 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeaker Diarization of Scripted Audiovisual Content
Aug 04, 2023

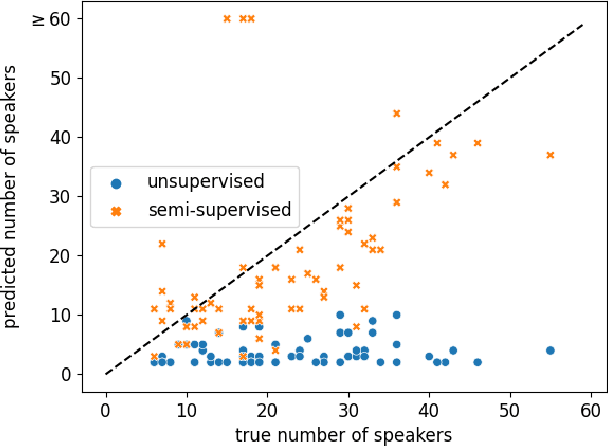
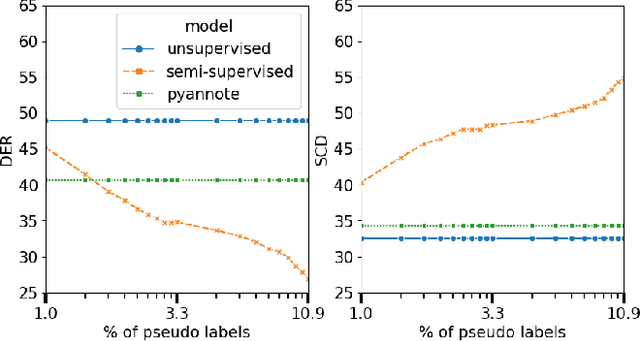
The media localization industry usually requires a verbatim script of the final film or TV production in order to create subtitles or dubbing scripts in a foreign language. In particular, the verbatim script (i.e. as-broadcast script) must be structured into a sequence of dialogue lines each including time codes, speaker name and transcript. Current speech recognition technology alleviates the transcription step. However, state-of-the-art speaker diarization models still fall short on TV shows for two main reasons: (i) their inability to track a large number of speakers, (ii) their low accuracy in detecting frequent speaker changes. To mitigate this problem, we present a novel approach to leverage production scripts used during the shooting process, to extract pseudo-labeled data for the speaker diarization task. We propose a novel semi-supervised approach and demonstrate improvements of 51.7% relative to two unsupervised baseline models on our metrics on a 66 show test set.
Improving Isochronous Machine Translation with Target Factors and Auxiliary Counters
May 22, 2023



To translate speech for automatic dubbing, machine translation needs to be isochronous, i.e. translated speech needs to be aligned with the source in terms of speech durations. We introduce target factors in a transformer model to predict durations jointly with target language phoneme sequences. We also introduce auxiliary counters to help the decoder to keep track of the timing information while generating target phonemes. We show that our model improves translation quality and isochrony compared to previous work where the translation model is instead trained to predict interleaved sequences of phonemes and durations.
Jointly Optimizing Translations and Speech Timing to Improve Isochrony in Automatic Dubbing
Feb 25, 2023



Automatic dubbing (AD) is the task of translating the original speech in a video into target language speech. The new target language speech should satisfy isochrony; that is, the new speech should be time aligned with the original video, including mouth movements, pauses, hand gestures, etc. In this paper, we propose training a model that directly optimizes both the translation as well as the speech duration of the generated translations. We show that this system generates speech that better matches the timing of the original speech, compared to prior work, while simplifying the system architecture.
Dubbing in Practice: A Large Scale Study of Human Localization With Insights for Automatic Dubbing
Dec 23, 2022We investigate how humans perform the task of dubbing video content from one language into another, leveraging a novel corpus of 319.57 hours of video from 54 professionally produced titles. This is the first such large-scale study we are aware of. The results challenge a number of assumptions commonly made in both qualitative literature on human dubbing and machine-learning literature on automatic dubbing, arguing for the importance of vocal naturalness and translation quality over commonly emphasized isometric (character length) and lip-sync constraints, and for a more qualified view of the importance of isochronic (timing) constraints. We also find substantial influence of the source-side audio on human dubs through channels other than the words of the translation, pointing to the need for research on ways to preserve speech characteristics, as well as semantic transfer such as emphasis/emotion, in automatic dubbing systems.
Prosodic Alignment for off-screen automatic dubbing
Apr 06, 2022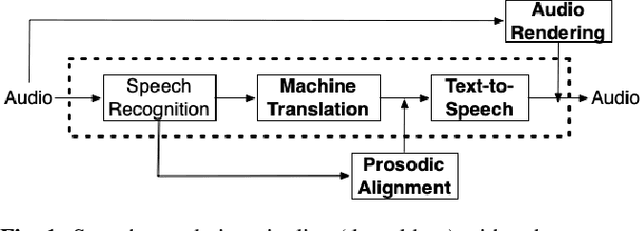

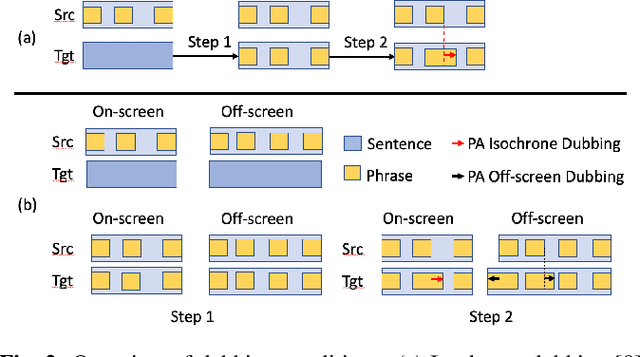
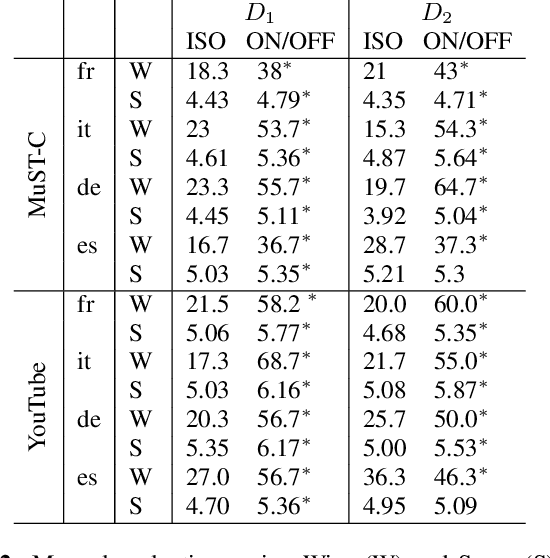
The goal of automatic dubbing is to perform speech-to-speech translation while achieving audiovisual coherence. This entails isochrony, i.e., translating the original speech by also matching its prosodic structure into phrases and pauses, especially when the speaker's mouth is visible. In previous work, we introduced a prosodic alignment model to address isochrone or on-screen dubbing. In this work, we extend the prosodic alignment model to also address off-screen dubbing that requires less stringent synchronization constraints. We conduct experiments on four dubbing directions - English to French, Italian, German and Spanish - on a publicly available collection of TED Talks and on publicly available YouTube videos. Empirical results show that compared to our previous work the extended prosodic alignment model provides significantly better subjective viewing experience on videos in which on-screen and off-screen automatic dubbing is applied for sentences with speakers mouth visible and not visible, respectively.
Isometric MT: Neural Machine Translation for Automatic Dubbing
Dec 20, 2021
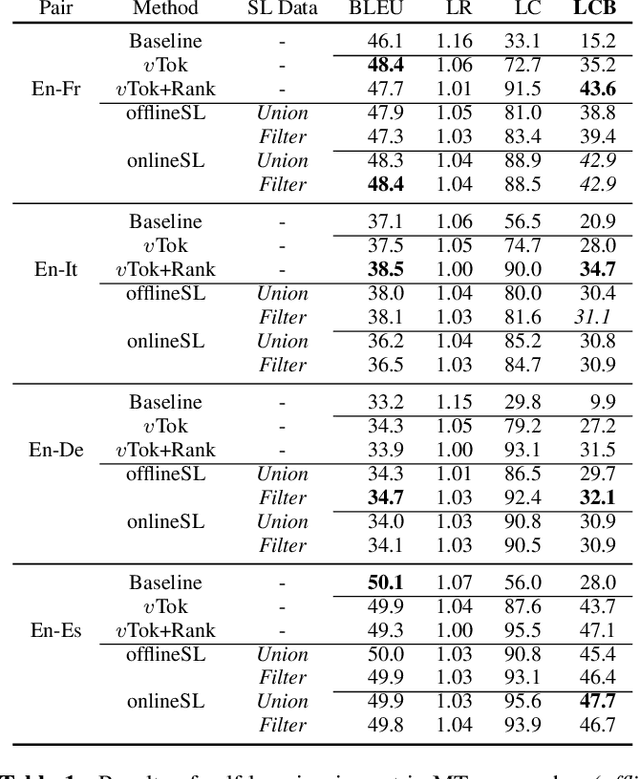
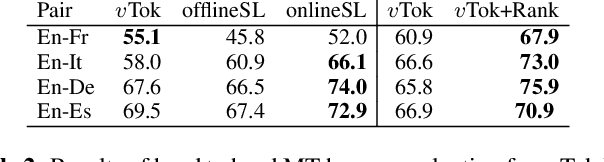
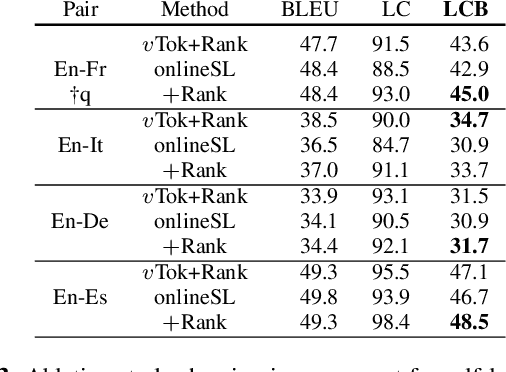
Automatic dubbing (AD) is among the use cases where translations should fit a given length template in order to achieve synchronicity between source and target speech. For neural machine translation (MT), generating translations of length close to the source length (e.g. within +-10% in character count), while preserving quality is a challenging task. Controlling NMT output length comes at a cost to translation quality which is usually mitigated with a two step approach of generation of n-best hypotheses and then re-ranking them based on length and quality. This work, introduces a self-learning approach that allows a transformer model to directly learn to generate outputs that closely match the source length, in short isometric MT. In particular, our approach for isometric MT does not require to generate multiple hypotheses nor any auxiliary scoring function. We report results on four language pairs (English - French, Italian, German, Spanish) with a publicly available benchmark based on TED Talk data. Both automatic and manual evaluations show that our self-learning approach to performs on par with more complex isometric MT approaches.
Prosody-Aware Neural Machine Translation for Dubbing
Dec 16, 2021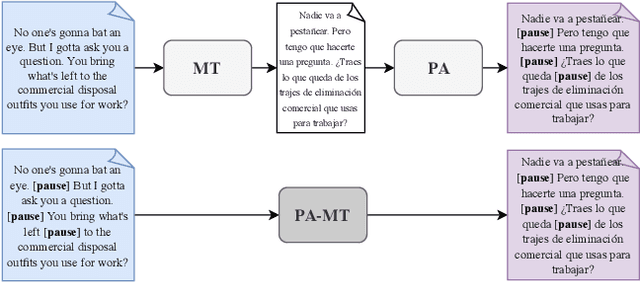
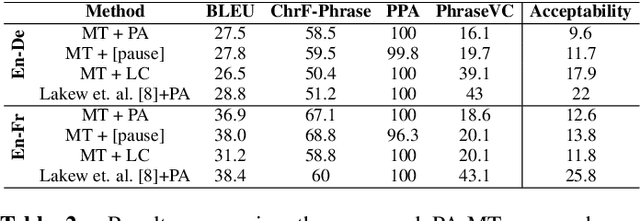
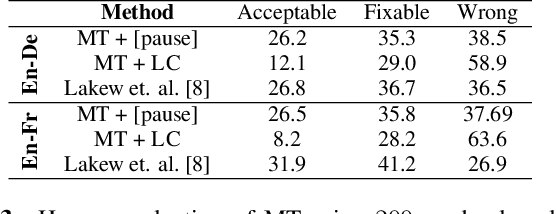

We introduce the task of prosody-aware machine translation which aims at generating translations suitable for dubbing. Dubbing of a spoken sentence requires transferring the content as well as the prosodic structure of the source into the target language to preserve timing information. Practically, this implies correctly projecting pauses from the source to the target and ensuring that target speech segments have roughly the same duration of the corresponding source segments. In this work, we propose an implicit and explicit modeling approaches to integrate prosody information into neural machine translation. Experiments on English-German/French with automatic metrics show that the simplest of the considered approaches works best. Results are confirmed by human evaluations of translations and dubbed videos.
Machine Translation Verbosity Control for Automatic Dubbing
Oct 08, 2021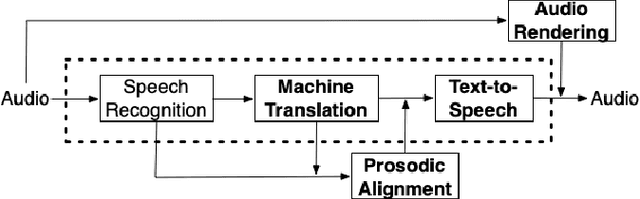
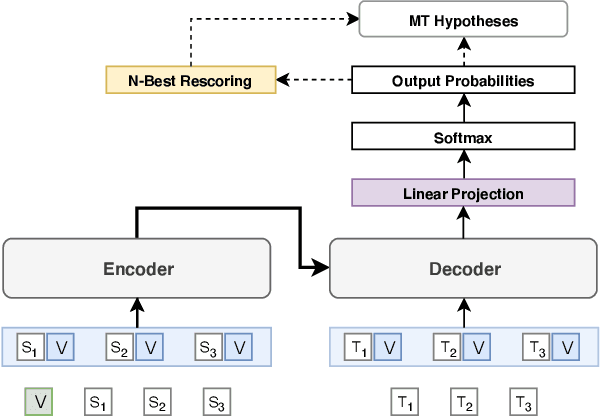
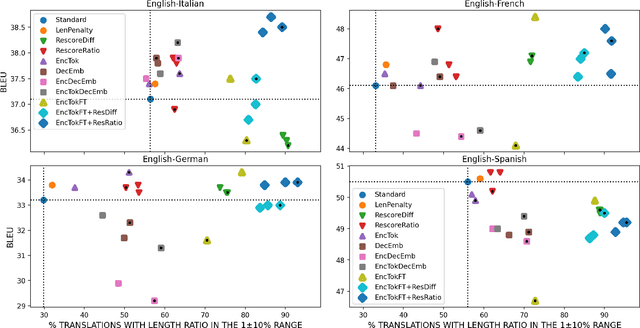
Automatic dubbing aims at seamlessly replacing the speech in a video document with synthetic speech in a different language. The task implies many challenges, one of which is generating translations that not only convey the original content, but also match the duration of the corresponding utterances. In this paper, we focus on the problem of controlling the verbosity of machine translation output, so that subsequent steps of our automatic dubbing pipeline can generate dubs of better quality. We propose new methods to control the verbosity of MT output and compare them against the state of the art with both intrinsic and extrinsic evaluations. For our experiments we use a public data set to dub English speeches into French, Italian, German and Spanish. Finally, we report extensive subjective tests that measure the impact of MT verbosity control on the final quality of dubbed video clips.