Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse Coding Frontend for Robust Neural Networks
Paper and Code
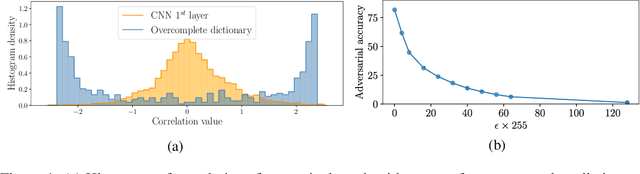

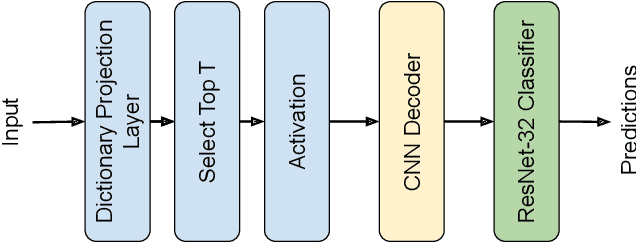
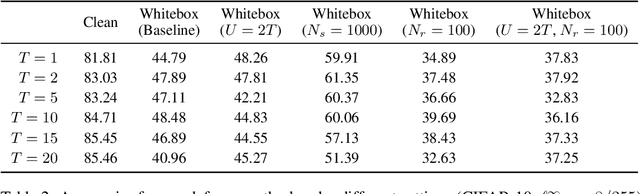
Deep Neural Networks are known to be vulnerable to small, adversarially crafted, perturbations. The current most effective defense methods against these adversarial attacks are variants of adversarial training. In this paper, we introduce a radically different defense trained only on clean images: a sparse coding based frontend which significantly attenuates adversarial attacks before they reach the classifier. We evaluate our defense on CIFAR-10 dataset under a wide range of attack types (including Linf , L2, and L1 bounded attacks), demonstrating its promise as a general-purpose approach for defense.
* International Conference on Learning Representations (ICLR) 2021
Workshop on Security and Safety in Machine Learning Systems
View paper on