, introduces a self-learning approach that allows a transformer model to directly learn to generate outputs that closely match the source length, in short isometric MT. In particular, our approach for isometric MT does not require to generate multiple hypotheses nor any auxiliary scoring function. We report results on four language pairs (English - French, Italian, German, Spanish) with a publicly available benchmark based on TED Talk data. Both automatic and manual evaluations show that our self-learning approach to performs on par with more complex isometric MT approaches.