 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-resource Speech Translation and Recognition with LLMs
Dec 24, 2024


Despite recent advancements in speech processing, zero-resource speech translation (ST) and automatic speech recognition (ASR) remain challenging problems. In this work, we propose to leverage a multilingual Large Language Model (LLM) to perform ST and ASR in languages for which the model has never seen paired audio-text data. We achieve this by using a pre-trained multilingual speech encoder, a multilingual LLM, and a lightweight adaptation module that maps the audio representations to the token embedding space of the LLM. We perform several experiments both in ST and ASR to understand how to best train the model and what data has the most impact on performance in previously unseen languages. In ST, our best model is capable to achieve BLEU scores over 23 in CoVoST2 for two previously unseen languages, while in ASR, we achieve WERs of up to 28.2\%. We finally show that the performance of our system is bounded by the ability of the LLM to output text in the desired language.
Improving Lip-synchrony in Direct Audio-Visual Speech-to-Speech Translation
Dec 21, 2024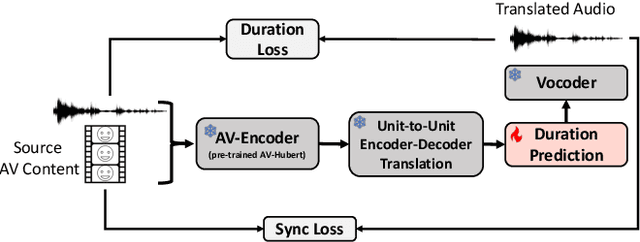



Audio-Visual Speech-to-Speech Translation typically prioritizes improving translation quality and naturalness. However, an equally critical aspect in audio-visual content is lip-synchrony-ensuring that the movements of the lips match the spoken content-essential for maintaining realism in dubbed videos. Despite its importance, the inclusion of lip-synchrony constraints in AVS2S models has been largely overlooked. This study addresses this gap by integrating a lip-synchrony loss into the training process of AVS2S models. Our proposed method significantly enhances lip-synchrony in direct audio-visual speech-to-speech translation, achieving an average LSE-D score of 10.67, representing a 9.2% reduction in LSE-D over a strong baseline across four language pairs. Additionally, it maintains the naturalness and high quality of the translated speech when overlaid onto the original video, without any degradation in translation quality.
Findings of the IWSLT 2024 Evaluation Campaign
Nov 07, 2024This paper reports on the shared tasks organized by the 21st IWSLT Conference. The shared tasks address 7 scientific challenges in spoken language translation: simultaneous and offline translation, automatic subtitling and dubbing, speech-to-speech translation, dialect and low-resource speech translation, and Indic languages. The shared tasks attracted 18 teams whose submissions are documented in 26 system papers. The growing interest towards spoken language translation is also witnessed by the constantly increasing number of shared task organizers and contributors to the overview paper, almost evenly distributed across industry and academia.
SpeechVerse: A Large-scale Generalizable Audio Language Model
May 14, 2024



Large language models (LLMs) have shown incredible proficiency in performing tasks that require semantic understanding of natural language instructions. Recently, many works have further expanded this capability to perceive multimodal audio and text inputs, but their capabilities are often limited to specific fine-tuned tasks such as automatic speech recognition and translation. We therefore develop SpeechVerse, a robust multi-task training and curriculum learning framework that combines pre-trained speech and text foundation models via a small set of learnable parameters, while keeping the pre-trained models frozen during training. The models are instruction finetuned using continuous latent representations extracted from the speech foundation model to achieve optimal zero-shot performance on a diverse range of speech processing tasks using natural language instructions. We perform extensive benchmarking that includes comparing our model performance against traditional baselines across several datasets and tasks. Furthermore, we evaluate the model's capability for generalized instruction following by testing on out-of-domain datasets, novel prompts, and unseen tasks. Our empirical experiments reveal that our multi-task SpeechVerse model is even superior to conventional task-specific baselines on 9 out of the 11 tasks.
PEAVS: Perceptual Evaluation of Audio-Visual Synchrony Grounded in Viewers' Opinion Scores
Apr 10, 2024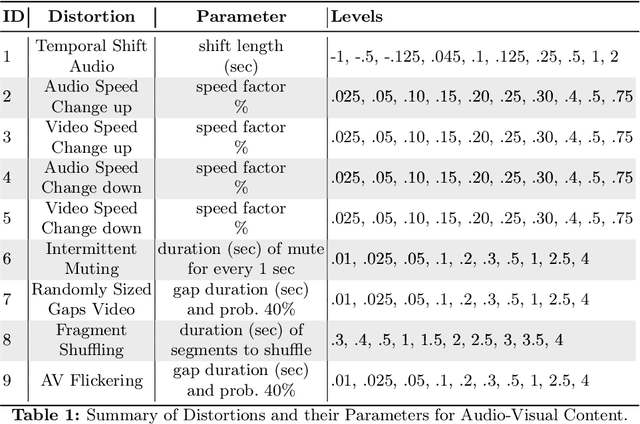
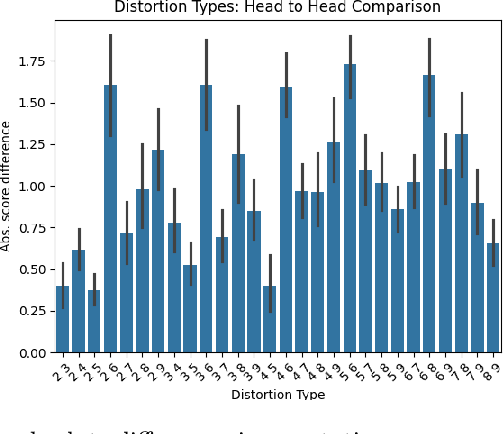
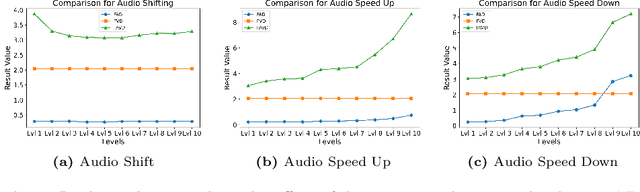
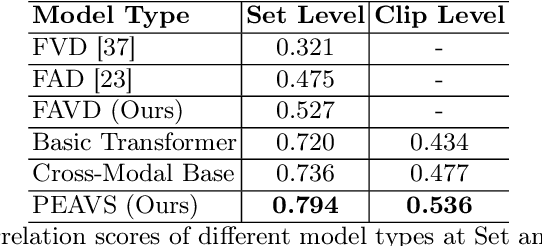
Recent advancements in audio-visual generative modeling have been propelled by progress in deep learning and the availability of data-rich benchmarks. However, the growth is not attributed solely to models and benchmarks. Universally accepted evaluation metrics also play an important role in advancing the field. While there are many metrics available to evaluate audio and visual content separately, there is a lack of metrics that offer a quantitative and interpretable measure of audio-visual synchronization for videos "in the wild". To address this gap, we first created a large scale human annotated dataset (100+ hrs) representing nine types of synchronization errors in audio-visual content and how human perceive them. We then developed a PEAVS (Perceptual Evaluation of Audio-Visual Synchrony) score, a novel automatic metric with a 5-point scale that evaluates the quality of audio-visual synchronization. We validate PEAVS using a newly generated dataset, achieving a Pearson correlation of 0.79 at the set level and 0.54 at the clip level when compared to human labels. In our experiments, we observe a relative gain 50% over a natural extension of Fr\'echet based metrics for Audio-Visual synchrony, confirming PEAVS efficacy in objectively modeling subjective perceptions of audio-visual synchronization for videos "in the wild".
End-to-End Single-Channel Speaker-Turn Aware Conversational Speech Translation
Nov 01, 2023



Conventional speech-to-text translation (ST) systems are trained on single-speaker utterances, and they may not generalize to real-life scenarios where the audio contains conversations by multiple speakers. In this paper, we tackle single-channel multi-speaker conversational ST with an end-to-end and multi-task training model, named Speaker-Turn Aware Conversational Speech Translation, that combines automatic speech recognition, speech translation and speaker turn detection using special tokens in a serialized labeling format. We run experiments on the Fisher-CALLHOME corpus, which we adapted by merging the two single-speaker channels into one multi-speaker channel, thus representing the more realistic and challenging scenario with multi-speaker turns and cross-talk. Experimental results across single- and multi-speaker conditions and against conventional ST systems, show that our model outperforms the reference systems on the multi-speaker condition, while attaining comparable performance on the single-speaker condition. We release scripts for data processing and model training.
Improving Isochronous Machine Translation with Target Factors and Auxiliary Counters
May 22, 2023



To translate speech for automatic dubbing, machine translation needs to be isochronous, i.e. translated speech needs to be aligned with the source in terms of speech durations. We introduce target factors in a transformer model to predict durations jointly with target language phoneme sequences. We also introduce auxiliary counters to help the decoder to keep track of the timing information while generating target phonemes. We show that our model improves translation quality and isochrony compared to previous work where the translation model is instead trained to predict interleaved sequences of phonemes and durations.
Jointly Optimizing Translations and Speech Timing to Improve Isochrony in Automatic Dubbing
Feb 25, 2023



Automatic dubbing (AD) is the task of translating the original speech in a video into target language speech. The new target language speech should satisfy isochrony; that is, the new speech should be time aligned with the original video, including mouth movements, pauses, hand gestures, etc. In this paper, we propose training a model that directly optimizes both the translation as well as the speech duration of the generated translations. We show that this system generates speech that better matches the timing of the original speech, compared to prior work, while simplifying the system architecture.
Improving Robustness of Retrieval Augmented Translation via Shuffling of Suggestions
Oct 11, 2022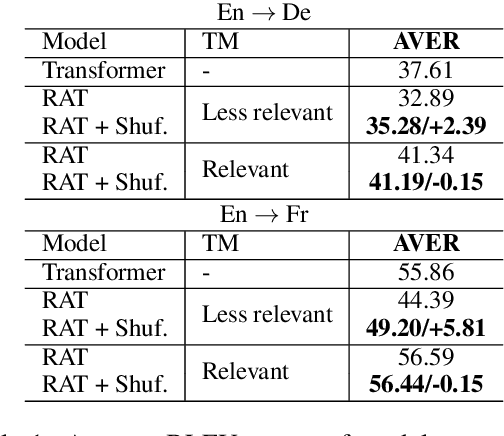

Several recent studies have reported dramatic performance improvements in neural machine translation (NMT) by augmenting translation at inference time with fuzzy-matches retrieved from a translation memory (TM). However, these studies all operate under the assumption that the TMs available at test time are highly relevant to the testset. We demonstrate that for existing retrieval augmented translation methods, using a TM with a domain mismatch to the test set can result in substantially worse performance compared to not using a TM at all. We propose a simple method to expose fuzzy-match NMT systems during training and show that it results in a system that is much more tolerant (regaining up to 5.8 BLEU) to inference with TMs with domain mismatch. Also, the model is still competitive to the baseline when fed with suggestions from relevant TMs.
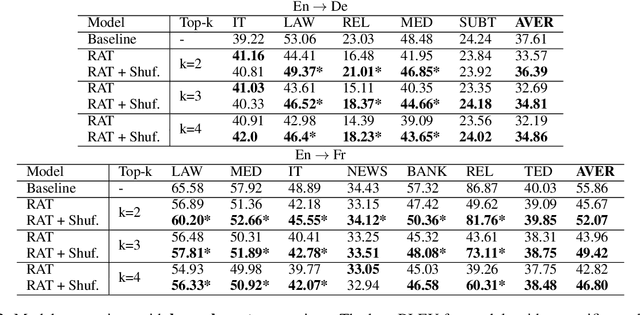
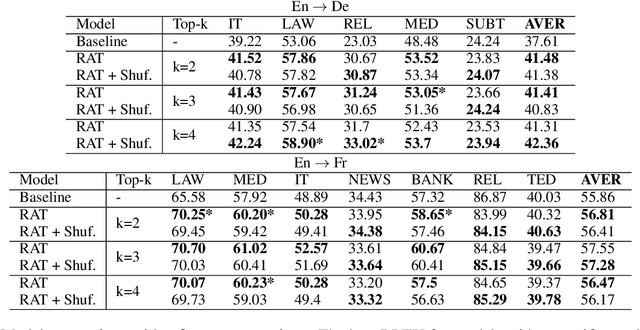
Improving Retrieval Augmented Neural Machine Translation by Controlling Source and Fuzzy-Match Interactions
Oct 10, 2022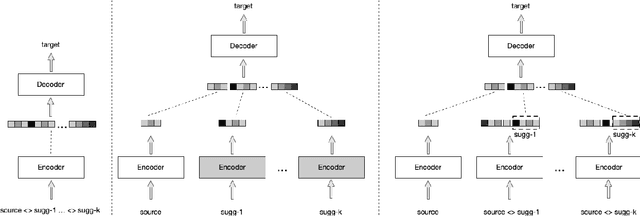
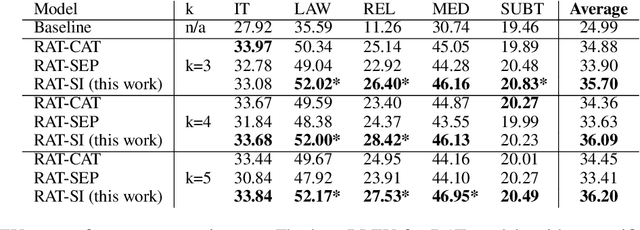
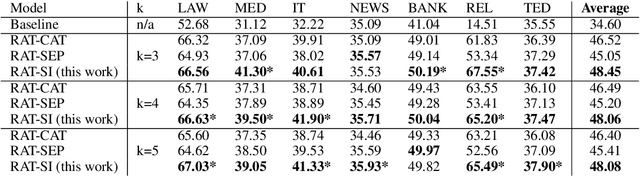
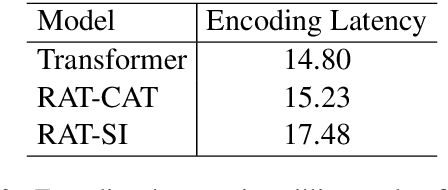
We explore zero-shot adaptation, where a general-domain model has access to customer or domain specific parallel data at inference time, but not during training. We build on the idea of Retrieval Augmented Translation (RAT) where top-k in-domain fuzzy matches are found for the source sentence, and target-language translations of those fuzzy-matched sentences are provided to the translation model at inference time. We propose a novel architecture to control interactions between a source sentence and the top-k fuzzy target-language matches, and compare it to architectures from prior work. We conduct experiments in two language pairs (En-De and En-Fr) by training models on WMT data and testing them with five and seven multi-domain datasets, respectively. Our approach consistently outperforms the alternative architectures, improving BLEU across language pair, domain, and number k of fuzzy matches.