 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolicies and Evaluation for Online Meeting Summarization
Feb 05, 2025



With more and more meetings moving to a digital domain, meeting summarization has recently gained interest in both academic and commercial research. However, prior academic research focuses on meeting summarization as an offline task, performed after the meeting concludes. In this paper, we perform the first systematic study of online meeting summarization. For this purpose, we propose several policies for conducting online summarization. We discuss the unique challenges of this task compared to the offline setting and define novel metrics to evaluate latency and partial summary quality. The experiments on the AutoMin dataset show that 1) online models can produce strong summaries, 2) our metrics allow a detailed analysis of different systems' quality-latency trade-off, also taking into account intermediate outputs and 3) adaptive policies perform better than fixed scheduled ones. These findings provide a starting point for the wider research community to explore this important task.
Findings of the IWSLT 2024 Evaluation Campaign
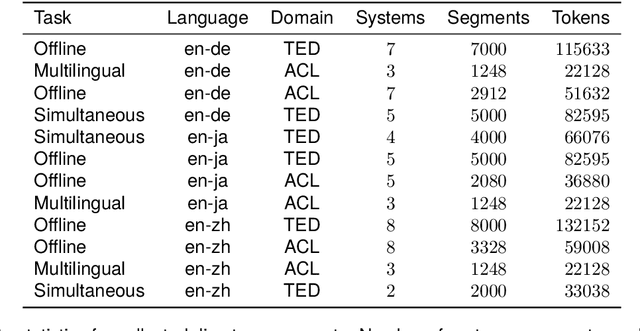
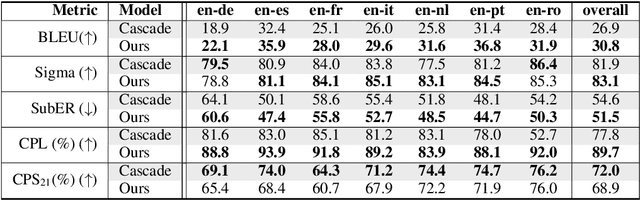
Nov 07, 2024This paper reports on the shared tasks organized by the 21st IWSLT Conference. The shared tasks address 7 scientific challenges in spoken language translation: simultaneous and offline translation, automatic subtitling and dubbing, speech-to-speech translation, dialect and low-resource speech translation, and Indic languages. The shared tasks attracted 18 teams whose submissions are documented in 26 system papers. The growing interest towards spoken language translation is also witnessed by the constantly increasing number of shared task organizers and contributors to the overview paper, almost evenly distributed across industry and academia.
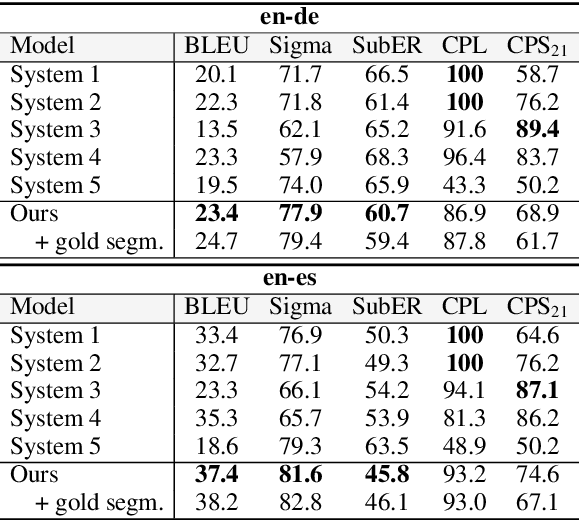
Evaluating the IWSLT2023 Speech Translation Tasks: Human Annotations, Automatic Metrics, and Segmentation
Jun 06, 2024
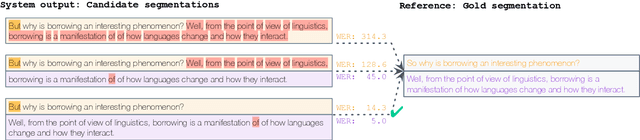

Human evaluation is a critical component in machine translation system development and has received much attention in text translation research. However, little prior work exists on the topic of human evaluation for speech translation, which adds additional challenges such as noisy data and segmentation mismatches. We take first steps to fill this gap by conducting a comprehensive human evaluation of the results of several shared tasks from the last International Workshop on Spoken Language Translation (IWSLT 2023). We propose an effective evaluation strategy based on automatic resegmentation and direct assessment with segment context. Our analysis revealed that: 1) the proposed evaluation strategy is robust and scores well-correlated with other types of human judgements; 2) automatic metrics are usually, but not always, well-correlated with direct assessment scores; and 3) COMET as a slightly stronger automatic metric than chrF, despite the segmentation noise introduced by the resegmentation step systems. We release the collected human-annotated data in order to encourage further investigation.
* LREC-COLING2024 publication (with corrections for Table 3)
AlignAtt: Using Attention-based Audio-Translation Alignments as a Guide for Simultaneous Speech Translation
May 19, 2023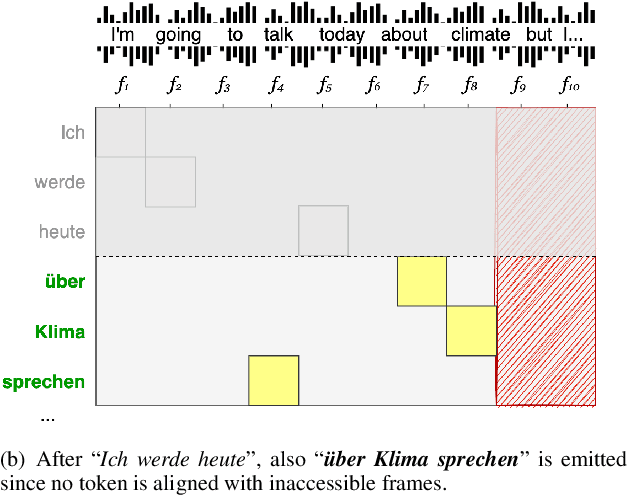

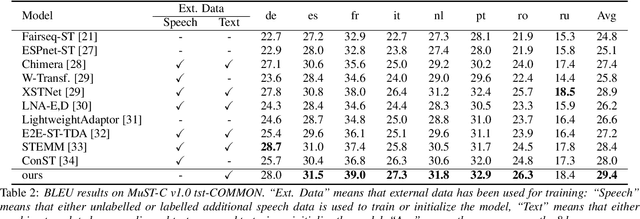
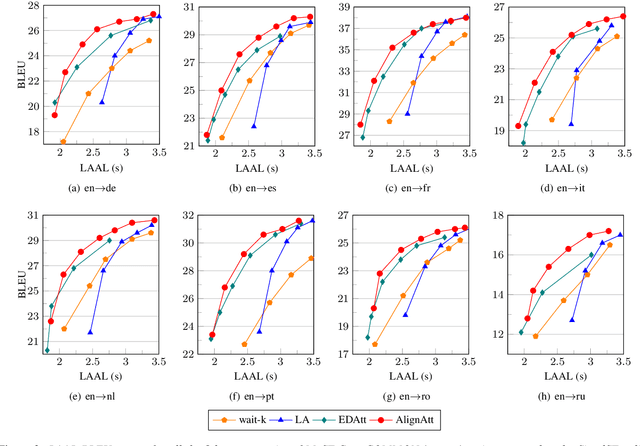
Attention is the core mechanism of today's most used architectures for natural language processing and has been analyzed from many perspectives, including its effectiveness for machine translation-related tasks. Among these studies, attention resulted to be a useful source of information to get insights about word alignment also when the input text is substituted with audio segments, as in the case of the speech translation (ST) task. In this paper, we propose AlignAtt, a novel policy for simultaneous ST (SimulST) that exploits the attention information to generate source-target alignments that guide the model during inference. Through experiments on the 8 language pairs of MuST-C v1.0, we show that AlignAtt outperforms previous state-of-the-art SimulST policies applied to offline-trained models with gains in terms of BLEU of 2 points and latency reductions ranging from 0.5s to 0.8s across the 8 languages.
Attention as a guide for Simultaneous Speech Translation
Dec 15, 2022
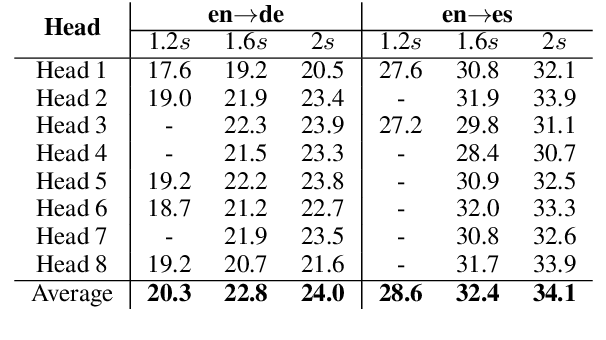
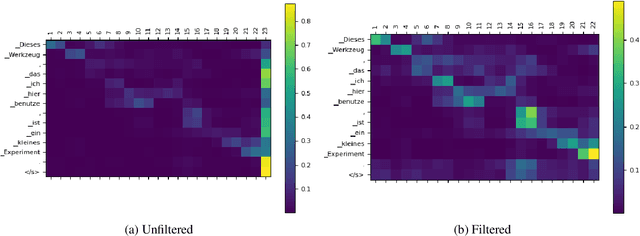

The study of the attention mechanism has sparked interest in many fields, such as language modeling and machine translation. Although its patterns have been exploited to perform different tasks, from neural network understanding to textual alignment, no previous work has analysed the encoder-decoder attention behavior in speech translation (ST) nor used it to improve ST on a specific task. In this paper, we fill this gap by proposing an attention-based policy (EDAtt) for simultaneous ST (SimulST) that is motivated by an analysis of the existing attention relations between audio input and textual output. Its goal is to leverage the encoder-decoder attention scores to guide inference in real time. Results on en->{de, es} show that the EDAtt policy achieves overall better results compared to the SimulST state of the art, especially in terms of computational-aware latency.
Direct Speech Translation for Automatic Subtitling
Sep 27, 2022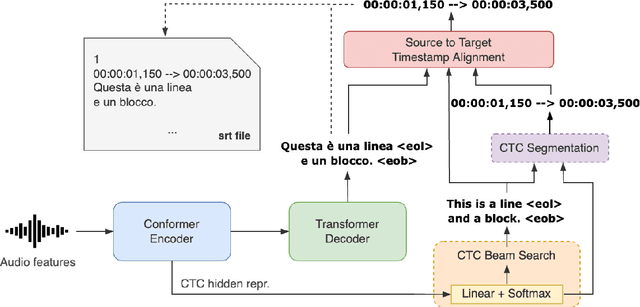
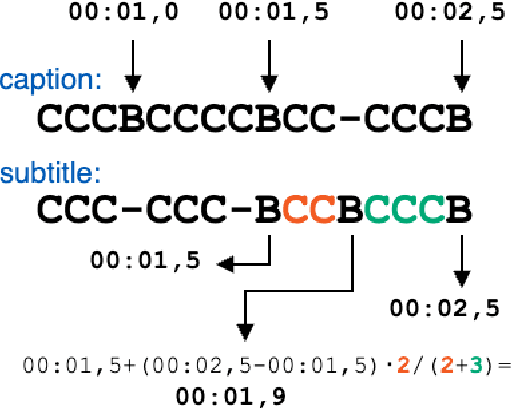
Automatic subtitling is the task of automatically translating the speech of an audiovisual product into short pieces of timed text, in other words, subtitles and their corresponding timestamps. The generated subtitles need to conform to multiple space and time requirements (length, reading speed) while being synchronised with the speech and segmented in a way that facilitates comprehension. Given its considerable complexity, automatic subtitling has so far been addressed through a pipeline of elements that deal separately with transcribing, translating, segmenting into subtitles and predicting timestamps. In this paper, we propose the first direct automatic subtitling model that generates target language subtitles and their timestamps from the source speech in a single solution. Comparisons with state-of-the-art cascaded models trained with both in- and out-domain data show that our system provides high-quality subtitles while also being competitive in terms of conformity, with all the advantages of maintaining a single model.
Dodging the Data Bottleneck: Automatic Subtitling with Automatically Segmented ST Corpora
Sep 21, 2022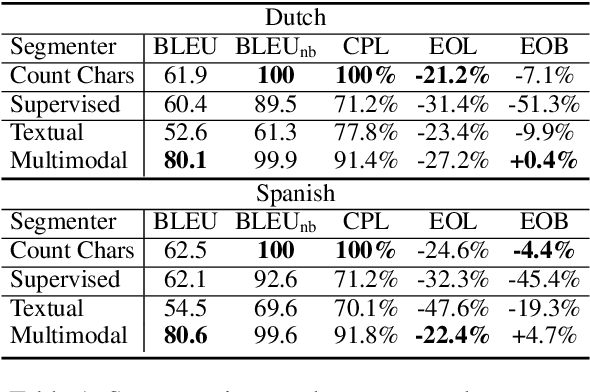
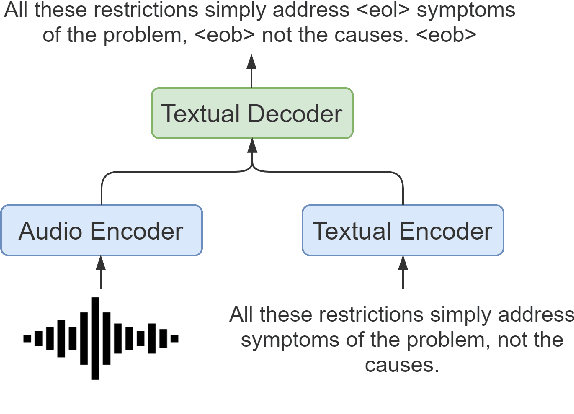
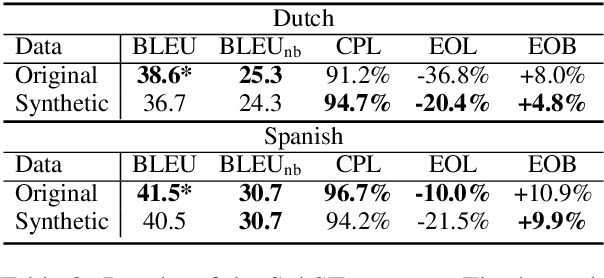
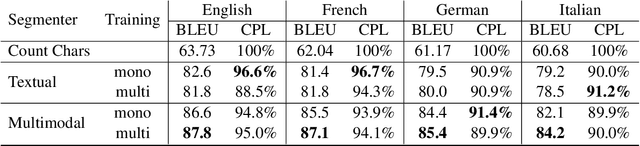
Speech translation for subtitling (SubST) is the task of automatically translating speech data into well-formed subtitles by inserting subtitle breaks compliant to specific displaying guidelines. Similar to speech translation (ST), model training requires parallel data comprising audio inputs paired with their textual translations. In SubST, however, the text has to be also annotated with subtitle breaks. So far, this requirement has represented a bottleneck for system development, as confirmed by the dearth of publicly available SubST corpora. To fill this gap, we propose a method to convert existing ST corpora into SubST resources without human intervention. We build a segmenter model that automatically segments texts into proper subtitles by exploiting audio and text in a multimodal fashion, achieving high segmentation quality in zero-shot conditions. Comparative experiments with SubST systems respectively trained on manual and automatic segmentations result in similar performance, showing the effectiveness of our approach.
Over-Generation Cannot Be Rewarded: Length-Adaptive Average Lagging for Simultaneous Speech Translation
Jun 20, 2022
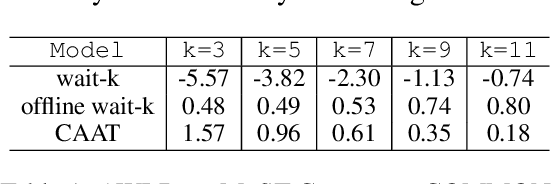
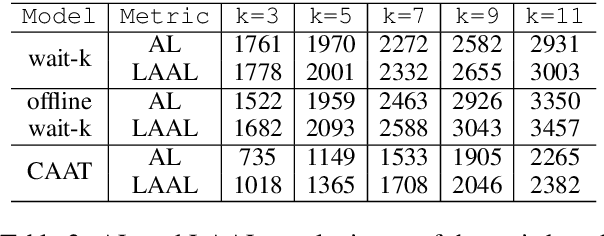
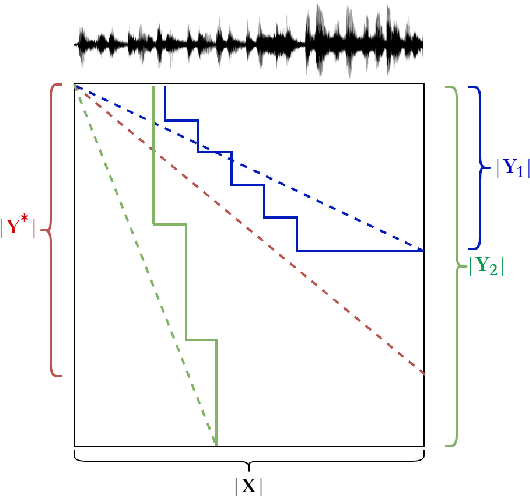
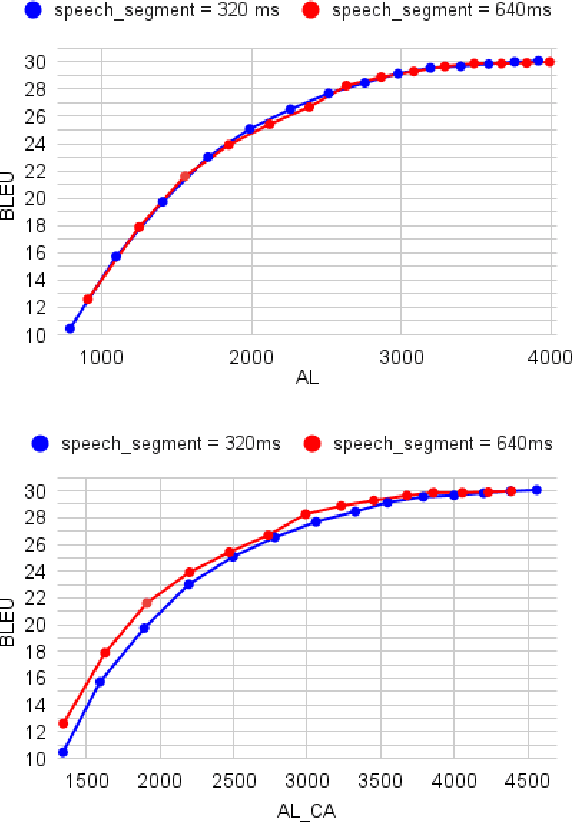
Simultaneous speech translation (SimulST) systems aim at generating their output with the lowest possible latency, which is normally computed in terms of Average Lagging (AL). In this paper we highlight that, despite its widespread adoption, AL provides underestimated scores for systems that generate longer predictions compared to the corresponding references. We also show that this problem has practical relevance, as recent SimulST systems have indeed a tendency to over-generate. As a solution, we propose LAAL (Length-Adaptive Average Lagging), a modified version of the metric that takes into account the over-generation phenomenon and allows for unbiased evaluation of both under-/over-generating systems.
Who Are We Talking About? Handling Person Names in Speech Translation
May 13, 2022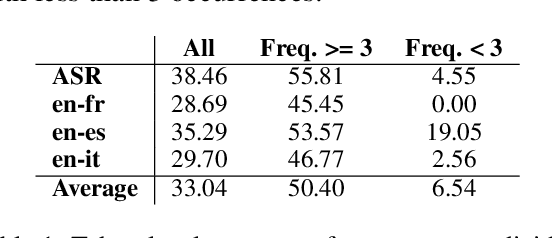
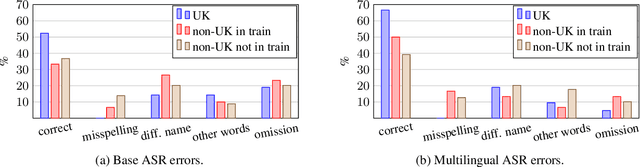
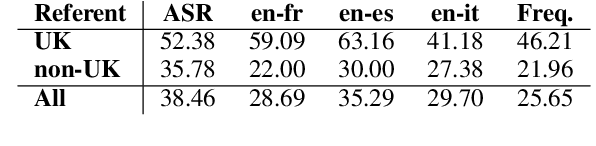
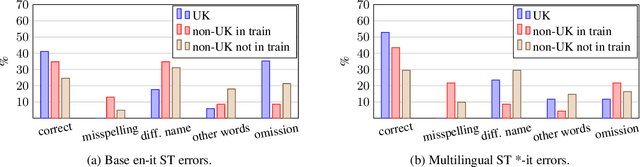
Recent work has shown that systems for speech translation (ST) -- similarly to automatic speech recognition (ASR) -- poorly handle person names. This shortcoming does not only lead to errors that can seriously distort the meaning of the input, but also hinders the adoption of such systems in application scenarios (like computer-assisted interpreting) where the translation of named entities, like person names, is crucial. In this paper, we first analyse the outputs of ASR/ST systems to identify the reasons of failures in person name transcription/translation. Besides the frequency in the training data, we pinpoint the nationality of the referred person as a key factor. We then mitigate the problem by creating multilingual models, and further improve our ST systems by forcing them to jointly generate transcripts and translations, prioritising the former over the latter. Overall, our solutions result in a relative improvement in token-level person name accuracy by 47.8% on average for three language pairs (en->es,fr,it).
Efficient yet Competitive Speech Translation: FBK@IWSLT2022
May 05, 2022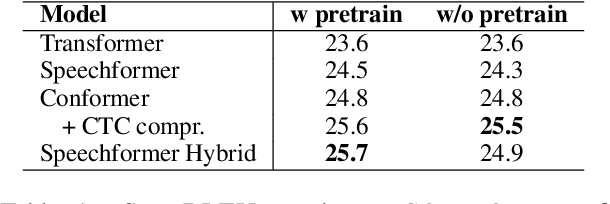
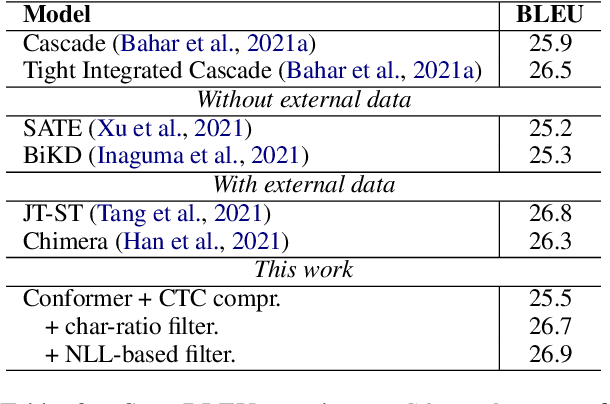
The primary goal of this FBK's systems submission to the IWSLT 2022 offline and simultaneous speech translation tasks is to reduce model training costs without sacrificing translation quality. As such, we first question the need of ASR pre-training, showing that it is not essential to achieve competitive results. Second, we focus on data filtering, showing that a simple method that looks at the ratio between source and target characters yields a quality improvement of 1 BLEU. Third, we compare different methods to reduce the detrimental effect of the audio segmentation mismatch between training data manually segmented at sentence level and inference data that is automatically segmented. Towards the same goal of training cost reduction, we participate in the simultaneous task with the same model trained for offline ST. The effectiveness of our lightweight training strategy is shown by the high score obtained on the MuST-C en-de corpus (26.7 BLEU) and is confirmed in high-resource data conditions by a 1.6 BLEU improvement on the IWSLT2020 test set over last year's winning system.