 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Unsupervised Pretraining Objectives for Machine Translation
Paper and Code



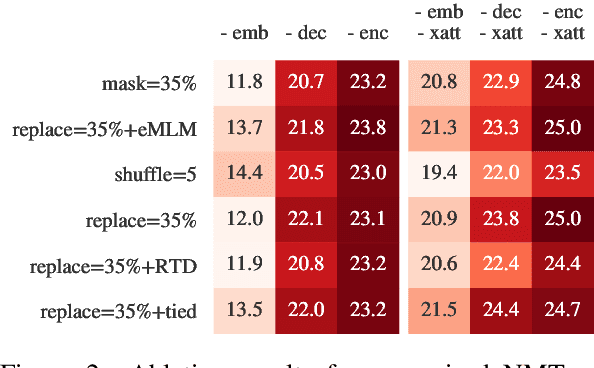
Unsupervised cross-lingual pretraining has achieved strong results in neural machine translation (NMT), by drastically reducing the need for large parallel data. Most approaches adapt masked-language modeling (MLM) to sequence-to-sequence architectures, by masking parts of the input and reconstructing them in the decoder. In this work, we systematically compare masking with alternative objectives that produce inputs resembling real (full) sentences, by reordering and replacing words based on their context. We pretrain models with different methods on English$\leftrightarrow$German, English$\leftrightarrow$Nepali and English$\leftrightarrow$Sinhala monolingual data, and evaluate them on NMT. In (semi-) supervised NMT, varying the pretraining objective leads to surprisingly small differences in the finetuned performance, whereas unsupervised NMT is much more sensitive to it. To understand these results, we thoroughly study the pretrained models using a series of probes and verify that they encode and use information in different ways. We conclude that finetuning on parallel data is mostly sensitive to few properties that are shared by most models, such as a strong decoder, in contrast to unsupervised NMT that also requires models with strong cross-lingual abilities.