 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving On-Screen Sound Separation for Open Domain Videos with Audio-Visual Self-attention
Paper and Code
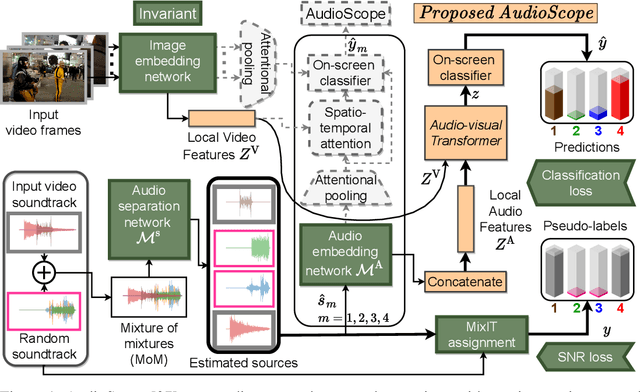
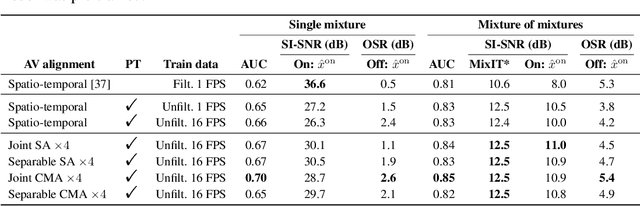
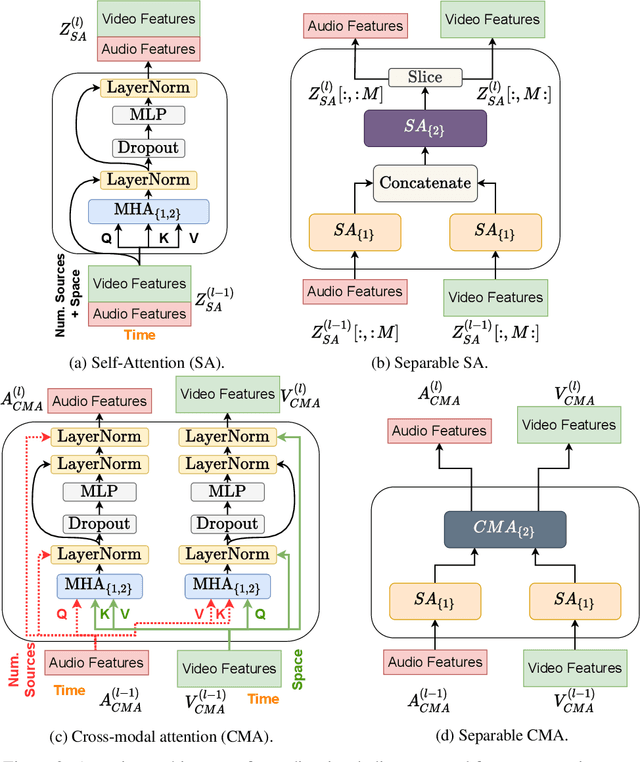
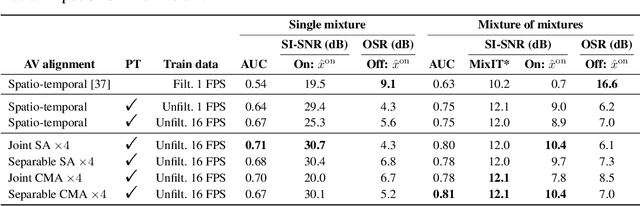
We introduce a state-of-the-art audio-visual on-screen sound separation system which is capable of learning to separate sounds and associate them with on-screen objects by looking at in-the-wild videos. We identify limitations of previous work on audiovisual on-screen sound separation, including the simplicity and coarse resolution of spatio-temporal attention, and poor convergence of the audio separation model. Our proposed model addresses these issues using cross-modal and self-attention modules that capture audio-visual dependencies at a finer resolution over time, and by unsupervised pre-training of audio separation model. These improvements allow the model to generalize to a much wider set of unseen videos. For evaluation and semi-supervised training, we collected human annotations of on-screen audio from a large database of in-the-wild videos (YFCC100M). Our results show marked improvements in on-screen separation performance, in more general conditions than previous methods.