 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Wireless Fingerprinting: Generalizing Across Space and Time
Feb 25, 2020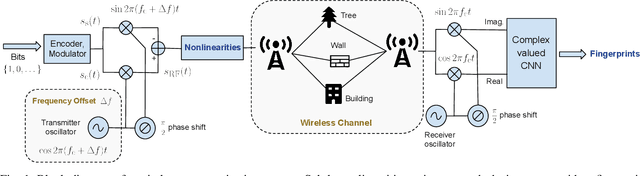
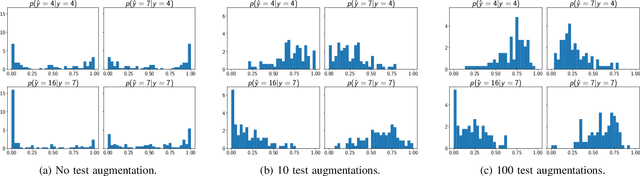
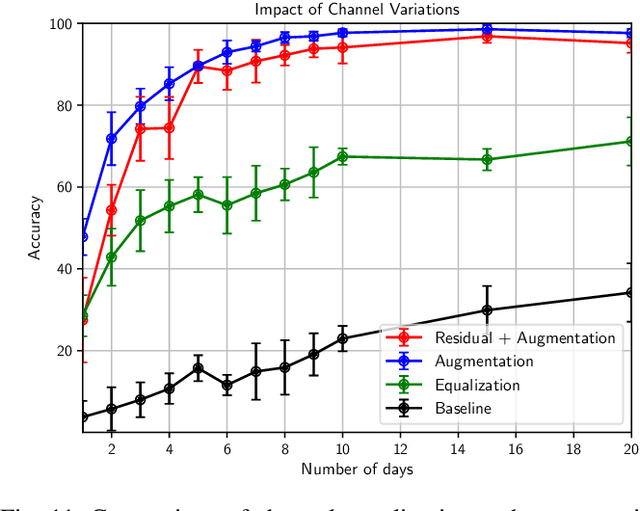
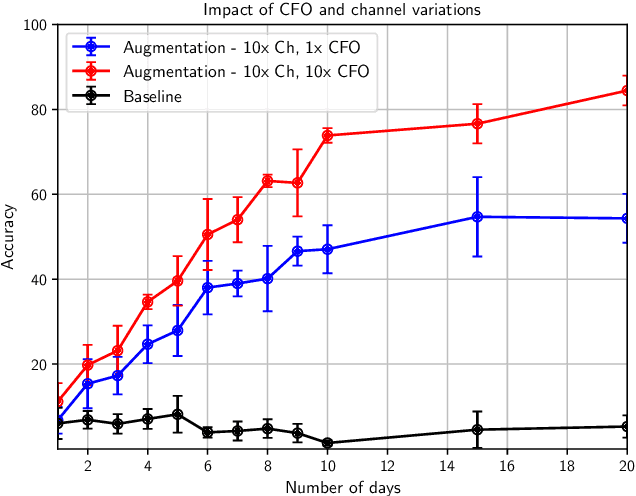
Can we distinguish between two wireless transmitters sending exactly the same message, using the same protocol? The opportunity for doing so arises due to subtle nonlinear variations across transmitters, even those made by the same manufacturer. Since these effects are difficult to model explicitly, we investigate learning device fingerprints using complex-valued deep neural networks (DNNs) that take as input the complex baseband signal at the receiver. Such fingerprints should be robust to ID spoofing, and to distribution shifts across days and locations due to clock drift and variations in the wireless channel. In this paper, we point out that, unless proactively discouraged from doing so, DNNs learn these strong confounding features rather than the subtle nonlinear characteristics that are the basis for stable signatures. Thus, a network trained on data collected during one day performs poorly on a different day, and networks allowed access to post-preamble information rely on easily-spoofed ID fields. We propose and evaluate strategies, based on augmentation and estimation, to promote generalization across realizations of these confounding factors, using data from WiFi and ADS-B protocols. We conclude that, while DNN training has the advantage of not requiring explicit signal models, significant modeling insights are required to focus the learning on the effects we wish to capture.
Polarizing Front Ends for Robust CNNs
Feb 22, 2020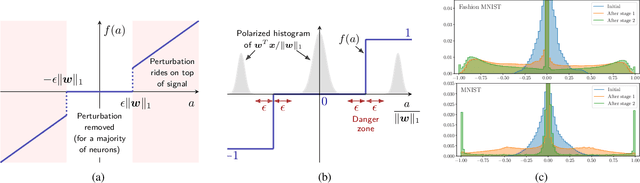
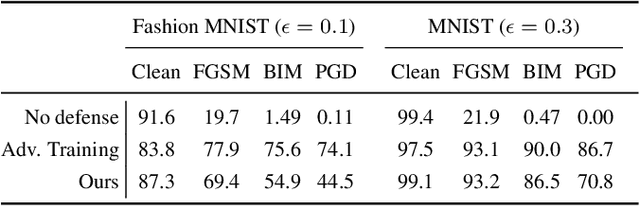
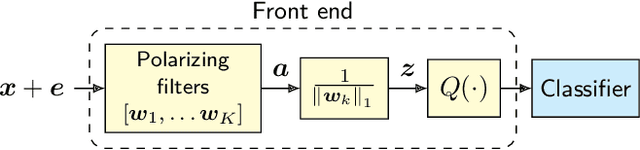
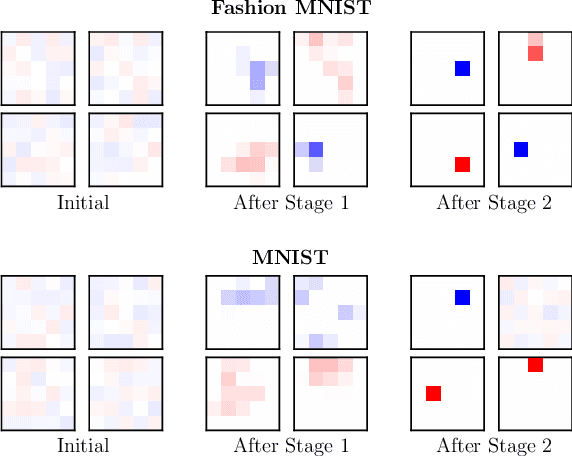
The vulnerability of deep neural networks to small, adversarially designed perturbations can be attributed to their "excessive linearity." In this paper, we propose a bottom-up strategy for attenuating adversarial perturbations using a nonlinear front end which polarizes and quantizes the data. We observe that ideal polarization can be utilized to completely eliminate perturbations, develop algorithms to learn approximately polarizing bases for data, and investigate the effectiveness of the proposed strategy on the MNIST and Fashion MNIST datasets.
Robust Wireless Fingerprinting via Complex-Valued Neural Networks
May 19, 2019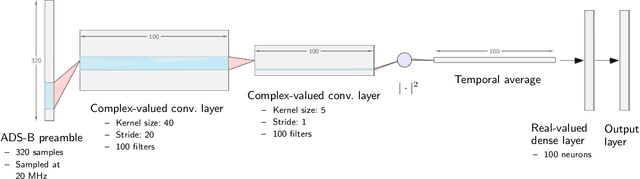

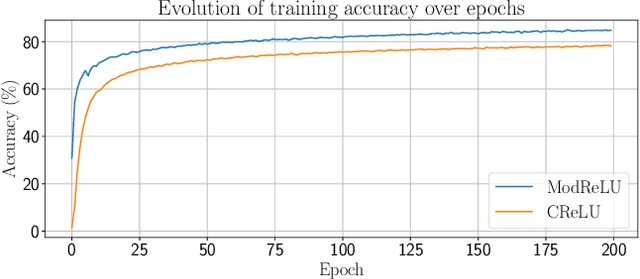
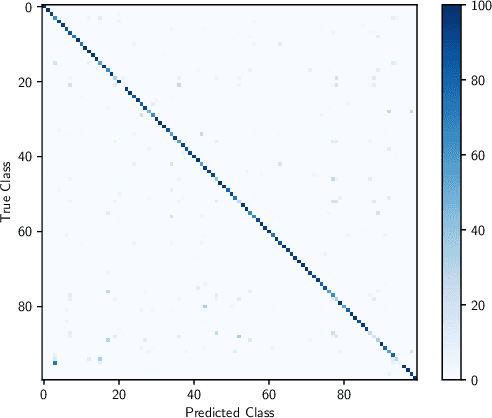
A "wireless fingerprint" which exploits hardware imperfections unique to each device is a potentially powerful tool for wireless security. Such a fingerprint should be able to distinguish between devices sending the same message, and should be robust against standard spoofing techniques. Since the information in wireless signals resides in complex baseband, in this paper, we explore the use of neural networks with complex-valued weights to learn fingerprints using supervised learning. We demonstrate that, while there are potential benefits to using sections of the signal beyond just the preamble to learn fingerprints, the network cheats when it can, using information such as transmitter ID (which can be easily spoofed) to artificially inflate performance. We also show that noise augmentation by inserting additional white Gaussian noise can lead to significant performance gains, which indicates that this counter-intuitive strategy helps in learning more robust fingerprints. We provide results for two different wireless protocols, WiFi and ADS-B, demonstrating the effectiveness of the proposed method.
Toward Robust Neural Networks via Sparsification
Oct 24, 2018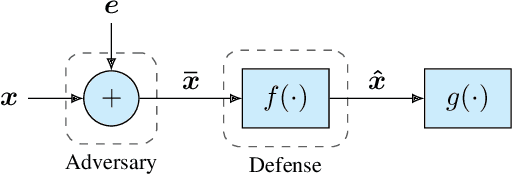

It is by now well-known that small adversarial perturbations can induce classification errors in deep neural networks. In this paper, we make the case that a systematic exploitation of sparsity is key to defending against such attacks, and that a "locally linear" model for neural networks can be used to develop a theoretical foundation for crafting attacks and defenses. We consider two defenses. The first is a sparsifying front end, which attenuates the impact of the attack by a factor of roughly $K/N$ where $N$ is the data dimension and $K$ is the sparsity level. The second is sparsification of network weights, which attenuates the worst-case growth of an attack as it flows up the network. We also devise attacks based on the locally linear model that outperform the well-known FGSM attack. We provide experimental results for the MNIST and Fashion-MNIST datasets, showing the efficacy of the proposed sparsity-based defenses.
Combating Adversarial Attacks Using Sparse Representations
Jul 13, 2018

It is by now well-known that small adversarial perturbations can induce classification errors in deep neural networks (DNNs). In this paper, we make the case that sparse representations of the input data are a crucial tool for combating such attacks. For linear classifiers, we show that a sparsifying front end is provably effective against $\ell_{\infty}$-bounded attacks, reducing output distortion due to the attack by a factor of roughly $K / N$ where $N$ is the data dimension and $K$ is the sparsity level. We then extend this concept to DNNs, showing that a "locally linear" model can be used to develop a theoretical foundation for crafting attacks and defenses. Experimental results for the MNIST dataset show the efficacy of the proposed sparsifying front end.
Sparsity-based Defense against Adversarial Attacks on Linear Classifiers
Jun 19, 2018

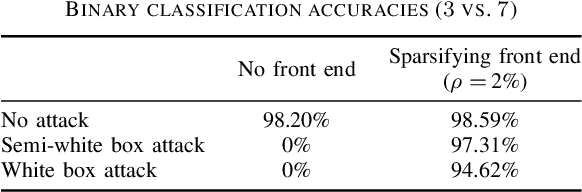
Deep neural networks represent the state of the art in machine learning in a growing number of fields, including vision, speech and natural language processing. However, recent work raises important questions about the robustness of such architectures, by showing that it is possible to induce classification errors through tiny, almost imperceptible, perturbations. Vulnerability to such "adversarial attacks", or "adversarial examples", has been conjectured to be due to the excessive linearity of deep networks. In this paper, we study this phenomenon in the setting of a linear classifier, and show that it is possible to exploit sparsity in natural data to combat $\ell_{\infty}$-bounded adversarial perturbations. Specifically, we demonstrate the efficacy of a sparsifying front end via an ensemble averaged analysis, and experimental results for the MNIST handwritten digit database. To the best of our knowledge, this is the first work to show that sparsity provides a theoretically rigorous framework for defense against adversarial attacks.