 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNo Pitch Left Behind: Addressing Gender Unbalance in Automatic Speech Recognition through Pitch Manipulation
Paper and Code
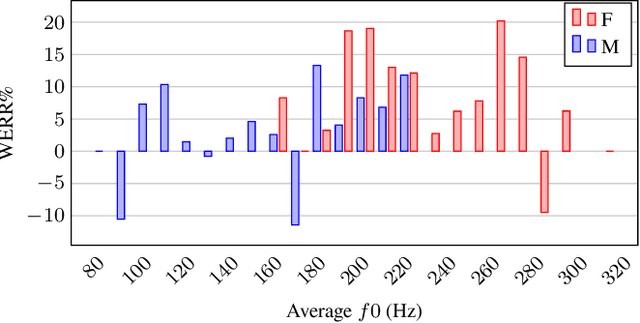
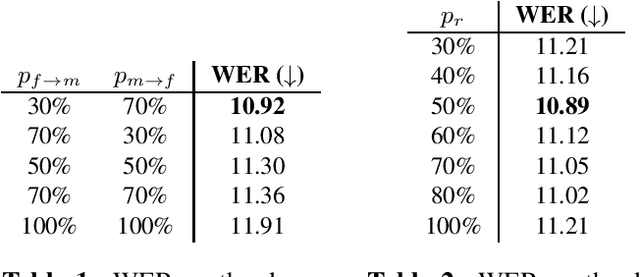
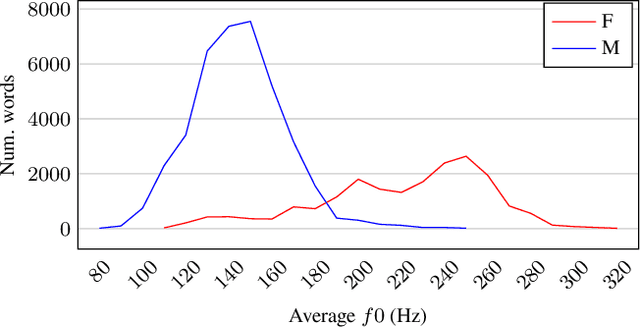

Automatic speech recognition (ASR) systems are known to be sensitive to the sociolinguistic variability of speech data, in which gender plays a crucial role. This can result in disparities in recognition accuracy between male and female speakers, primarily due to the under-representation of the latter group in the training data. While in the context of hybrid ASR models several solutions have been proposed, the gender bias issue has not been explicitly addressed in end-to-end neural architectures. To fill this gap, we propose a data augmentation technique that manipulates the fundamental frequency (f0) and formants. This technique reduces the data unbalance among genders by simulating voices of the under-represented female speakers and increases the variability within each gender group. Experiments on spontaneous English speech show that our technique yields a relative WER improvement up to 9.87% for utterances by female speakers, with larger gains for the least-represented f0 ranges.