 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Does Monolingual Data Help Multilingual Translation: The Role of Domain and Model Scale
May 23, 2023Multilingual machine translation (MMT), trained on a mixture of parallel and monolingual data, is key for improving translation in low-resource language pairs. However, the literature offers conflicting results on the performance of different methods. To resolve this, we examine how denoising autoencoding (DAE) and backtranslation (BT) impact MMT under different data conditions and model scales. Unlike prior studies, we use a realistic dataset of 100 directions and consider many domain combinations of monolingual and test data. We find that monolingual data generally helps MMT, but models are surprisingly brittle to domain mismatches, especially at smaller model scales. BT is beneficial when the parallel, monolingual, and test data sources are similar but can be detrimental otherwise, while DAE is less effective than previously reported. Next, we analyze the impact of scale (from 90M to 1.6B parameters) and find it is important for both methods, particularly DAE. As scale increases, DAE transitions from underperforming the parallel-only baseline at 90M to converging with BT performance at 1.6B, and even surpassing it in low-resource. These results offer new insights into how to best use monolingual data in MMT.
Automatic Evaluation and Analysis of Idioms in Neural Machine Translation
Oct 10, 2022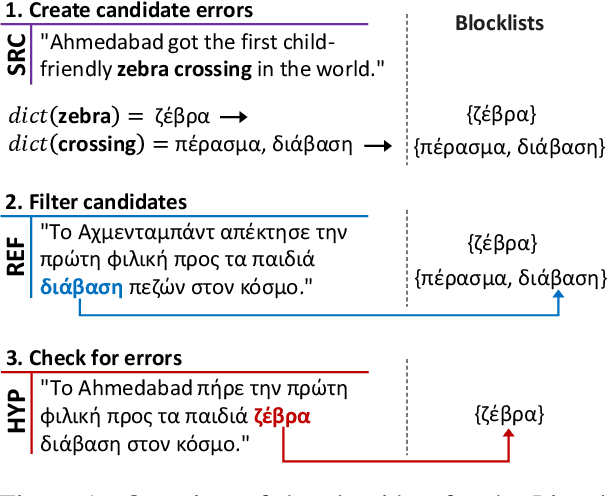

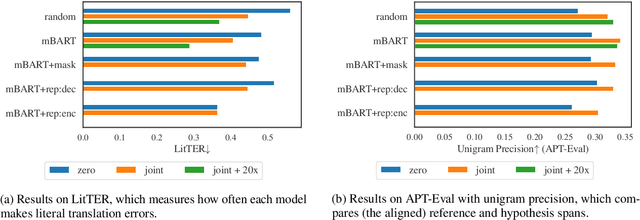
A major open problem in neural machine translation (NMT) is the translation of idiomatic expressions, such as "under the weather". The meaning of these expressions is not composed by the meaning of their constituent words, and NMT models tend to translate them literally (i.e., word-by-word), which leads to confusing and nonsensical translations. Research on idioms in NMT is limited and obstructed by the absence of automatic methods for quantifying these errors. In this work, first, we propose a novel metric for automatically measuring the frequency of literal translation errors without human involvement. Equipped with this metric, we present controlled translation experiments with models trained in different conditions (with/without the test-set idioms) and across a wide range of (global and targeted) metrics and test sets. We explore the role of monolingual pretraining and find that it yields substantial targeted improvements, even without observing any translation examples of the test-set idioms. In our analysis, we probe the role of idiom context. We find that the randomly initialized models are more local or "myopic" as they are relatively unaffected by variations of the idiom context, unlike the pretrained ones.
Multilingual Machine Translation with Hyper-Adapters
May 22, 2022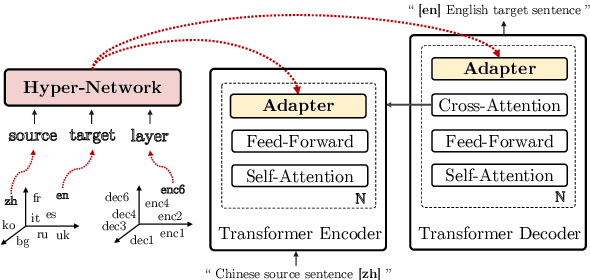
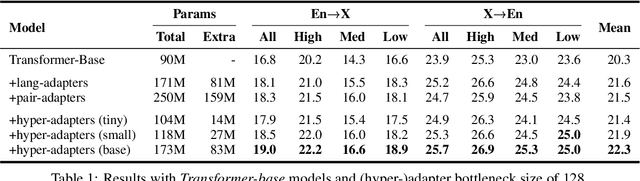
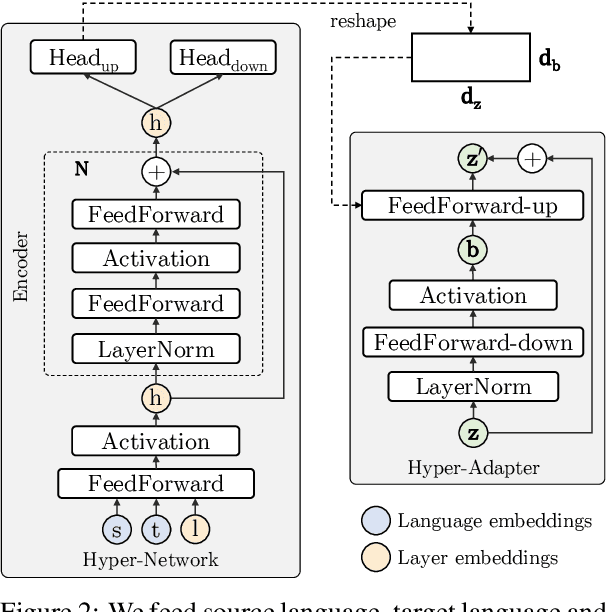
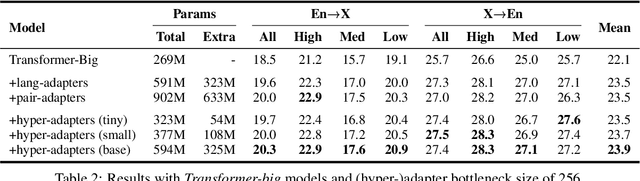
Multilingual machine translation suffers from negative interference across languages. A common solution is to relax parameter sharing with language-specific modules like adapters. However, adapters of related languages are unable to transfer information, and their total number of parameters becomes prohibitively expensive as the number of languages grows. In this work, we overcome these drawbacks using hyper-adapters -- hyper-networks that generate adapters from language and layer embeddings. While past work had poor results when scaling hyper-networks, we propose a rescaling fix that significantly improves convergence and enables training larger hyper-networks. We find that hyper-adapters are more parameter efficient than regular adapters, reaching the same performance with up to 12 times less parameters. When using the same number of parameters and FLOPS, our approach consistently outperforms regular adapters. Also, hyper-adapters converge faster than alternative approaches and scale better than regular dense networks. Our analysis shows that hyper-adapters learn to encode language relatedness, enabling positive transfer across languages.
Exploring Unsupervised Pretraining Objectives for Machine Translation
Jun 10, 2021


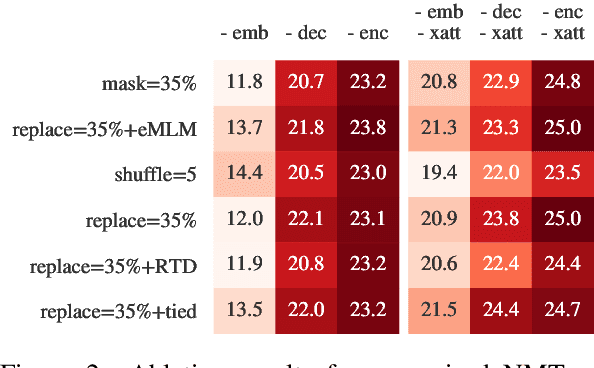
Unsupervised cross-lingual pretraining has achieved strong results in neural machine translation (NMT), by drastically reducing the need for large parallel data. Most approaches adapt masked-language modeling (MLM) to sequence-to-sequence architectures, by masking parts of the input and reconstructing them in the decoder. In this work, we systematically compare masking with alternative objectives that produce inputs resembling real (full) sentences, by reordering and replacing words based on their context. We pretrain models with different methods on English$\leftrightarrow$German, English$\leftrightarrow$Nepali and English$\leftrightarrow$Sinhala monolingual data, and evaluate them on NMT. In (semi-) supervised NMT, varying the pretraining objective leads to surprisingly small differences in the finetuned performance, whereas unsupervised NMT is much more sensitive to it. To understand these results, we thoroughly study the pretrained models using a series of probes and verify that they encode and use information in different ways. We conclude that finetuning on parallel data is mostly sensitive to few properties that are shared by most models, such as a strong decoder, in contrast to unsupervised NMT that also requires models with strong cross-lingual abilities.
Language Model Prior for Low-Resource Neural Machine Translation
Apr 30, 2020

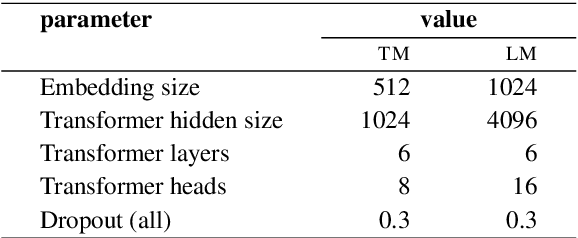

The scarcity of large parallel corpora is an important obstacle for neural machine translation. A common solution is to exploit the knowledge of language models (LM) trained on abundant monolingual data. In this work, we propose a novel approach to incorporate a LM as prior in a neural translation model (TM). Specifically, we add a regularization term, which pushes the output distributions of the TM to be probable under the LM prior, while avoiding wrong predictions when the TM "disagrees" with the LM. This objective relates to knowledge distillation, where the LM can be viewed as teaching the TM about the target language. The proposed approach does not compromise decoding speed, because the LM is used only at training time, unlike previous work that requires it during inference. We present an analysis of the effects that different methods have on the distributions of the TM. Results on two low-resource machine translation datasets show clear improvements even with limited monolingual data.
Attention-based Conditioning Methods for External Knowledge Integration
Jun 09, 2019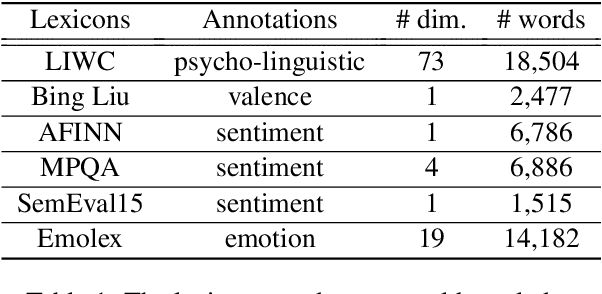


In this paper, we present a novel approach for incorporating external knowledge in Recurrent Neural Networks (RNNs). We propose the integration of lexicon features into the self-attention mechanism of RNN-based architectures. This form of conditioning on the attention distribution, enforces the contribution of the most salient words for the task at hand. We introduce three methods, namely attentional concatenation, feature-based gating and affine transformation. Experiments on six benchmark datasets show the effectiveness of our methods. Attentional feature-based gating yields consistent performance improvement across tasks. Our approach is implemented as a simple add-on module for RNN-based models with minimal computational overhead and can be adapted to any deep neural architecture.
An Embarrassingly Simple Approach for Transfer Learning from Pretrained Language Models
Apr 10, 2019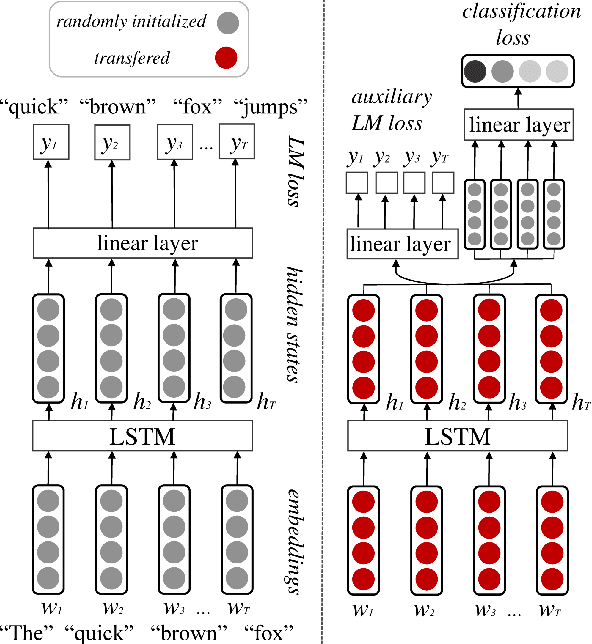



A growing number of state-of-the-art transfer learning methods employ language models pretrained on large generic corpora. In this paper we present a conceptually simple and effective transfer learning approach that addresses the problem of catastrophic forgetting. Specifically, we combine the task-specific optimization function with an auxiliary language model objective, which is adjusted during the training process. This preserves language regularities captured by language models, while enabling sufficient adaptation for solving the target task. Our method does not require pretraining or finetuning separate components of the network and we train our models end-to-end in a single step. We present results on a variety of challenging affective and text classification tasks, surpassing well established transfer learning methods with greater level of complexity.
SEQ^3: Differentiable Sequence-to-Sequence-to-Sequence Autoencoder for Unsupervised Abstractive Sentence Compression
Apr 07, 2019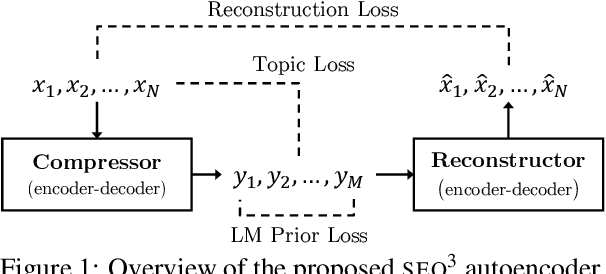


Neural sequence-to-sequence models are currently the dominant approach in several natural language processing tasks, but require large parallel corpora. We present a sequence-to-sequence-to-sequence autoencoder (SEQ^3), consisting of two chained encoder-decoder pairs, with words used as a sequence of discrete latent variables. We apply the proposed model to unsupervised abstractive sentence compression, where the first and last sequences are the input and reconstructed sentences, respectively, while the middle sequence is the compressed sentence. Constraining the length of the latent word sequences forces the model to distill important information from the input. A pretrained language model, acting as a prior over the latent sequences, encourages the compressed sentences to be human-readable. Continuous relaxations enable us to sample from categorical distributions, allowing gradient-based optimization, unlike alternatives that rely on reinforcement learning. The proposed model does not require parallel text-summary pairs, achieving promising results in unsupervised sentence compression on benchmark datasets.
Integrating Recurrence Dynamics for Speech Emotion Recognition
Nov 09, 2018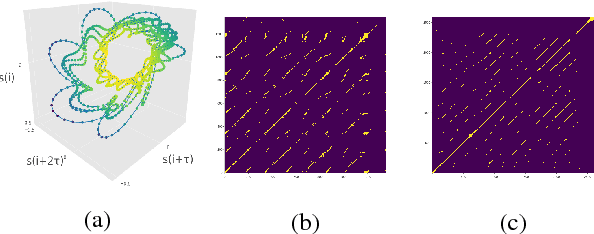



We investigate the performance of features that can capture nonlinear recurrence dynamics embedded in the speech signal for the task of Speech Emotion Recognition (SER). Reconstruction of the phase space of each speech frame and the computation of its respective Recurrence Plot (RP) reveals complex structures which can be measured by performing Recurrence Quantification Analysis (RQA). These measures are aggregated by using statistical functionals over segment and utterance periods. We report SER results for the proposed feature set on three databases using different classification methods. When fusing the proposed features with traditional feature sets, we show an improvement in unweighted accuracy of up to 5.7% and 10.7% on Speaker-Dependent (SD) and Speaker-Independent (SI) SER tasks, respectively, over the baseline. Following a segment-based approach we demonstrate state-of-the-art performance on IEMOCAP using a Bidirectional Recurrent Neural Network.
NTUA-SLP at IEST 2018: Ensemble of Neural Transfer Methods for Implicit Emotion Classification
Sep 03, 2018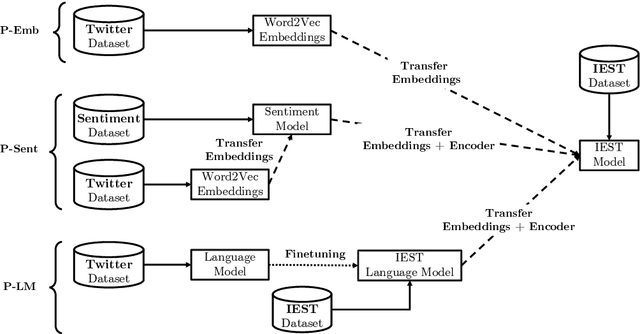
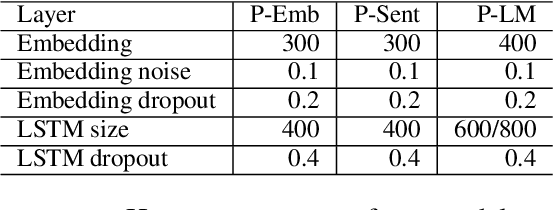


In this paper we present our approach to tackle the Implicit Emotion Shared Task (IEST) organized as part of WASSA 2018 at EMNLP 2018. Given a tweet, from which a certain word has been removed, we are asked to predict the emotion of the missing word. In this work, we experiment with neural Transfer Learning (TL) methods. Our models are based on LSTM networks, augmented with a self-attention mechanism. We use the weights of various pretrained models, for initializing specific layers of our networks. We leverage a big collection of unlabeled Twitter messages, for pretraining word2vec word embeddings and a set of diverse language models. Moreover, we utilize a sentiment analysis dataset for pretraining a model, which encodes emotion related information. The submitted model consists of an ensemble of the aforementioned TL models. Our team ranked 3rd out of 30 participants, achieving an F1 score of 0.703.