 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimulU: Training-free Policy for Long-form Simultaneous Speech-to-Speech Translation
Mar 11, 2026Simultaneous speech-to-speech translation (SimulS2S) is essential for real-time multilingual communication, with increasing integration into meeting and streaming platforms. Despite this, SimulS2S remains underexplored in research, where current solutions often rely on resource-intensive training procedures and operate on short-form, pre-segmented utterances, failing to generalize to continuous speech. To bridge this gap, we propose SimulU, the first training-free policy for long-form SimulS2S. SimulU adopts history management and speech output selection strategies that exploit cross-attention in pre-trained end-to-end models to regulate both input history and output generation. Evaluations on MuST-C across 8 languages show that SimulU achieves a better or comparable quality-latency trade-off against strong cascaded models. By eliminating the need for ad-hoc training, SimulU offers a promising path to end-to-end SimulS2S in realistic, long-form scenarios.
Do What I Say: A Spoken Prompt Dataset for Instruction-Following
Mar 10, 2026Speech Large Language Models (SLLMs) have rapidly expanded, supporting a wide range of tasks. These models are typically evaluated using text prompts, which may not reflect real-world scenarios where users interact with speech. To address this gap, we introduce DoWhatISay (DOWIS), a multilingual dataset of human-recorded spoken and written prompts designed to pair with any existing benchmark for realistic evaluation of SLLMs under spoken instruction conditions. Spanning 9 tasks and 11 languages, it provides 10 prompt variants per task-language pair, across five styles. Using DOWIS, we benchmark state-of-the-art SLLMs, analyzing the interplay between prompt modality, style, language, and task type. Results show that text prompts consistently outperform spoken prompts, particularly for low-resource and cross-lingual settings. Only for tasks with speech output, spoken prompts do close the gap, highlighting the need for speech-based prompting in SLLM evaluation.
Simulstream: Open-Source Toolkit for Evaluation and Demonstration of Streaming Speech-to-Text Translation Systems
Dec 19, 2025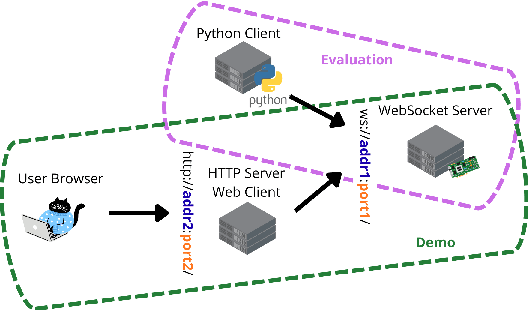
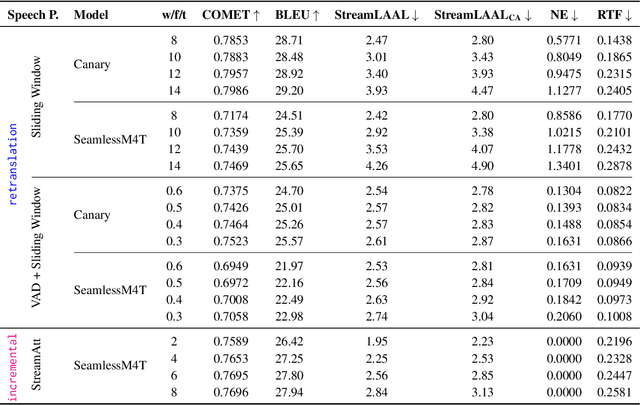
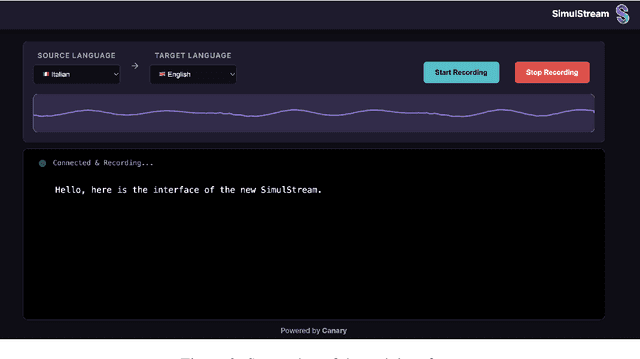
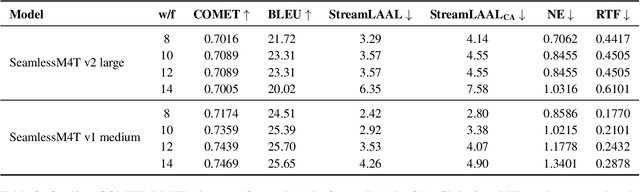
Streaming Speech-to-Text Translation (StreamST) requires producing translations concurrently with incoming speech, imposing strict latency constraints and demanding models that balance partial-information decision-making with high translation quality. Research efforts on the topic have so far relied on the SimulEval repository, which is no longer maintained and does not support systems that revise their outputs. In addition, it has been designed for simulating the processing of short segments, rather than long-form audio streams, and it does not provide an easy method to showcase systems in a demo. As a solution, we introduce simulstream, the first open-source framework dedicated to unified evaluation and demonstration of StreamST systems. Designed for long-form speech processing, it supports not only incremental decoding approaches, but also re-translation methods, enabling for their comparison within the same framework both in terms of quality and latency. In addition, it also offers an interactive web interface to demo any system built within the tool.
The Unheard Alternative: Contrastive Explanations for Speech-to-Text Models
Sep 30, 2025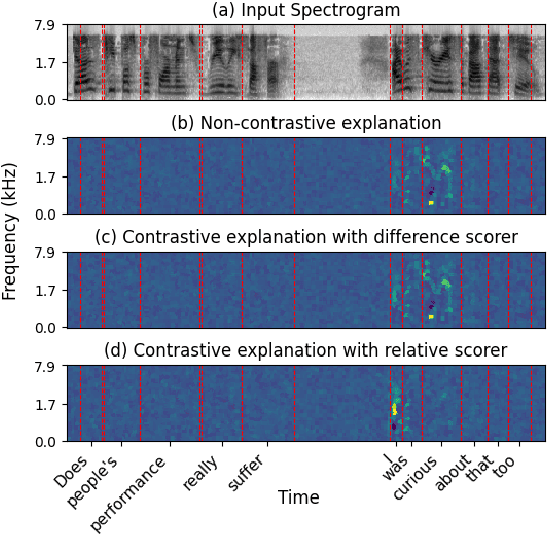
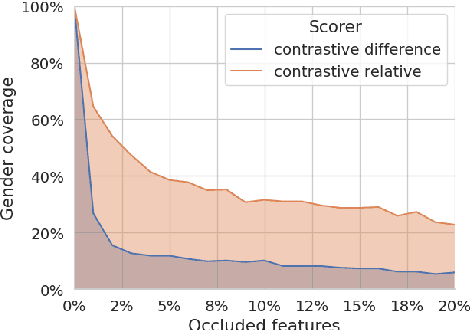

Contrastive explanations, which indicate why an AI system produced one output (the target) instead of another (the foil), are widely regarded in explainable AI as more informative and interpretable than standard explanations. However, obtaining such explanations for speech-to-text (S2T) generative models remains an open challenge. Drawing from feature attribution techniques, we propose the first method to obtain contrastive explanations in S2T by analyzing how parts of the input spectrogram influence the choice between alternative outputs. Through a case study on gender assignment in speech translation, we show that our method accurately identifies the audio features that drive the selection of one gender over another. By extending the scope of contrastive explanations to S2T, our work provides a foundation for better understanding S2T models.
An Interdisciplinary Approach to Human-Centered Machine Translation
Jun 16, 2025Machine Translation (MT) tools are widely used today, often in contexts where professional translators are not present. Despite progress in MT technology, a gap persists between system development and real-world usage, particularly for non-expert users who may struggle to assess translation reliability. This paper advocates for a human-centered approach to MT, emphasizing the alignment of system design with diverse communicative goals and contexts of use. We survey the literature in Translation Studies and Human-Computer Interaction to recontextualize MT evaluation and design to address the diverse real-world scenarios in which MT is used today.
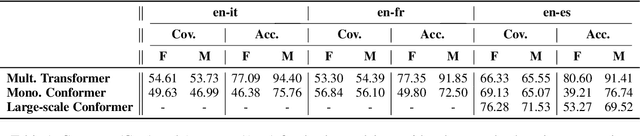
The Warmup Dilemma: How Learning Rate Strategies Impact Speech-to-Text Model Convergence
May 29, 2025Training large-scale models presents challenges not only in terms of resource requirements but also in terms of their convergence. For this reason, the learning rate (LR) is often decreased when the size of a model is increased. Such a simple solution is not enough in the case of speech-to-text (S2T) trainings, where evolved and more complex variants of the Transformer architecture -- e.g., Conformer or Branchformer -- are used in light of their better performance. As a workaround, OWSM designed a double linear warmup of the LR, increasing it to a very small value in the first phase before updating it to a higher value in the second phase. While this solution worked well in practice, it was not compared with alternative solutions, nor was the impact on the final performance of different LR warmup schedules studied. This paper fills this gap, revealing that i) large-scale S2T trainings demand a sub-exponential LR warmup, and ii) a higher LR in the warmup phase accelerates initial convergence, but it does not boost final performance.
FAMA: The First Large-Scale Open-Science Speech Foundation Model for English and Italian
May 28, 2025The development of speech foundation models (SFMs) like Whisper and SeamlessM4T has significantly advanced the field of speech processing. However, their closed nature--with inaccessible training data and code--poses major reproducibility and fair evaluation challenges. While other domains have made substantial progress toward open science by developing fully transparent models trained on open-source (OS) code and data, similar efforts in speech remain limited. To fill this gap, we introduce FAMA, the first family of open science SFMs for English and Italian, trained on 150k+ hours of OS speech data. Moreover, we present a new dataset containing 16k hours of cleaned and pseudo-labeled speech for both languages. Results show that FAMA achieves competitive performance compared to existing SFMs while being up to 8 times faster. All artifacts, including code, datasets, and models, are released under OS-compliant licenses, promoting openness in speech technology research.
An LLM-as-a-judge Approach for Scalable Gender-Neutral Translation Evaluation
Apr 16, 2025Gender-neutral translation (GNT) aims to avoid expressing the gender of human referents when the source text lacks explicit cues about the gender of those referents. Evaluating GNT automatically is particularly challenging, with current solutions being limited to monolingual classifiers. Such solutions are not ideal because they do not factor in the source sentence and require dedicated data and fine-tuning to scale to new languages. In this work, we address such limitations by investigating the use of large language models (LLMs) as evaluators of GNT. Specifically, we explore two prompting approaches: one in which LLMs generate sentence-level assessments only, and another, akin to a chain-of-thought approach, where they first produce detailed phrase-level annotations before a sentence-level judgment. Through extensive experiments on multiple languages with five models, both open and proprietary, we show that LLMs can serve as evaluators of GNT. Moreover, we find that prompting for phrase-level annotations before sentence-level assessments consistently improves the accuracy of all models, providing a better and more scalable alternative to current solutions.
NUTSHELL: A Dataset for Abstract Generation from Scientific Talks
Feb 24, 2025Scientific communication is receiving increasing attention in natural language processing, especially to help researches access, summarize, and generate content. One emerging application in this area is Speech-to-Abstract Generation (SAG), which aims to automatically generate abstracts from recorded scientific presentations. SAG enables researchers to efficiently engage with conference talks, but progress has been limited by a lack of large-scale datasets. To address this gap, we introduce NUTSHELL, a novel multimodal dataset of *ACL conference talks paired with their corresponding abstracts. We establish strong baselines for SAG and evaluate the quality of generated abstracts using both automatic metrics and human judgments. Our results highlight the challenges of SAG and demonstrate the benefits of training on NUTSHELL. By releasing NUTSHELL under an open license (CC-BY 4.0), we aim to advance research in SAG and foster the development of improved models and evaluation methods.
Translation in the Hands of Many:Centering Lay Users in Machine Translation Interactions
Feb 19, 2025Converging societal and technical factors have transformed language technologies into user-facing applications employed across languages. Machine Translation (MT) has become a global tool, with cross-lingual services now also supported by dialogue systems powered by multilingual Large Language Models (LLMs). This accessibility has expanded MT's reach to a vast base of lay users, often with little to no expertise in the languages or the technology itself. Despite this, the understanding of MT consumed by this diverse group of users -- their needs, experiences, and interactions with these systems -- remains limited. This paper traces the shift in MT user profiles, focusing on non-expert users and how their engagement with these systems may change with LLMs. We identify three key factors -- usability, trust, and literacy -- that shape these interactions and must be addressed to align MT with user needs. By exploring these dimensions, we offer insights to guide future MT with a user-centered approach.