 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSURF: Separation via Unsupervised Remixing Flow
Jun 03, 2026The goal of single-channel source separation is to reconstruct $K$ sources given their mixture. In supervised settings where vast amounts of clean source data are available, this challenging, ill-posed problem has been addressed successfully by generative diffusion and flow-based prior models. However, access to such clean source samples is often limited, and even when available, supervised models are vulnerable to domain shifts. To bridge this gap, we present Separation via Unsupervised Remixing Flow (SURF), an unsupervised flow matching approach for source separation that learns directly from observed mixtures. This method relies on a novel combination of state-of-the-art supervised flow matching and regression-based self-supervised techniques. At a high level, starting from a teacher model, we utilize a "remixing" step to bootstrap the learning of a student flow model from the teacher's estimates. We provide insights into the objectives optimized by this approach and draw a novel connection to the Wake-Sleep algorithm. Empirical evaluations on image and audio benchmarks demonstrate that SURF establishes a new state-of-the-art, significantly outperforming existing unsupervised methods. See our demo page for examples. https://google.github.io/df-conformer/surf/
Complete and separate: Conditional separation with missing target source attribute completion
Jul 27, 2023



Recent approaches in source separation leverage semantic information about their input mixtures and constituent sources that when used in conditional separation models can achieve impressive performance. Most approaches along these lines have focused on simple descriptions, which are not always useful for varying types of input mixtures. In this work, we present an approach in which a model, given an input mixture and partial semantic information about a target source, is trained to extract additional semantic data. We then leverage this pre-trained model to improve the separation performance of an uncoupled multi-conditional separation network. Our experiments demonstrate that the separation performance of this multi-conditional model is significantly improved, approaching the performance of an oracle model with complete semantic information. Furthermore, our approach achieves performance levels that are comparable to those of the best performing specialized single conditional models, thus providing an easier to use alternative.
The CHiME-7 UDASE task: Unsupervised domain adaptation for conversational speech enhancement
Jul 07, 2023Supervised speech enhancement models are trained using artificially generated mixtures of clean speech and noise signals, which may not match real-world recording conditions at test time. This mismatch can lead to poor performance if the test domain significantly differs from the synthetic training domain. In this paper, we introduce the unsupervised domain adaptation for conversational speech enhancement (UDASE) task of the 7th CHiME challenge. This task aims to leverage real-world noisy speech recordings from the target test domain for unsupervised domain adaptation of speech enhancement models. The target test domain corresponds to the multi-speaker reverberant conversational speech recordings of the CHiME-5 dataset, for which the ground-truth clean speech reference is not available. Given a CHiME-5 recording, the task is to estimate the clean, potentially multi-speaker, reverberant speech, removing the additive background noise. We discuss the motivation for the CHiME-7 UDASE task and describe the data, the task, and the baseline system.
Latent Iterative Refinement for Modular Source Separation
Nov 22, 2022Traditional source separation approaches train deep neural network models end-to-end with all the data available at once by minimizing the empirical risk on the whole training set. On the inference side, after training the model, the user fetches a static computation graph and runs the full model on some specified observed mixture signal to get the estimated source signals. Additionally, many of those models consist of several basic processing blocks which are applied sequentially. We argue that we can significantly increase resource efficiency during both training and inference stages by reformulating a model's training and inference procedures as iterative mappings of latent signal representations. First, we can apply the same processing block more than once on its output to refine the input signal and consequently improve parameter efficiency. During training, we can follow a block-wise procedure which enables a reduction on memory requirements. Thus, one can train a very complicated network structure using significantly less computation compared to end-to-end training. During inference, we can dynamically adjust how many processing blocks and iterations of a specific block an input signal needs using a gating module.
Optimal Condition Training for Target Source Separation
Nov 11, 2022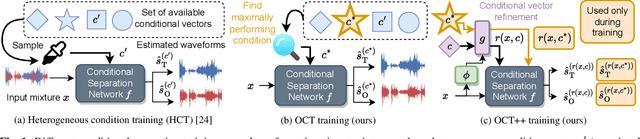
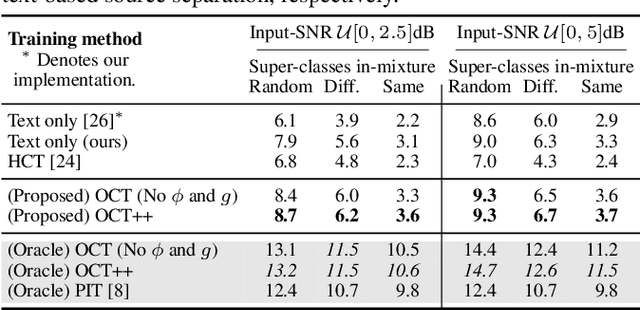
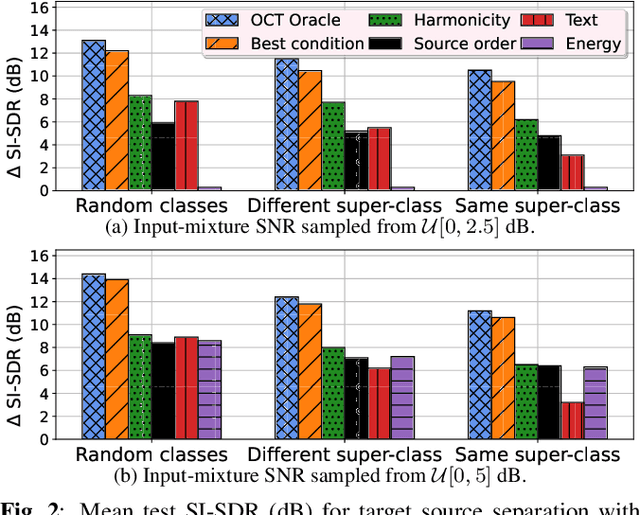
Recent research has shown remarkable performance in leveraging multiple extraneous conditional and non-mutually exclusive semantic concepts for sound source separation, allowing the flexibility to extract a given target source based on multiple different queries. In this work, we propose a new optimal condition training (OCT) method for single-channel target source separation, based on greedy parameter updates using the highest performing condition among equivalent conditions associated with a given target source. Our experiments show that the complementary information carried by the diverse semantic concepts significantly helps to disentangle and isolate sources of interest much more efficiently compared to single-conditioned models. Moreover, we propose a variation of OCT with condition refinement, in which an initial conditional vector is adapted to the given mixture and transformed to a more amenable representation for target source extraction. We showcase the effectiveness of OCT on diverse source separation experiments where it improves upon permutation invariant models with oracle assignment and obtains state-of-the-art performance in the more challenging task of text-based source separation, outperforming even dedicated text-only conditioned models.
AudioScopeV2: Audio-Visual Attention Architectures for Calibrated Open-Domain On-Screen Sound Separation
Jul 20, 2022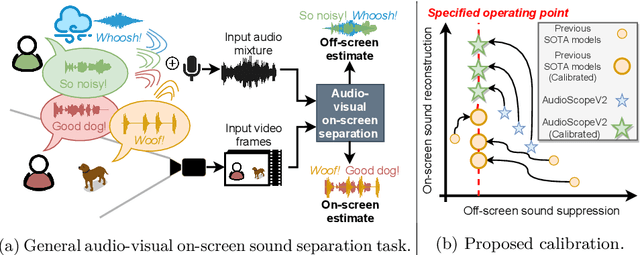
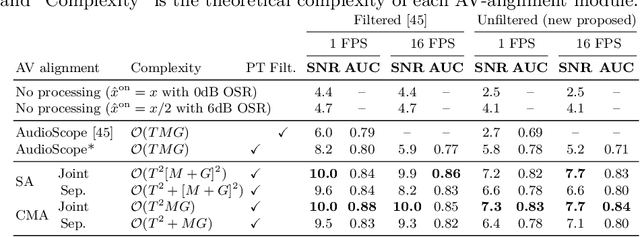
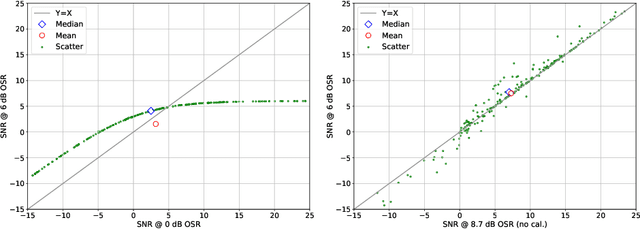
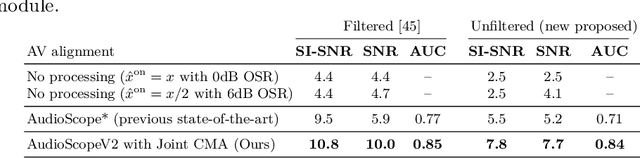
We introduce AudioScopeV2, a state-of-the-art universal audio-visual on-screen sound separation system which is capable of learning to separate sounds and associate them with on-screen objects by looking at in-the-wild videos. We identify several limitations of previous work on audio-visual on-screen sound separation, including the coarse resolution of spatio-temporal attention, poor convergence of the audio separation model, limited variety in training and evaluation data, and failure to account for the trade off between preservation of on-screen sounds and suppression of off-screen sounds. We provide solutions to all of these issues. Our proposed cross-modal and self-attention network architectures capture audio-visual dependencies at a finer resolution over time, and we also propose efficient separable variants that are capable of scaling to longer videos without sacrificing much performance. We also find that pre-training the separation model only on audio greatly improves results. For training and evaluation, we collected new human annotations of onscreen sounds from a large database of in-the-wild videos (YFCC100M). This new dataset is more diverse and challenging. Finally, we propose a calibration procedure that allows exact tuning of on-screen reconstruction versus off-screen suppression, which greatly simplifies comparing performance between models with different operating points. Overall, our experimental results show marked improvements in on-screen separation performance under much more general conditions than previous methods with minimal additional computational complexity.
Learning Representations for New Sound Classes With Continual Self-Supervised Learning
May 15, 2022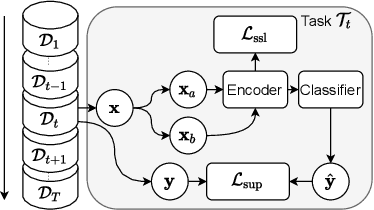
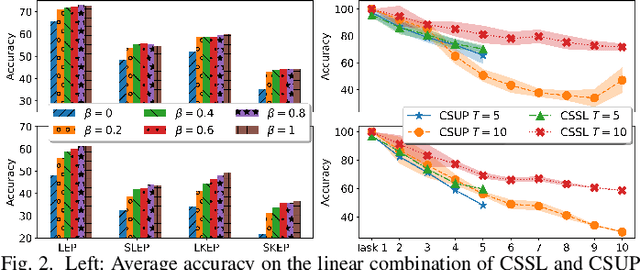
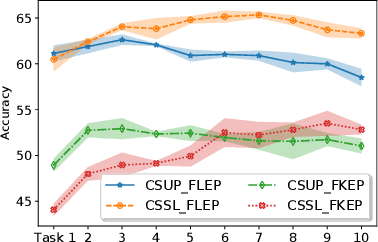
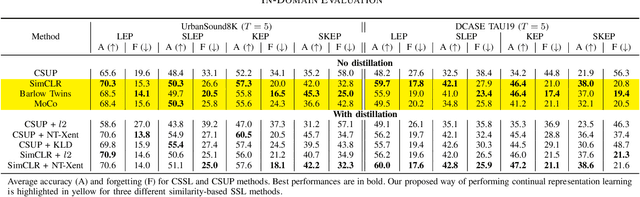
In this paper, we present a self-supervised learning framework for continually learning representations for new sound classes. The proposed system relies on a continually trained neural encoder that is trained with similarity-based learning objectives without using labels. We show that representations learned with the proposed method generalize better and are less susceptible to catastrophic forgetting than fully-supervised approaches. Remarkably, our technique does not store past data or models and is more computationally efficient than distillation-based methods. To accurately assess the system performance, in addition to using existing protocols, we propose two realistic evaluation protocols that use only a small amount of labeled data to simulate practical use cases.
Heterogeneous Target Speech Separation
Apr 07, 2022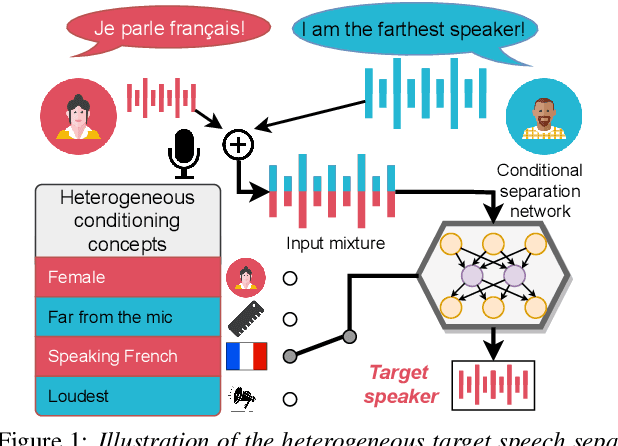
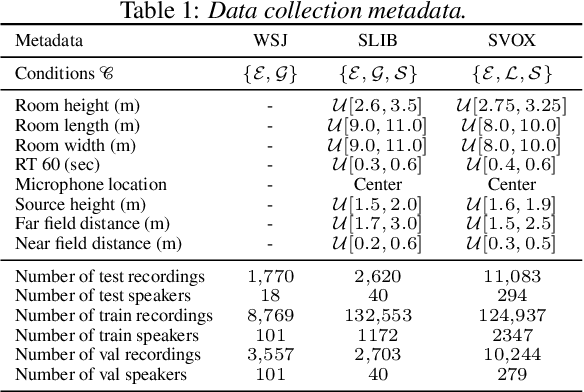
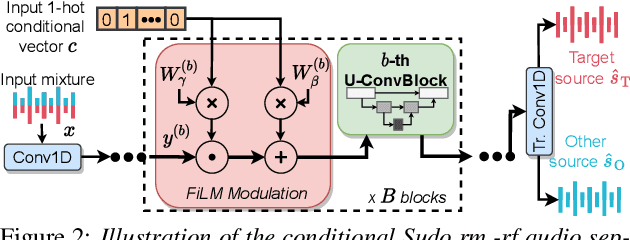
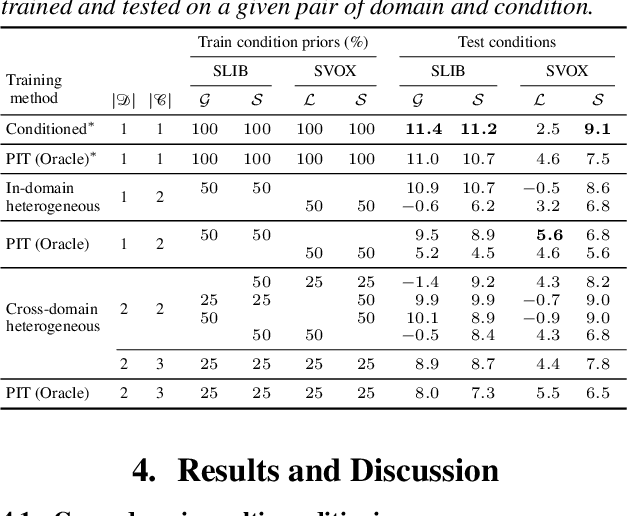
We introduce a new paradigm for single-channel target source separation where the sources of interest can be distinguished using non-mutually exclusive concepts (e.g., loudness, gender, language, spatial location, etc). Our proposed heterogeneous separation framework can seamlessly leverage datasets with large distribution shifts and learn cross-domain representations under a variety of concepts used as conditioning. Our experiments show that training separation models with heterogeneous conditions facilitates the generalization to new concepts with unseen out-of-domain data while also performing substantially higher than single-domain specialist models. Notably, such training leads to more robust learning of new harder source separation discriminative concepts and can yield improvements over permutation invariant training with oracle source selection. We analyze the intrinsic behavior of source separation training with heterogeneous metadata and propose ways to alleviate emerging problems with challenging separation conditions. We release the collection of preparation recipes for all datasets used to further promote research towards this challenging task.
RemixIT: Continual self-training of speech enhancement models via bootstrapped remixing
Feb 22, 2022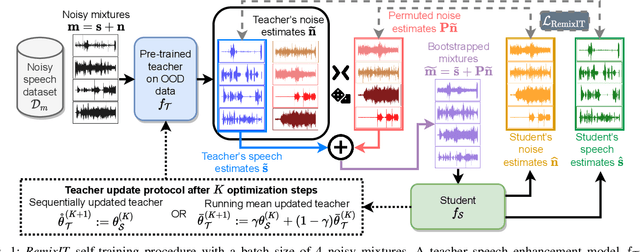
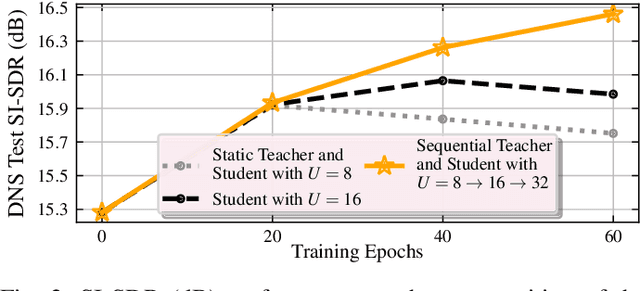
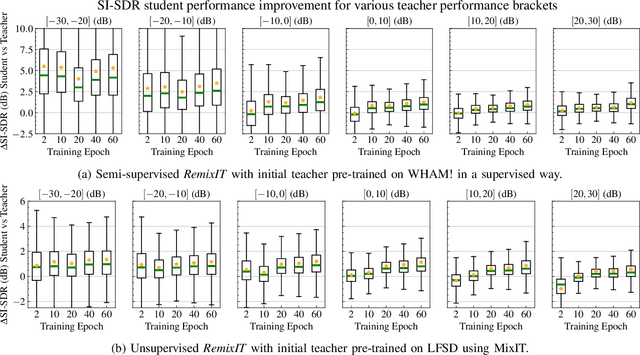
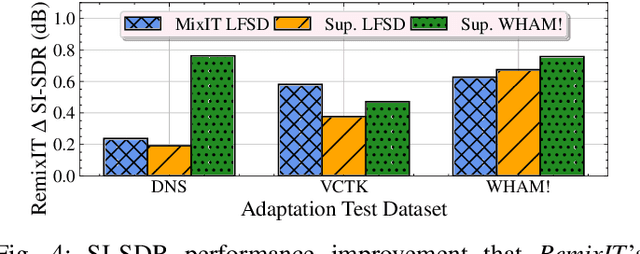
We present RemixIT, a simple yet effective self-supervised method for training speech enhancement without the need of a single isolated in-domain speech nor a noise waveform. Our approach overcomes limitations of previous methods which make them dependent on clean in-domain target signals and thus, sensitive to any domain mismatch between train and test samples. RemixIT is based on a continuous self-training scheme in which a pre-trained teacher model on out-of-domain data infers estimated pseudo-target signals for in-domain mixtures. Then, by permuting the estimated clean and noise signals and remixing them together, we generate a new set of bootstrapped mixtures and corresponding pseudo-targets which are used to train the student network. Vice-versa, the teacher periodically refines its estimates using the updated parameters of the latest student models. Experimental results on multiple speech enhancement datasets and tasks not only show the superiority of our method over prior approaches but also showcase that RemixIT can be combined with any separation model as well as be applied towards any semi-supervised and unsupervised domain adaptation task. Our analysis, paired with empirical evidence, sheds light on the inside functioning of our self-training scheme wherein the student model keeps obtaining better performance while observing severely degraded pseudo-targets.
Continual self-training with bootstrapped remixing for speech enhancement
Oct 19, 2021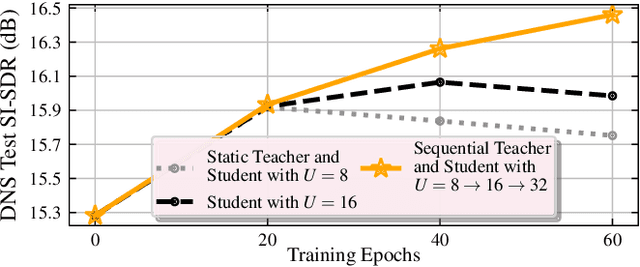
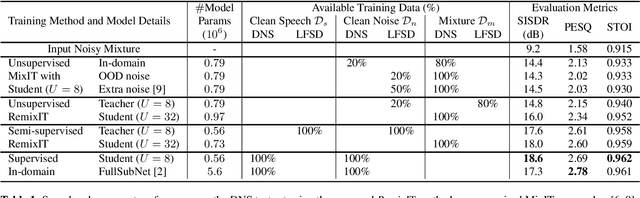
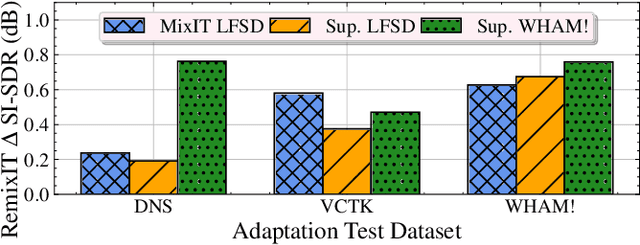
We propose RemixIT, a simple and novel self-supervised training method for speech enhancement. The proposed method is based on a continuously self-training scheme that overcomes limitations from previous studies including assumptions for the in-domain noise distribution and having access to clean target signals. Specifically, a separation teacher model is pre-trained on an out-of-domain dataset and is used to infer estimated target signals for a batch of in-domain mixtures. Next, we bootstrap the mixing process by generating artificial mixtures using permuted estimated clean and noise signals. Finally, the student model is trained using the permuted estimated sources as targets while we periodically update teacher's weights using the latest student model. Our experiments show that RemixIT outperforms several previous state-of-the-art self-supervised methods under multiple speech enhancement tasks. Additionally, RemixIT provides a seamless alternative for semi-supervised and unsupervised domain adaptation for speech enhancement tasks, while being general enough to be applied to any separation task and paired with any separation model.