 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Representations for New Sound Classes With Continual Self-Supervised Learning
Paper and Code
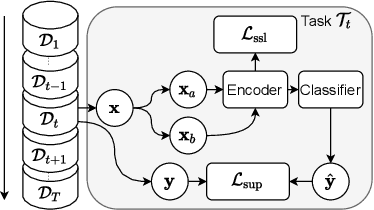
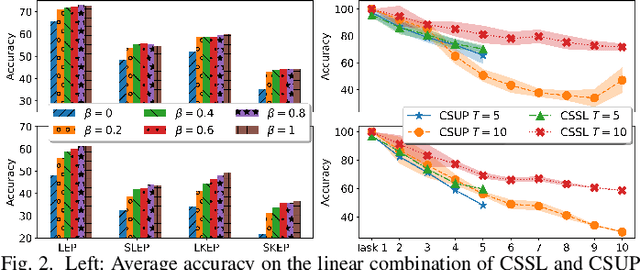
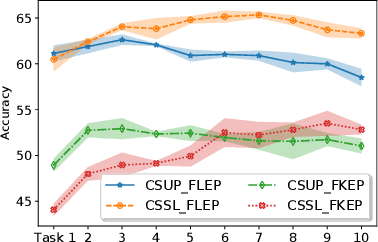
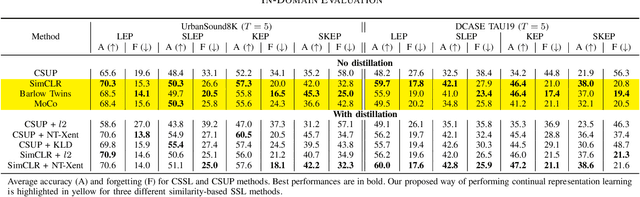
In this paper, we present a self-supervised learning framework for continually learning representations for new sound classes. The proposed system relies on a continually trained neural encoder that is trained with similarity-based learning objectives without using labels. We show that representations learned with the proposed method generalize better and are less susceptible to catastrophic forgetting than fully-supervised approaches. Remarkably, our technique does not store past data or models and is more computationally efficient than distillation-based methods. To accurately assess the system performance, in addition to using existing protocols, we propose two realistic evaluation protocols that use only a small amount of labeled data to simulate practical use cases.