 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperbolic Audio Source Separation
Dec 09, 2022We introduce a framework for audio source separation using embeddings on a hyperbolic manifold that compactly represent the hierarchical relationship between sound sources and time-frequency features. Inspired by recent successes modeling hierarchical relationships in text and images with hyperbolic embeddings, our algorithm obtains a hyperbolic embedding for each time-frequency bin of a mixture signal and estimates masks using hyperbolic softmax layers. On a synthetic dataset containing mixtures of multiple people talking and musical instruments playing, our hyperbolic model performed comparably to a Euclidean baseline in terms of source to distortion ratio, with stronger performance at low embedding dimensions. Furthermore, we find that time-frequency regions containing multiple overlapping sources are embedded towards the center (i.e., the most uncertain region) of the hyperbolic space, and we can use this certainty estimate to efficiently trade-off between artifact introduction and interference reduction when isolating individual sounds.
Towards End-to-end Speaker Diarization in the Wild
Nov 02, 2022



Speaker diarization algorithms address the "who spoke when" problem in audio recordings. Algorithms trained end-to-end have proven superior to classical modular-cascaded systems in constrained scenarios with a small number of speakers. However, their performance for in-the-wild recordings containing more speakers with shorter utterance lengths remains to be investigated. In this paper, we address this gap, showing that an attractor-based end-to-end system can also perform remarkably well in the latter scenario when first pre-trained on a carefully-designed simulated dataset that matches the distribution of in-the-wild recordings. We also propose to use an attention mechanism to increase the network capacity in decoding more speaker attractors, and to jointly train the attractors on a speaker recognition task to improve the speaker attractor representation. Even though the model we propose is audio-only, we find it significantly outperforms both audio-only and audio-visual baselines on the AVA-AVD benchmark dataset, achieving state-of-the-art results with an absolute reduction in diarization error of 23.3%.
Heterogeneous Target Speech Separation
Apr 07, 2022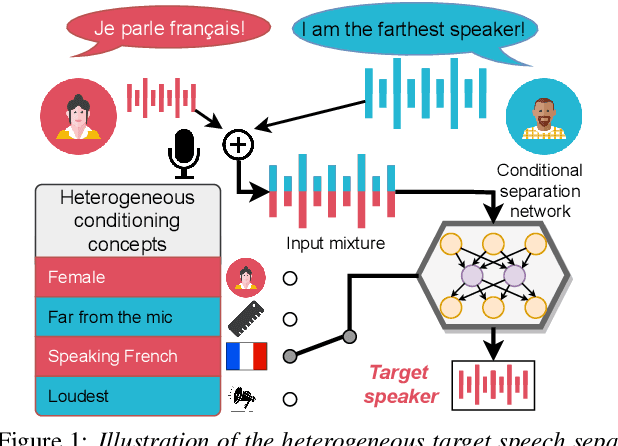
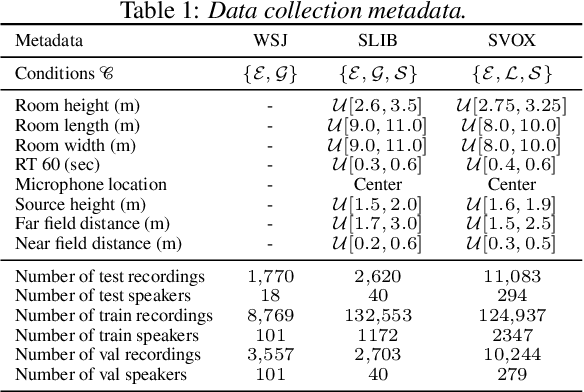
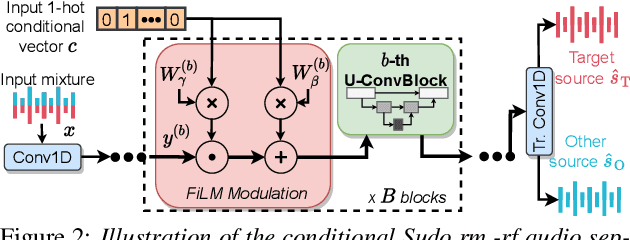
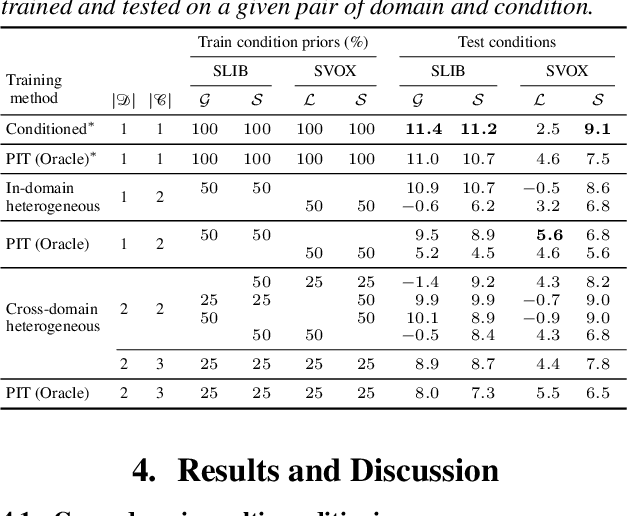
We introduce a new paradigm for single-channel target source separation where the sources of interest can be distinguished using non-mutually exclusive concepts (e.g., loudness, gender, language, spatial location, etc). Our proposed heterogeneous separation framework can seamlessly leverage datasets with large distribution shifts and learn cross-domain representations under a variety of concepts used as conditioning. Our experiments show that training separation models with heterogeneous conditions facilitates the generalization to new concepts with unseen out-of-domain data while also performing substantially higher than single-domain specialist models. Notably, such training leads to more robust learning of new harder source separation discriminative concepts and can yield improvements over permutation invariant training with oracle source selection. We analyze the intrinsic behavior of source separation training with heterogeneous metadata and propose ways to alleviate emerging problems with challenging separation conditions. We release the collection of preparation recipes for all datasets used to further promote research towards this challenging task.