 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Warmup Dilemma: How Learning Rate Strategies Impact Speech-to-Text Model Convergence
May 29, 2025Training large-scale models presents challenges not only in terms of resource requirements but also in terms of their convergence. For this reason, the learning rate (LR) is often decreased when the size of a model is increased. Such a simple solution is not enough in the case of speech-to-text (S2T) trainings, where evolved and more complex variants of the Transformer architecture -- e.g., Conformer or Branchformer -- are used in light of their better performance. As a workaround, OWSM designed a double linear warmup of the LR, increasing it to a very small value in the first phase before updating it to a higher value in the second phase. While this solution worked well in practice, it was not compared with alternative solutions, nor was the impact on the final performance of different LR warmup schedules studied. This paper fills this gap, revealing that i) large-scale S2T trainings demand a sub-exponential LR warmup, and ii) a higher LR in the warmup phase accelerates initial convergence, but it does not boost final performance.
FAMA: The First Large-Scale Open-Science Speech Foundation Model for English and Italian
May 28, 2025The development of speech foundation models (SFMs) like Whisper and SeamlessM4T has significantly advanced the field of speech processing. However, their closed nature--with inaccessible training data and code--poses major reproducibility and fair evaluation challenges. While other domains have made substantial progress toward open science by developing fully transparent models trained on open-source (OS) code and data, similar efforts in speech remain limited. To fill this gap, we introduce FAMA, the first family of open science SFMs for English and Italian, trained on 150k+ hours of OS speech data. Moreover, we present a new dataset containing 16k hours of cleaned and pseudo-labeled speech for both languages. Results show that FAMA achieves competitive performance compared to existing SFMs while being up to 8 times faster. All artifacts, including code, datasets, and models, are released under OS-compliant licenses, promoting openness in speech technology research.
MOSEL: 950,000 Hours of Speech Data for Open-Source Speech Foundation Model Training on EU Languages
Oct 01, 2024



The rise of foundation models (FMs), coupled with regulatory efforts addressing their risks and impacts, has sparked significant interest in open-source models. However, existing speech FMs (SFMs) fall short of full compliance with the open-source principles, even if claimed otherwise, as no existing SFM has model weights, code, and training data publicly available under open-source terms. In this work, we take the first step toward filling this gap by focusing on the 24 official languages of the European Union (EU). We collect suitable training data by surveying automatic speech recognition datasets and unlabeled speech corpora under open-source compliant licenses, for a total of 950k hours. Additionally, we release automatic transcripts for 441k hours of unlabeled data under the permissive CC-BY license, thereby facilitating the creation of open-source SFMs for the EU languages.
Seed Words Based Data Selection for Language Model Adaptation
Jul 20, 2021

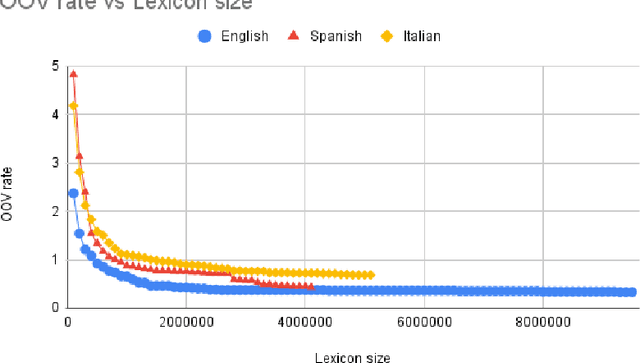
We address the problem of language model customization in applications where the ASR component needs to manage domain-specific terminology; although current state-of-the-art speech recognition technology provides excellent results for generic domains, the adaptation to specialized dictionaries or glossaries is still an open issue. In this work we present an approach for automatically selecting sentences, from a text corpus, that match, both semantically and morphologically, a glossary of terms (words or composite words) furnished by the user. The final goal is to rapidly adapt the language model of an hybrid ASR system with a limited amount of in-domain text data in order to successfully cope with the linguistic domain at hand; the vocabulary of the baseline model is expanded and tailored, reducing the resulting OOV rate. Data selection strategies based on shallow morphological seeds and semantic similarity viaword2vec are introduced and discussed; the experimental setting consists in a simultaneous interpreting scenario, where ASRs in three languages are designed to recognize the domain-specific terms (i.e. dentistry). Results using different metrics (OOV rate, WER, precision and recall) show the effectiveness of the proposed techniques.
Mixtures of Deep Neural Experts for Automated Speech Scoring
Jun 23, 2021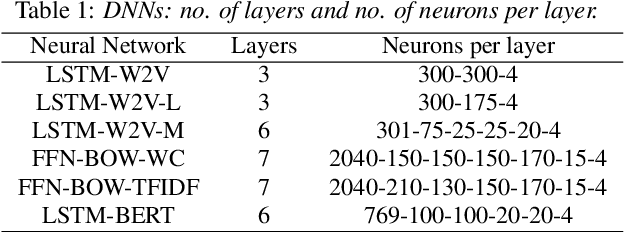
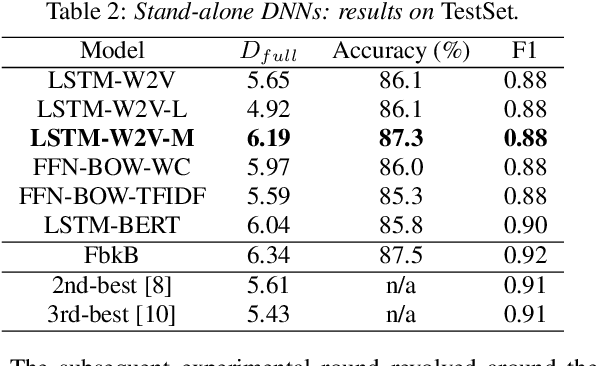
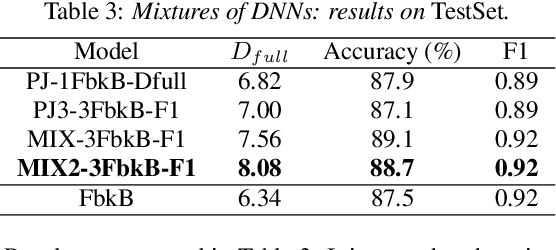
The paper copes with the task of automatic assessment of second language proficiency from the language learners' spoken responses to test prompts. The task has significant relevance to the field of computer assisted language learning. The approach presented in the paper relies on two separate modules: (1) an automatic speech recognition system that yields text transcripts of the spoken interactions involved, and (2) a multiple classifier system based on deep learners that ranks the transcripts into proficiency classes. Different deep neural network architectures (both feed-forward and recurrent) are specialized over diverse representations of the texts in terms of: a reference grammar, the outcome of probabilistic language models, several word embeddings, and two bag-of-word models. Combination of the individual classifiers is realized either via a probabilistic pseudo-joint model, or via a neural mixture of experts. Using the data of the third Spoken CALL Shared Task challenge, the highest values to date were obtained in terms of three popular evaluation metrics.
Experiments of ASR-based mispronunciation detection for children and adult English learners
Apr 13, 2021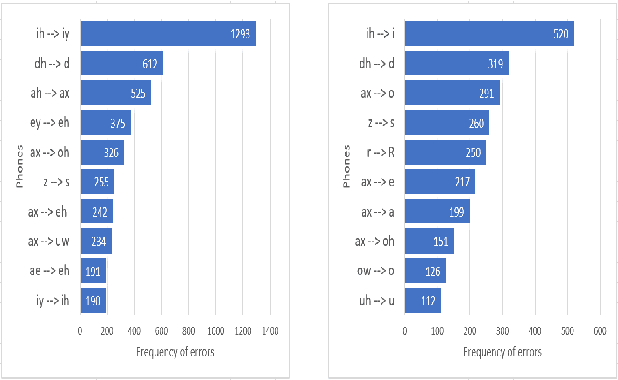
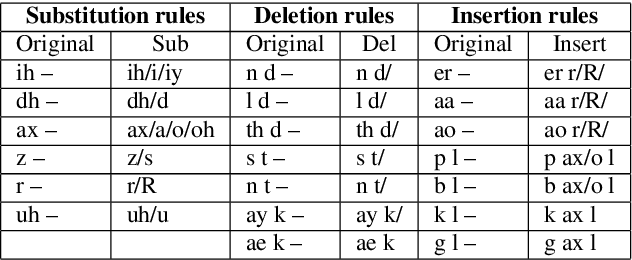
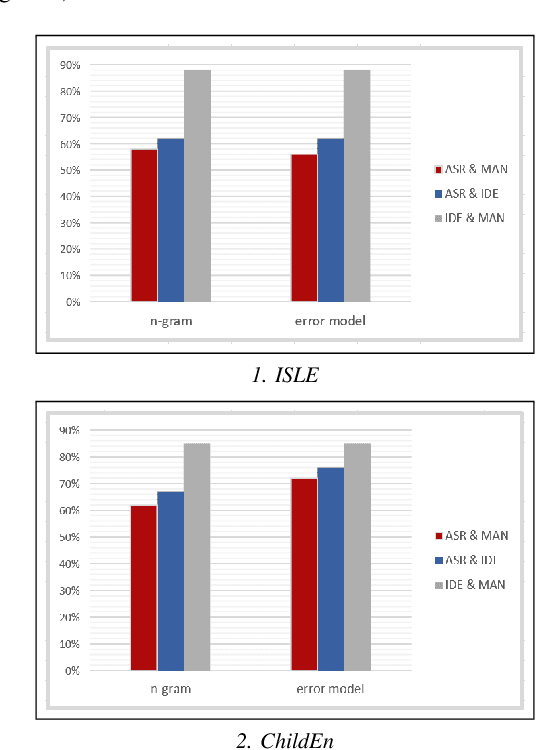
Pronunciation is one of the fundamentals of language learning, and it is considered a primary factor of spoken language when it comes to an understanding and being understood by others. The persistent presence of high error rates in speech recognition domains resulting from mispronunciations motivates us to find alternative techniques for handling mispronunciations. In this study, we develop a mispronunciation assessment system that checks the pronunciation of non-native English speakers, identifies the commonly mispronounced phonemes of Italian learners of English, and presents an evaluation of the non-native pronunciation observed in phonetically annotated speech corpora. In this work, to detect mispronunciations, we used a phone-based ASR implemented using Kaldi. We used two non-native English labeled corpora; (i) a corpus of Italian adults contains 5,867 utterances from 46 speakers, and (ii) a corpus of Italian children consists of 5,268 utterances from 78 children. Our results show that the selected error model can discriminate correct sounds from incorrect sounds in both native and nonnative speech, and therefore can be used to detect pronunciation errors in non-native speech. The phone error rates show improvement in using the error language model. The ASR system shows better accuracy after applying the error model on our selected corpora.
TLT-school: a Corpus of Non Native Children Speech
Jan 22, 2020

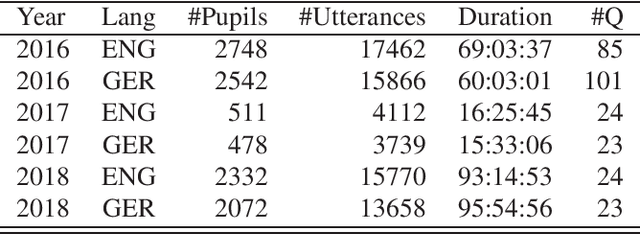
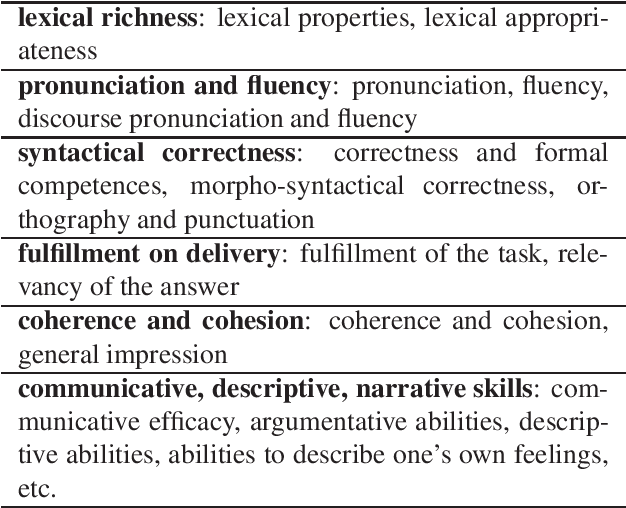
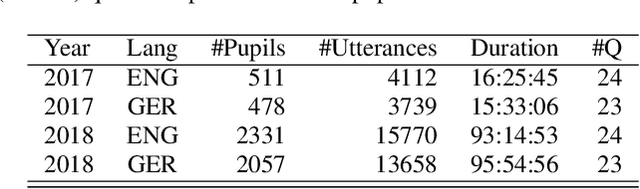
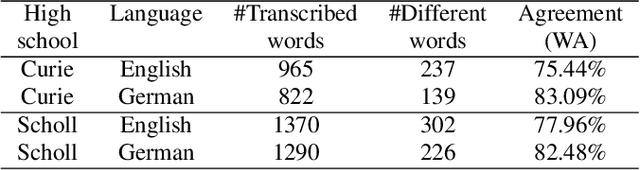
This paper describes "TLT-school" a corpus of speech utterances collected in schools of northern Italy for assessing the performance of students learning both English and German. The corpus was recorded in the years 2017 and 2018 from students aged between nine and sixteen years, attending primary, middle and high school. All utterances have been scored, in terms of some predefined proficiency indicators, by human experts. In addition, most of utterances recorded in 2017 have been manually transcribed carefully. Guidelines and procedures used for manual transcriptions of utterances will be described in detail, as well as results achieved by means of an automatic speech recognition system developed by us. Part of the corpus is going to be freely distributed to scientific community particularly interested both in non-native speech recognition and automatic assessment of second language proficiency.
Automatic assessment of spoken language proficiency of non-native children
Mar 15, 2019

This paper describes technology developed to automatically grade Italian students (ages 9-16) on their English and German spoken language proficiency. The students' spoken answers are first transcribed by an automatic speech recognition (ASR) system and then scored using a feedforward neural network (NN) that processes features extracted from the automatic transcriptions. In-domain acoustic models, employing deep neural networks (DNNs), are derived by adapting the parameters of an original out of domain DNN.
Non-native children speech recognition through transfer learning
Sep 25, 2018
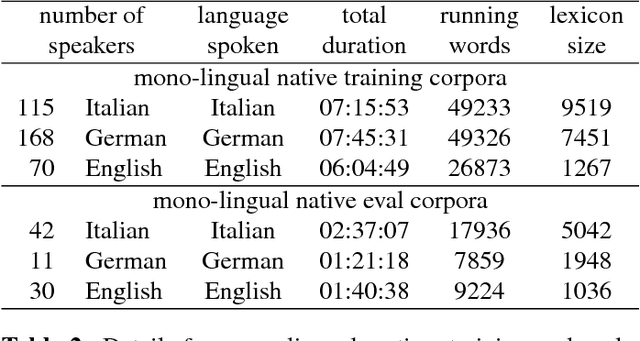
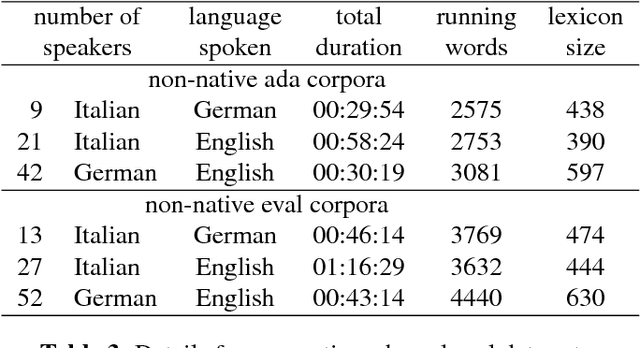
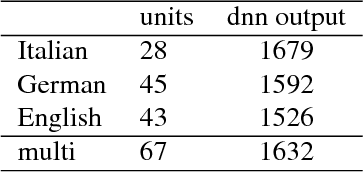
This work deals with non-native children's speech and investigates both multi-task and transfer learning approaches to adapt a multi-language Deep Neural Network (DNN) to speakers, specifically children, learning a foreign language. The application scenario is characterized by young students learning English and German and reading sentences in these second-languages, as well as in their mother language. The paper analyzes and discusses techniques for training effective DNN-based acoustic models starting from children native speech and performing adaptation with limited non-native audio material. A multi-lingual model is adopted as baseline, where a common phonetic lexicon, defined in terms of the units of the International Phonetic Alphabet (IPA), is shared across the three languages at hand (Italian, German and English); DNN adaptation methods based on transfer learning are evaluated on significant non-native evaluation sets. Results show that the resulting non-native models allow a significant improvement with respect to a mono-lingual system adapted to speakers of the target language.