 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFindings of the IWSLT 2024 Evaluation Campaign
Nov 07, 2024This paper reports on the shared tasks organized by the 21st IWSLT Conference. The shared tasks address 7 scientific challenges in spoken language translation: simultaneous and offline translation, automatic subtitling and dubbing, speech-to-speech translation, dialect and low-resource speech translation, and Indic languages. The shared tasks attracted 18 teams whose submissions are documented in 26 system papers. The growing interest towards spoken language translation is also witnessed by the constantly increasing number of shared task organizers and contributors to the overview paper, almost evenly distributed across industry and academia.
The Multilingual TEDx Corpus for Speech Recognition and Translation
Feb 02, 2021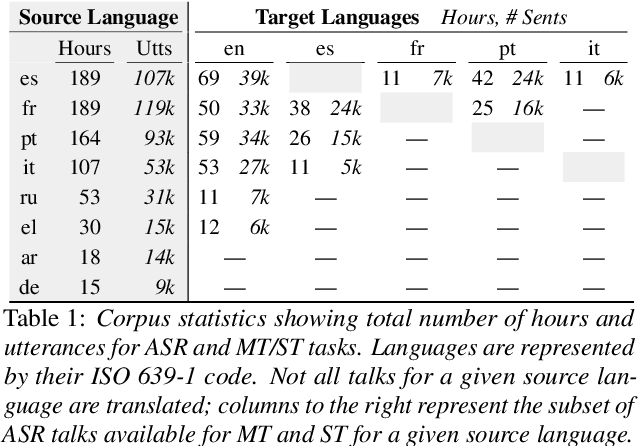
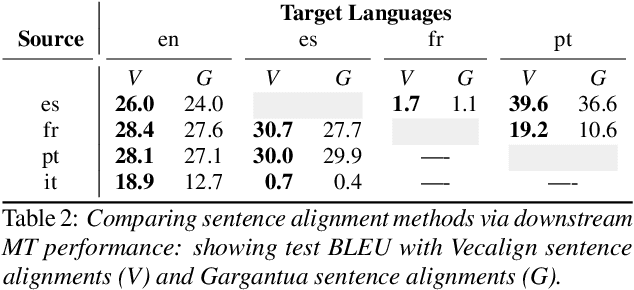
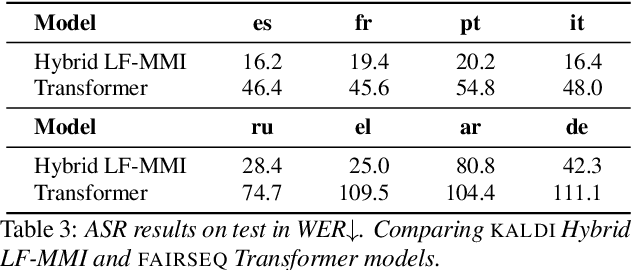
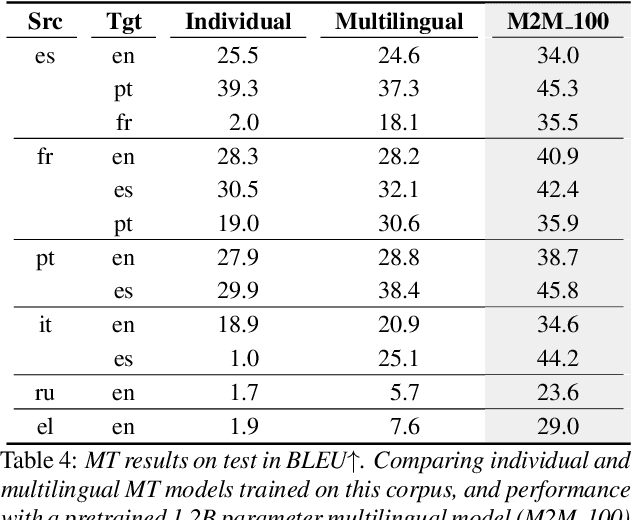
We present the Multilingual TEDx corpus, built to support speech recognition (ASR) and speech translation (ST) research across many non-English source languages. The corpus is a collection of audio recordings from TEDx talks in 8 source languages. We segment transcripts into sentences and align them to the source-language audio and target-language translations. The corpus is released along with open-sourced code enabling extension to new talks and languages as they become available. Our corpus creation methodology can be applied to more languages than previous work, and creates multi-way parallel evaluation sets. We provide baselines in multiple ASR and ST settings, including multilingual models to improve translation performance for low-resource language pairs.
Gender in Danger? Evaluating Speech Translation Technology on the MuST-SHE Corpus
Jun 10, 2020
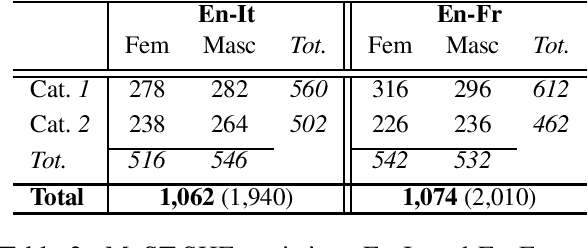


Translating from languages without productive grammatical gender like English into gender-marked languages is a well-known difficulty for machines. This difficulty is also due to the fact that the training data on which models are built typically reflect the asymmetries of natural languages, gender bias included. Exclusively fed with textual data, machine translation is intrinsically constrained by the fact that the input sentence does not always contain clues about the gender identity of the referred human entities. But what happens with speech translation, where the input is an audio signal? Can audio provide additional information to reduce gender bias? We present the first thorough investigation of gender bias in speech translation, contributing with: i) the release of a benchmark useful for future studies, and ii) the comparison of different technologies (cascade and end-to-end) on two language directions (English-Italian/French).
Fine-tuning on Clean Data for End-to-End Speech Translation: FBK @ IWSLT 2018
Oct 16, 2018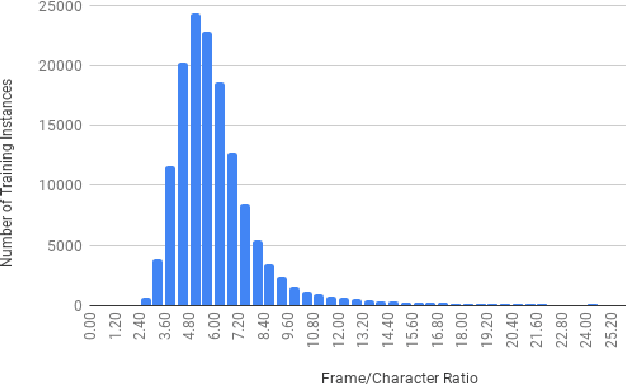
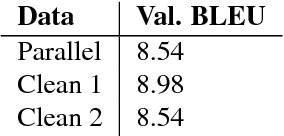
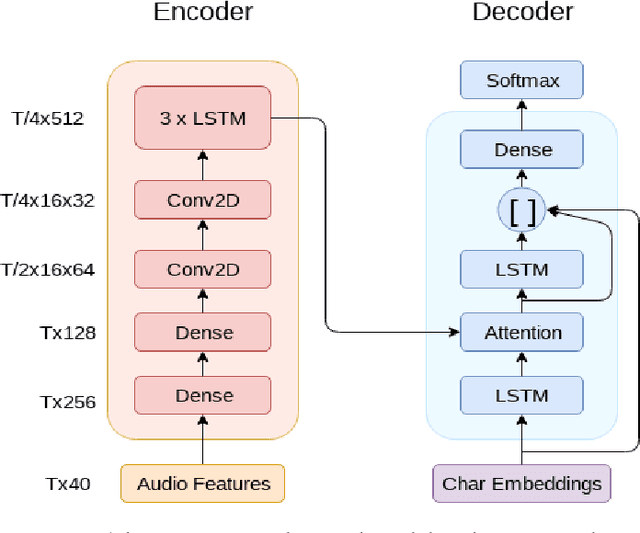

This paper describes FBK's submission to the end-to-end English-German speech translation task at IWSLT 2018. Our system relies on a state-of-the-art model based on LSTMs and CNNs, where the CNNs are used to reduce the temporal dimension of the audio input, which is in general much higher than machine translation input. Our model was trained only on the audio-to-text parallel data released for the task, and fine-tuned on cleaned subsets of the original training corpus. The addition of weight normalization and label smoothing improved the baseline system by 1.0 BLEU point on our validation set. The final submission also featured checkpoint averaging within a training run and ensemble decoding of models trained during multiple runs. On test data, our best single model obtained a BLEU score of 9.7, while the ensemble obtained a BLEU score of 10.24.
Unsupervised Clustering of Commercial Domains for Adaptive Machine Translation
Dec 14, 2016



In this paper, we report on domain clustering in the ambit of an adaptive MT architecture. A standard bottom-up hierarchical clustering algorithm has been instantiated with five different distances, which have been compared, on an MT benchmark built on 40 commercial domains, in terms of dendrograms, intrinsic and extrinsic evaluations. The main outcome is that the most expensive distance is also the only one able to allow the MT engine to guarantee good performance even with few, but highly populated clusters of domains.