 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Unheard Alternative: Contrastive Explanations for Speech-to-Text Models
Sep 30, 2025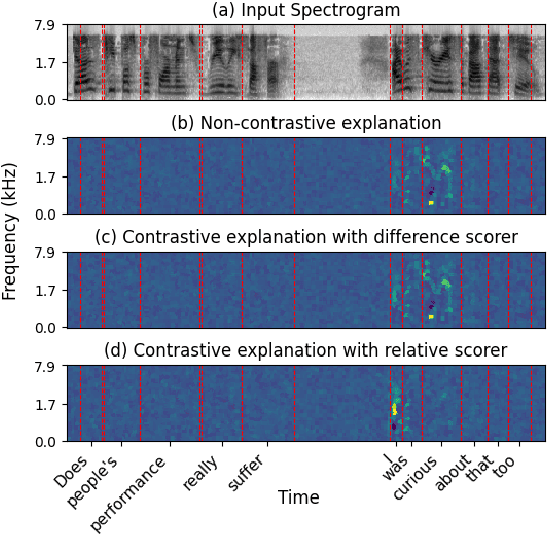
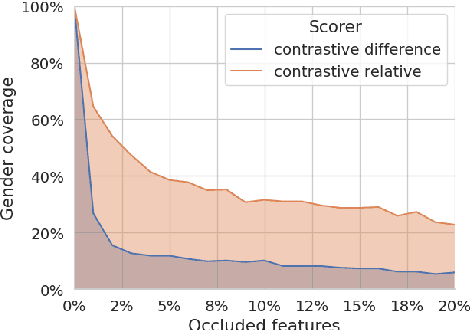

Contrastive explanations, which indicate why an AI system produced one output (the target) instead of another (the foil), are widely regarded in explainable AI as more informative and interpretable than standard explanations. However, obtaining such explanations for speech-to-text (S2T) generative models remains an open challenge. Drawing from feature attribution techniques, we propose the first method to obtain contrastive explanations in S2T by analyzing how parts of the input spectrogram influence the choice between alternative outputs. Through a case study on gender assignment in speech translation, we show that our method accurately identifies the audio features that drive the selection of one gender over another. By extending the scope of contrastive explanations to S2T, our work provides a foundation for better understanding S2T models.
SPES: Spectrogram Perturbation for Explainable Speech-to-Text Generation
Nov 03, 2024



Spurred by the demand for interpretable models, research on eXplainable AI for language technologies has experienced significant growth, with feature attribution methods emerging as a cornerstone of this progress. While prior work in NLP explored such methods for classification tasks and textual applications, explainability intersecting generation and speech is lagging, with existing techniques failing to account for the autoregressive nature of state-of-the-art models and to provide fine-grained, phonetically meaningful explanations. We address this gap by introducing Spectrogram Perturbation for Explainable Speech-to-text Generation (SPES), a feature attribution technique applicable to sequence generation tasks with autoregressive models. SPES provides explanations for each predicted token based on both the input spectrogram and the previously generated tokens. Extensive evaluation on speech recognition and translation demonstrates that SPES generates explanations that are faithful and plausible to humans.
Multilingual Speech Models for Automatic Speech Recognition Exhibit Gender Performance Gaps
Feb 28, 2024


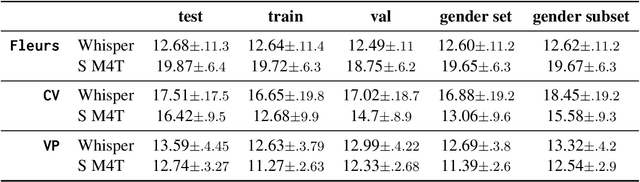
Current voice recognition approaches use multi-task, multilingual models for speech tasks like Automatic Speech Recognition (ASR) to make them applicable to many languages without substantial changes. However, broad language coverage can still mask performance gaps within languages, for example, across genders. We systematically evaluate multilingual ASR systems on gendered performance gaps. Using two popular models on three datasets in 19 languages across seven language families, we find clear gender disparities. However, the advantaged group varies between languages. While there are no significant differences across groups in phonetic variables (pitch, speaking rate, etc.), probing the model's internal states reveals a negative correlation between probe performance and the gendered performance gap. I.e., the easier to distinguish speaker gender in a language, the more the models favor female speakers. Our results show that group disparities remain unsolved despite great progress on multi-tasking and multilinguality. We provide first valuable insights for evaluating gender gaps in multilingual ASR systems. We release all code and artifacts at https://github.com/g8a9/multilingual-asr-gender-gap.
A Prompt Response to the Demand for Automatic Gender-Neutral Translation
Feb 08, 2024



Gender-neutral translation (GNT) that avoids biased and undue binary assumptions is a pivotal challenge for the creation of more inclusive translation technologies. Advancements for this task in Machine Translation (MT), however, are hindered by the lack of dedicated parallel data, which are necessary to adapt MT systems to satisfy neutral constraints. For such a scenario, large language models offer hitherto unforeseen possibilities, as they come with the distinct advantage of being versatile in various (sub)tasks when provided with explicit instructions. In this paper, we explore this potential to automate GNT by comparing MT with the popular GPT-4 model. Through extensive manual analyses, our study empirically reveals the inherent limitations of current MT systems in generating GNTs and provides valuable insights into the potential and challenges associated with prompting for neutrality.
Integrating Language Models into Direct Speech Translation: An Inference-Time Solution to Control Gender Inflection
Oct 24, 2023
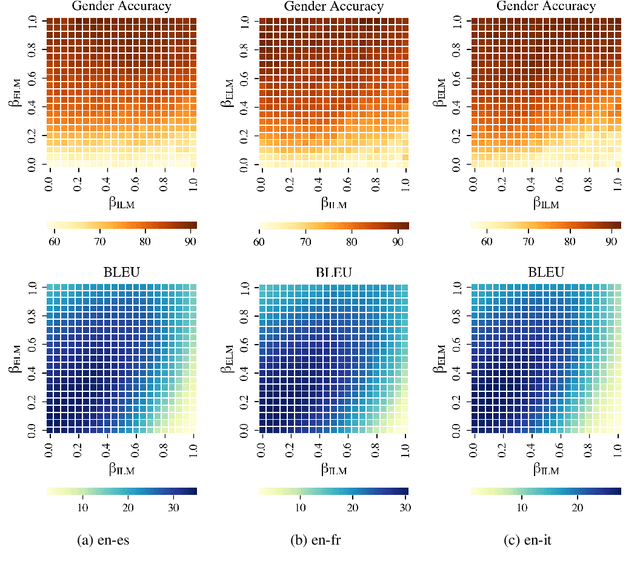

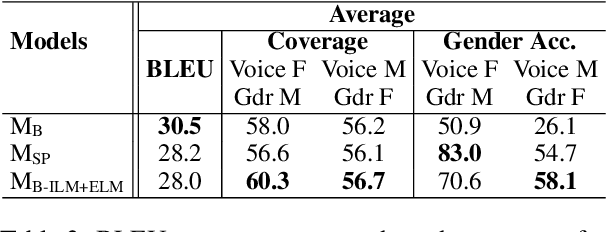
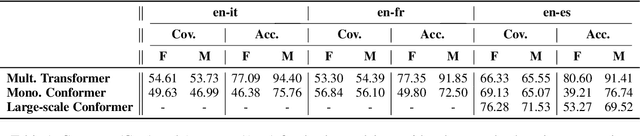
When translating words referring to the speaker, speech translation (ST) systems should not resort to default masculine generics nor rely on potentially misleading vocal traits. Rather, they should assign gender according to the speakers' preference. The existing solutions to do so, though effective, are hardly feasible in practice as they involve dedicated model re-training on gender-labeled ST data. To overcome these limitations, we propose the first inference-time solution to control speaker-related gender inflections in ST. Our approach partially replaces the (biased) internal language model (LM) implicitly learned by the ST decoder with gender-specific external LMs. Experiments on en->es/fr/it show that our solution outperforms the base models and the best training-time mitigation strategy by up to 31.0 and 1.6 points in gender accuracy, respectively, for feminine forms. The gains are even larger (up to 32.0 and 3.4) in the challenging condition where speakers' vocal traits conflict with their gender.
How To Build Competitive Multi-gender Speech Translation Models For Controlling Speaker Gender Translation
Oct 23, 2023
When translating from notional gender languages (e.g., English) into grammatical gender languages (e.g., Italian), the generated translation requires explicit gender assignments for various words, including those referring to the speaker. When the source sentence does not convey the speaker's gender, speech translation (ST) models either rely on the possibly-misleading vocal traits of the speaker or default to the masculine gender, the most frequent in existing training corpora. To avoid such biased and not inclusive behaviors, the gender assignment of speaker-related expressions should be guided by externally-provided metadata about the speaker's gender. While previous work has shown that the most effective solution is represented by separate, dedicated gender-specific models, the goal of this paper is to achieve the same results by integrating the speaker's gender metadata into a single "multi-gender" neural ST model, easier to maintain. Our experiments demonstrate that a single multi-gender model outperforms gender-specialized ones when trained from scratch (with gender accuracy gains up to 12.9 for feminine forms), while fine-tuning from existing ST models does not lead to competitive results.
No Pitch Left Behind: Addressing Gender Unbalance in Automatic Speech Recognition through Pitch Manipulation
Oct 10, 2023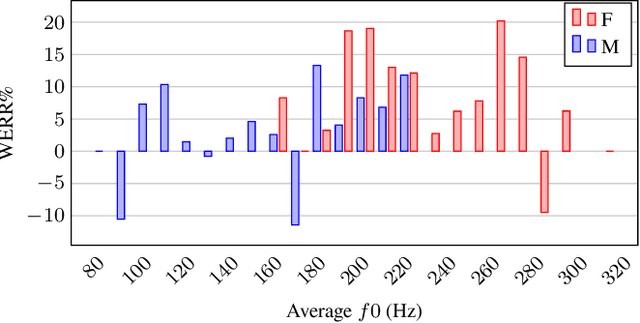
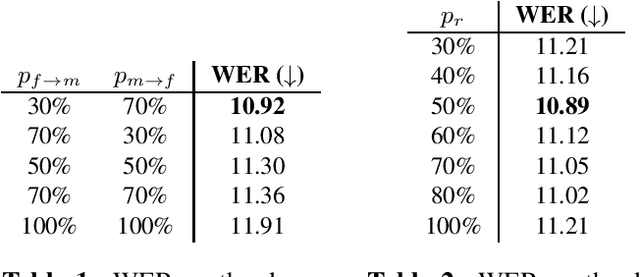
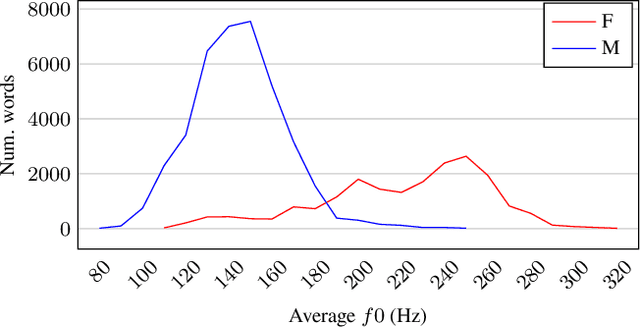

Automatic speech recognition (ASR) systems are known to be sensitive to the sociolinguistic variability of speech data, in which gender plays a crucial role. This can result in disparities in recognition accuracy between male and female speakers, primarily due to the under-representation of the latter group in the training data. While in the context of hybrid ASR models several solutions have been proposed, the gender bias issue has not been explicitly addressed in end-to-end neural architectures. To fill this gap, we propose a data augmentation technique that manipulates the fundamental frequency (f0) and formants. This technique reduces the data unbalance among genders by simulating voices of the under-represented female speakers and increases the variability within each gender group. Experiments on spontaneous English speech show that our technique yields a relative WER improvement up to 9.87% for utterances by female speakers, with larger gains for the least-represented f0 ranges.
Hi Guys or Hi Folks? Benchmarking Gender-Neutral Machine Translation with the GeNTE Corpus
Oct 08, 2023Gender inequality is embedded in our communication practices and perpetuated in translation technologies. This becomes particularly apparent when translating into grammatical gender languages, where machine translation (MT) often defaults to masculine and stereotypical representations by making undue binary gender assumptions. Our work addresses the rising demand for inclusive language by focusing head-on on gender-neutral translation from English to Italian. We start from the essentials: proposing a dedicated benchmark and exploring automated evaluation methods. First, we introduce GeNTE, a natural, bilingual test set for gender-neutral translation, whose creation was informed by a survey on the perception and use of neutral language. Based on GeNTE, we then overview existing reference-based evaluation approaches, highlight their limits, and propose a reference-free method more suitable to assess gender-neutral translation.
From Inclusive Language to Gender-Neutral Machine Translation
Jan 24, 2023Gender inclusivity in language has become a central topic of debate and research. Its application in the cross-lingual contexts of human and machine translation (MT), however, remains largely unexplored. Here, we discuss Gender-Neutral Translation (GNT) as a form of gender inclusivity in translation and advocate for its adoption for MT models, which have been found to perpetuate gender bias and discrimination. To this aim, we review a selection of relevant institutional guidelines for Gender-Inclusive Language (GIL) to collect and systematize useful strategies of gender neutralization. Then, we discuss GNT and its scenarios of use, devising a list of desiderata. Finally, we identify the main technical challenges to the implementation of GNT in MT. Throughout these contributions we focus on translation from English into Italian, as representative of salient linguistic transfer problems, due to the different rules for gender marking in their grammar.
Efficient yet Competitive Speech Translation: FBK@IWSLT2022
May 05, 2022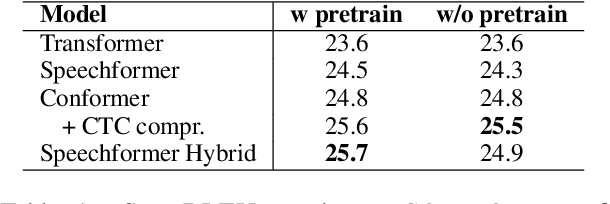
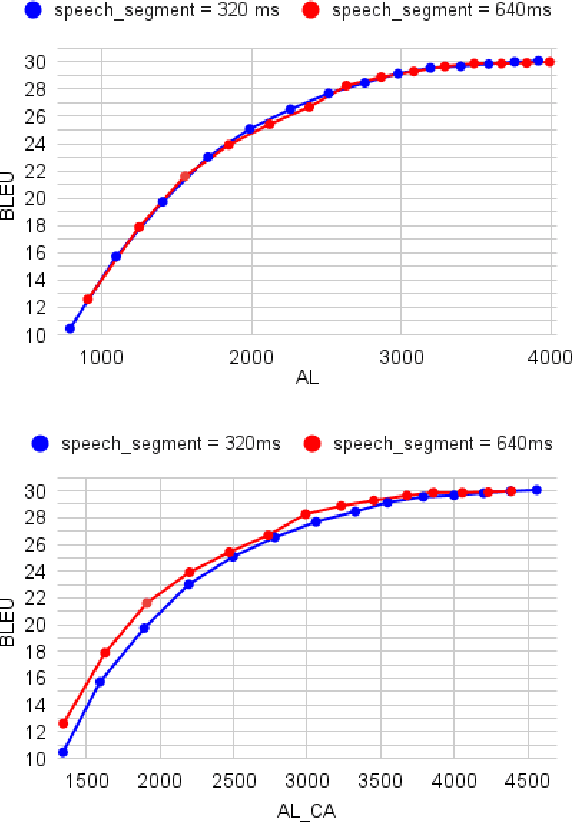
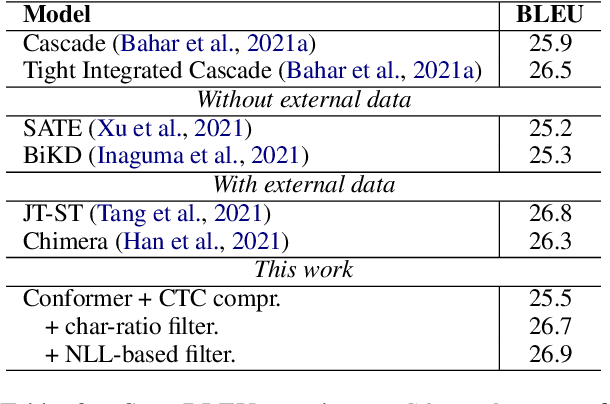
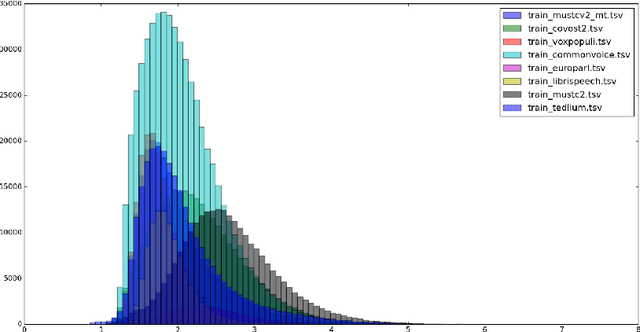
The primary goal of this FBK's systems submission to the IWSLT 2022 offline and simultaneous speech translation tasks is to reduce model training costs without sacrificing translation quality. As such, we first question the need of ASR pre-training, showing that it is not essential to achieve competitive results. Second, we focus on data filtering, showing that a simple method that looks at the ratio between source and target characters yields a quality improvement of 1 BLEU. Third, we compare different methods to reduce the detrimental effect of the audio segmentation mismatch between training data manually segmented at sentence level and inference data that is automatically segmented. Towards the same goal of training cost reduction, we participate in the simultaneous task with the same model trained for offline ST. The effectiveness of our lightweight training strategy is shown by the high score obtained on the MuST-C en-de corpus (26.7 BLEU) and is confirmed in high-resource data conditions by a 1.6 BLEU improvement on the IWSLT2020 test set over last year's winning system.