 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePEAVS: Perceptual Evaluation of Audio-Visual Synchrony Grounded in Viewers' Opinion Scores
Apr 10, 2024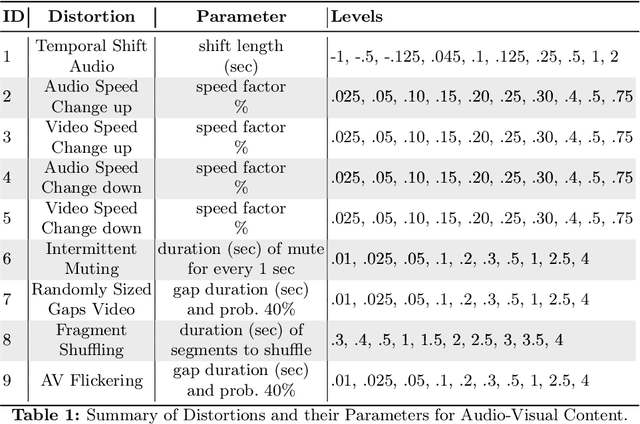
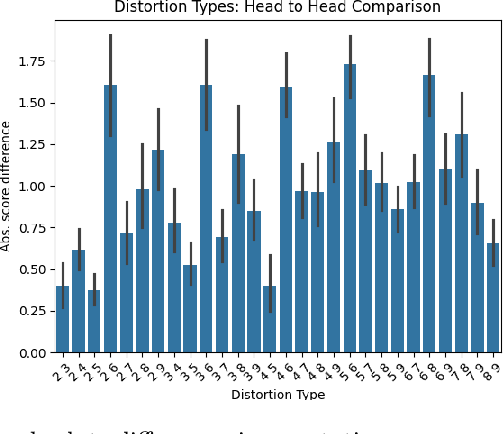
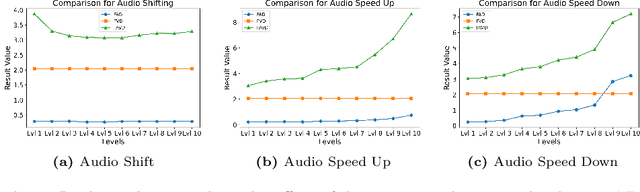
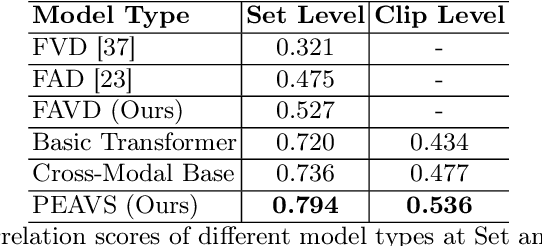
Recent advancements in audio-visual generative modeling have been propelled by progress in deep learning and the availability of data-rich benchmarks. However, the growth is not attributed solely to models and benchmarks. Universally accepted evaluation metrics also play an important role in advancing the field. While there are many metrics available to evaluate audio and visual content separately, there is a lack of metrics that offer a quantitative and interpretable measure of audio-visual synchronization for videos "in the wild". To address this gap, we first created a large scale human annotated dataset (100+ hrs) representing nine types of synchronization errors in audio-visual content and how human perceive them. We then developed a PEAVS (Perceptual Evaluation of Audio-Visual Synchrony) score, a novel automatic metric with a 5-point scale that evaluates the quality of audio-visual synchronization. We validate PEAVS using a newly generated dataset, achieving a Pearson correlation of 0.79 at the set level and 0.54 at the clip level when compared to human labels. In our experiments, we observe a relative gain 50% over a natural extension of Fr\'echet based metrics for Audio-Visual synchrony, confirming PEAVS efficacy in objectively modeling subjective perceptions of audio-visual synchronization for videos "in the wild".
Neuro-Inspired Deep Neural Networks with Sparse, Strong Activations
Apr 12, 2022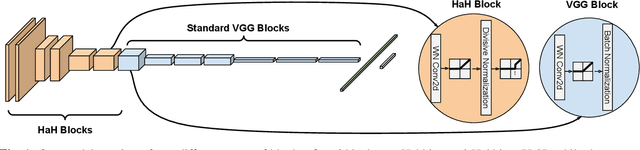

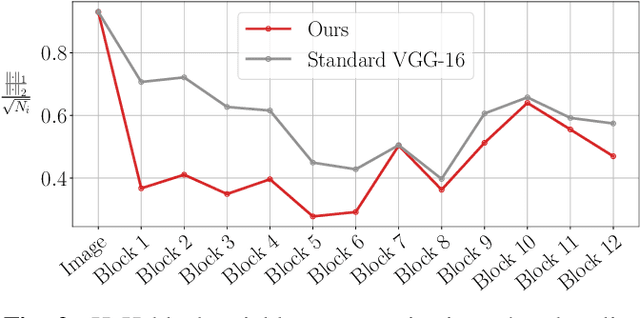
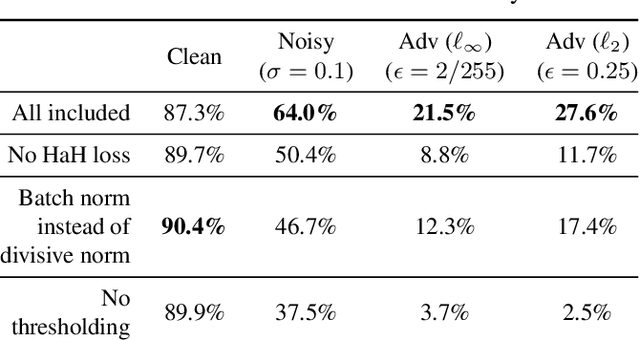
While end-to-end training of Deep Neural Networks (DNNs) yields state of the art performance in an increasing array of applications, it does not provide insight into, or control over, the features being extracted. We report here on a promising neuro-inspired approach to DNNs with sparser and stronger activations. We use standard stochastic gradient training, supplementing the end-to-end discriminative cost function with layer-wise costs promoting Hebbian ("fire together," "wire together") updates for highly active neurons, and anti-Hebbian updates for the remaining neurons. Instead of batch norm, we use divisive normalization of activations (suppressing weak outputs using strong outputs), along with implicit $\ell_2$ normalization of neuronal weights. Experiments with standard image classification tasks on CIFAR-10 demonstrate that, relative to baseline end-to-end trained architectures, our proposed architecture (a) leads to sparser activations (with only a slight compromise on accuracy), (b) exhibits more robustness to noise (without being trained on noisy data), (c) exhibits more robustness to adversarial perturbations (without adversarial training).
Self-supervised Speaker Recognition Training Using Human-Machine Dialogues
Feb 07, 2022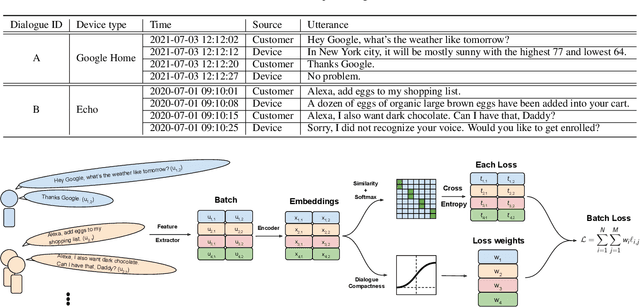

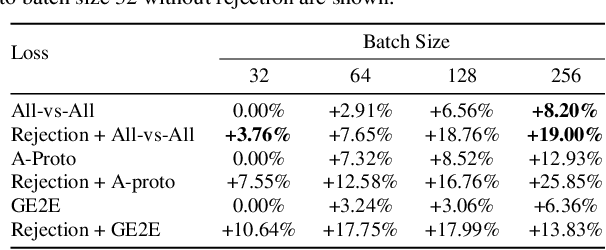

Speaker recognition, recognizing speaker identities based on voice alone, enables important downstream applications, such as personalization and authentication. Learning speaker representations, in the context of supervised learning, heavily depends on both clean and sufficient labeled data, which is always difficult to acquire. Noisy unlabeled data, on the other hand, also provides valuable information that can be exploited using self-supervised training methods. In this work, we investigate how to pretrain speaker recognition models by leveraging dialogues between customers and smart-speaker devices. However, the supervisory information in such dialogues is inherently noisy, as multiple speakers may speak to a device in the course of the same dialogue. To address this issue, we propose an effective rejection mechanism that selectively learns from dialogues based on their acoustic homogeneity. Both reconstruction-based and contrastive-learning-based self-supervised methods are compared. Experiments demonstrate that the proposed method provides significant performance improvements, superior to earlier work. Dialogue pretraining when combined with the rejection mechanism yields 27.10% equal error rate (EER) reduction in speaker recognition, compared to a model without self-supervised pretraining.
Sparse Coding Frontend for Robust Neural Networks
Apr 12, 2021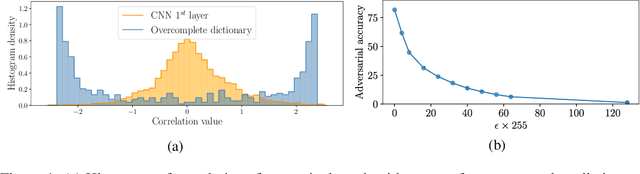

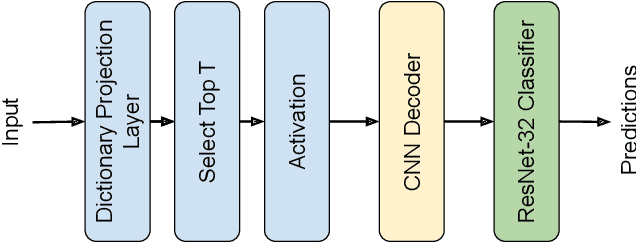
Deep Neural Networks are known to be vulnerable to small, adversarially crafted, perturbations. The current most effective defense methods against these adversarial attacks are variants of adversarial training. In this paper, we introduce a radically different defense trained only on clean images: a sparse coding based frontend which significantly attenuates adversarial attacks before they reach the classifier. We evaluate our defense on CIFAR-10 dataset under a wide range of attack types (including Linf , L2, and L1 bounded attacks), demonstrating its promise as a general-purpose approach for defense.
A Neuro-Inspired Autoencoding Defense Against Adversarial Perturbations
Dec 21, 2020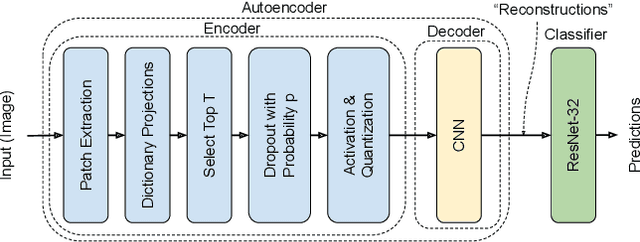

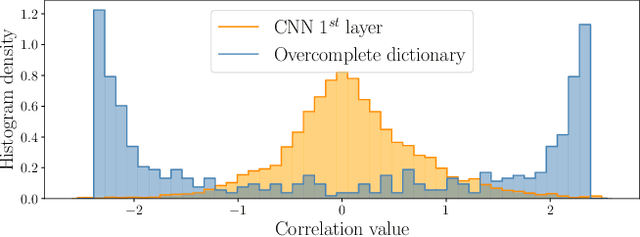
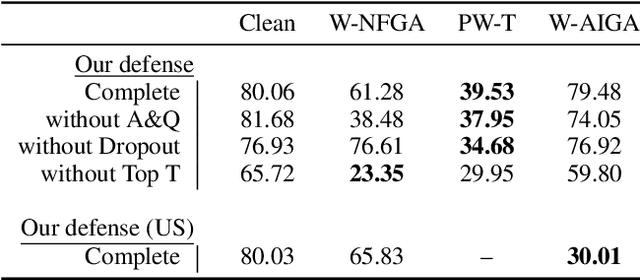
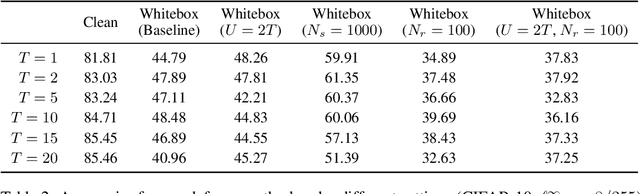
Deep Neural Networks (DNNs) are vulnerable to adversarial attacks: carefully constructed perturbations to an image can seriously impair classification accuracy, while being imperceptible to humans. While there has been a significant amount of research on defending against such attacks, most defenses based on systematic design principles have been defeated by appropriately modified attacks. For a fixed set of data, the most effective current defense is to train the network using adversarially perturbed examples. In this paper, we investigate a radically different, neuro-inspired defense mechanism, starting from the observation that human vision is virtually unaffected by adversarial examples designed for machines. We aim to reject L^inf bounded adversarial perturbations before they reach a classifier DNN, using an encoder with characteristics commonly observed in biological vision: sparse overcomplete representations, randomness due to synaptic noise, and drastic nonlinearities. Encoder training is unsupervised, using standard dictionary learning. A CNN-based decoder restores the size of the encoder output to that of the original image, enabling the use of a standard CNN for classification. Our nominal design is to train the decoder and classifier together in standard supervised fashion, but we also consider unsupervised decoder training based on a regression objective (as in a conventional autoencoder) with separate supervised training of the classifier. Unlike adversarial training, all training is based on clean images. Our experiments on the CIFAR-10 show performance competitive with state-of-the-art defenses based on adversarial training, and point to the promise of neuro-inspired techniques for the design of robust neural networks. In addition, we provide results for a subset of the Imagenet dataset to verify that our approach scales to larger images.
Robust Wireless Fingerprinting: Generalizing Across Space and Time
Feb 25, 2020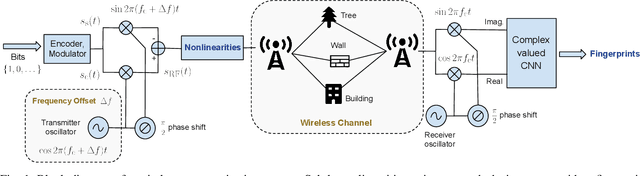
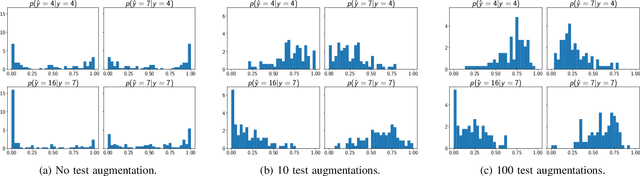
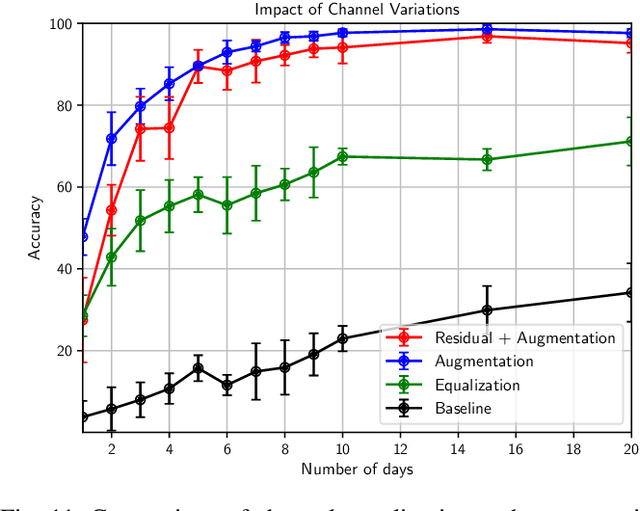
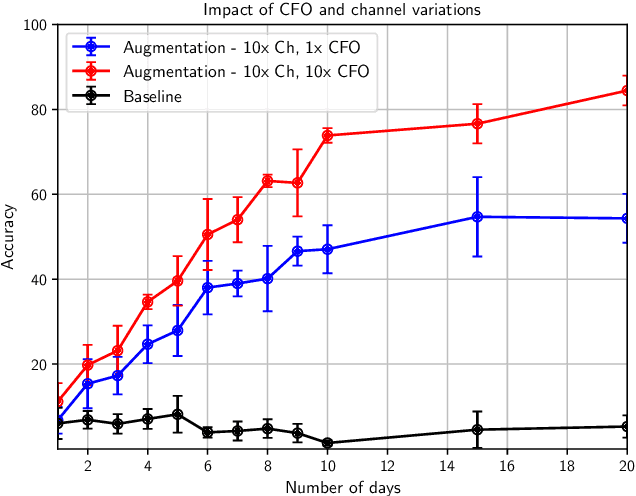
Can we distinguish between two wireless transmitters sending exactly the same message, using the same protocol? The opportunity for doing so arises due to subtle nonlinear variations across transmitters, even those made by the same manufacturer. Since these effects are difficult to model explicitly, we investigate learning device fingerprints using complex-valued deep neural networks (DNNs) that take as input the complex baseband signal at the receiver. Such fingerprints should be robust to ID spoofing, and to distribution shifts across days and locations due to clock drift and variations in the wireless channel. In this paper, we point out that, unless proactively discouraged from doing so, DNNs learn these strong confounding features rather than the subtle nonlinear characteristics that are the basis for stable signatures. Thus, a network trained on data collected during one day performs poorly on a different day, and networks allowed access to post-preamble information rely on easily-spoofed ID fields. We propose and evaluate strategies, based on augmentation and estimation, to promote generalization across realizations of these confounding factors, using data from WiFi and ADS-B protocols. We conclude that, while DNN training has the advantage of not requiring explicit signal models, significant modeling insights are required to focus the learning on the effects we wish to capture.
Polarizing Front Ends for Robust CNNs
Feb 22, 2020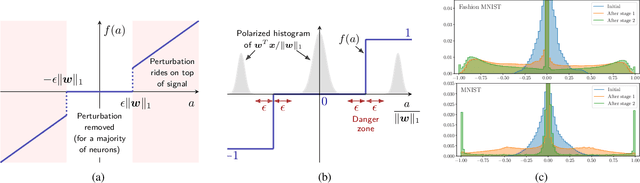
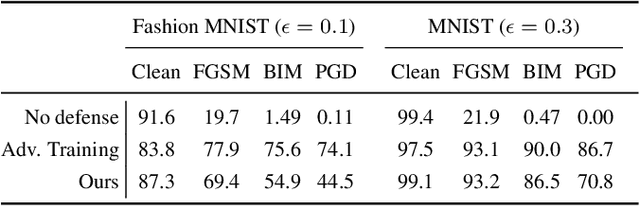
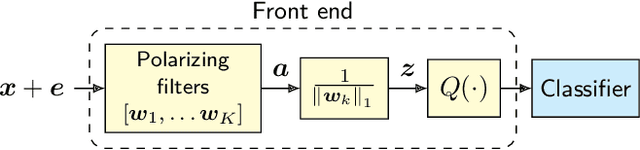
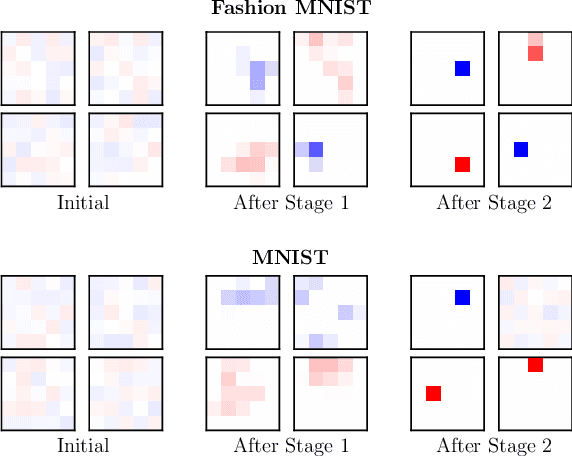
The vulnerability of deep neural networks to small, adversarially designed perturbations can be attributed to their "excessive linearity." In this paper, we propose a bottom-up strategy for attenuating adversarial perturbations using a nonlinear front end which polarizes and quantizes the data. We observe that ideal polarization can be utilized to completely eliminate perturbations, develop algorithms to learn approximately polarizing bases for data, and investigate the effectiveness of the proposed strategy on the MNIST and Fashion MNIST datasets.
Robust Wireless Fingerprinting via Complex-Valued Neural Networks
May 19, 2019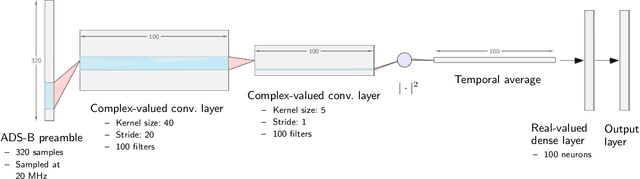

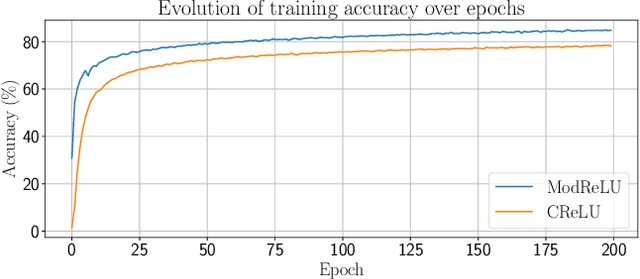
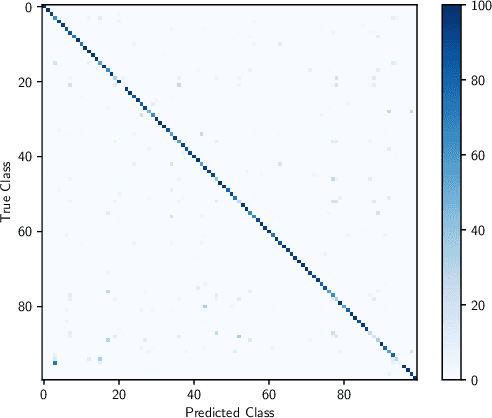
A "wireless fingerprint" which exploits hardware imperfections unique to each device is a potentially powerful tool for wireless security. Such a fingerprint should be able to distinguish between devices sending the same message, and should be robust against standard spoofing techniques. Since the information in wireless signals resides in complex baseband, in this paper, we explore the use of neural networks with complex-valued weights to learn fingerprints using supervised learning. We demonstrate that, while there are potential benefits to using sections of the signal beyond just the preamble to learn fingerprints, the network cheats when it can, using information such as transmitter ID (which can be easily spoofed) to artificially inflate performance. We also show that noise augmentation by inserting additional white Gaussian noise can lead to significant performance gains, which indicates that this counter-intuitive strategy helps in learning more robust fingerprints. We provide results for two different wireless protocols, WiFi and ADS-B, demonstrating the effectiveness of the proposed method.