 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWho Are We Talking About? Handling Person Names in Speech Translation
Paper and Code
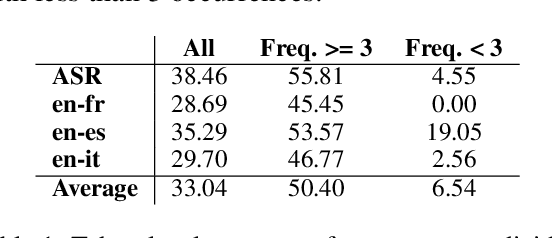
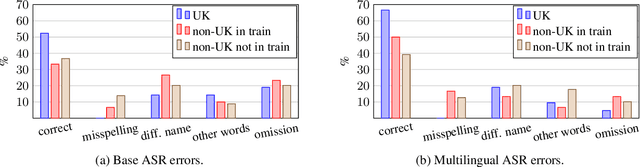
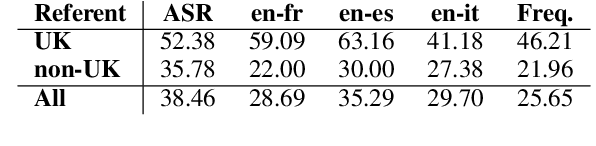
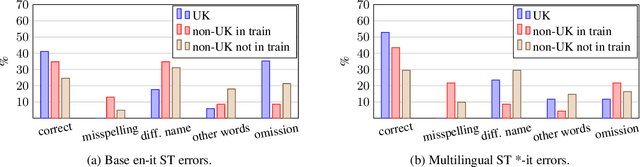
Recent work has shown that systems for speech translation (ST) -- similarly to automatic speech recognition (ASR) -- poorly handle person names. This shortcoming does not only lead to errors that can seriously distort the meaning of the input, but also hinders the adoption of such systems in application scenarios (like computer-assisted interpreting) where the translation of named entities, like person names, is crucial. In this paper, we first analyse the outputs of ASR/ST systems to identify the reasons of failures in person name transcription/translation. Besides the frequency in the training data, we pinpoint the nationality of the referred person as a key factor. We then mitigate the problem by creating multilingual models, and further improve our ST systems by forcing them to jointly generate transcripts and translations, prioritising the former over the latter. Overall, our solutions result in a relative improvement in token-level person name accuracy by 47.8% on average for three language pairs (en->es,fr,it).