 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Parallel Cross-Lingual Benchmark for Multimodal Idiomaticity Understanding
Jan 13, 2026Potentially idiomatic expressions (PIEs) construe meanings inherently tied to the everyday experience of a given language community. As such, they constitute an interesting challenge for assessing the linguistic (and to some extent cultural) capabilities of NLP systems. In this paper, we present XMPIE, a parallel multilingual and multimodal dataset of potentially idiomatic expressions. The dataset, containing 34 languages and over ten thousand items, allows comparative analyses of idiomatic patterns among language-specific realisations and preferences in order to gather insights about shared cultural aspects. This parallel dataset allows to evaluate model performance for a given PIE in different languages and whether idiomatic understanding in one language can be transferred to another. Moreover, the dataset supports the study of PIEs across textual and visual modalities, to measure to what extent PIE understanding in one modality transfers or implies in understanding in another modality (text vs. image). The data was created by language experts, with both textual and visual components crafted under multilingual guidelines, and each PIE is accompanied by five images representing a spectrum from idiomatic to literal meanings, including semantically related and random distractors. The result is a high-quality benchmark for evaluating multilingual and multimodal idiomatic language understanding.
50 questions on Active Assisted Living technologies. Global edition
Oct 22, 2024This booklet on Active Assisted Living (AAL) technologies has been created as part of the GoodBrother COST Action, which has run from 2020 to 2024. COST Actions are European research programs that promote collaboration across borders, uniting researchers, professionals, and institutions to address key societal challenges. GoodBrother focused on ethical and privacy concerns surrounding video and audio monitoring in care settings. The aim was to ensure that while AAL technologies help older adults and vulnerable individuals, their privacy and data protection rights remain a top priority. This booklet is designed to guide you through the role that AAL technologies play in improving the quality of life for older adults, caregivers, and people with disabilities. AAL technologies offer tools for those facing cognitive or physical challenges. They can enhance independence, assist with daily routines, and promote a safer living environment. However, the rise of these technologies also brings important questions about data protection and user autonomy. This resource is intended for a wide audience, including end users, caregivers, healthcare professionals, and policymakers. It provides practical guidance on integrating AAL technologies into care settings while safeguarding privacy and ensuring ethical use. The insights offered here aim to empower users and caregivers to make informed choices that enhance both the quality of care and respect for personal autonomy.
Experiments of ASR-based mispronunciation detection for children and adult English learners
Apr 13, 2021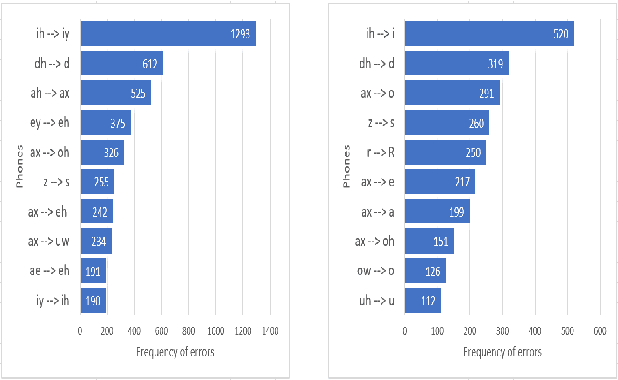
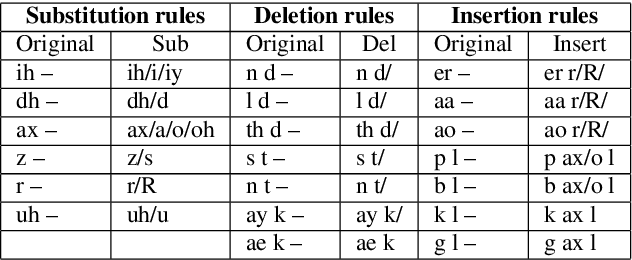
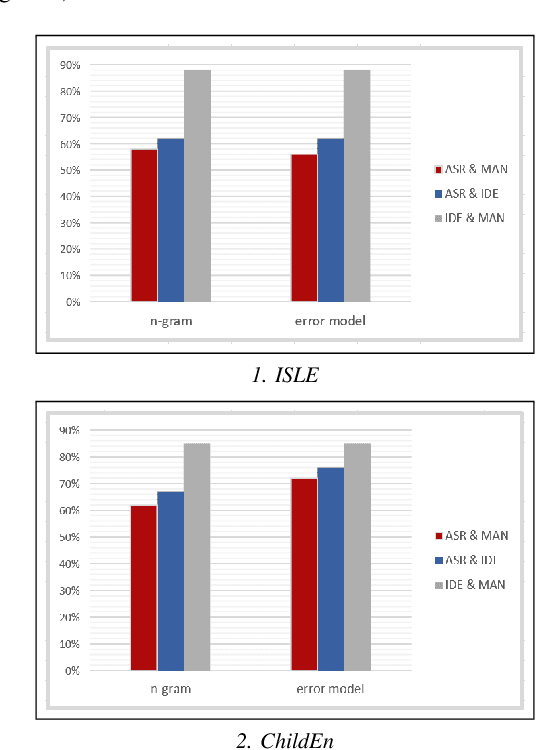
Pronunciation is one of the fundamentals of language learning, and it is considered a primary factor of spoken language when it comes to an understanding and being understood by others. The persistent presence of high error rates in speech recognition domains resulting from mispronunciations motivates us to find alternative techniques for handling mispronunciations. In this study, we develop a mispronunciation assessment system that checks the pronunciation of non-native English speakers, identifies the commonly mispronounced phonemes of Italian learners of English, and presents an evaluation of the non-native pronunciation observed in phonetically annotated speech corpora. In this work, to detect mispronunciations, we used a phone-based ASR implemented using Kaldi. We used two non-native English labeled corpora; (i) a corpus of Italian adults contains 5,867 utterances from 46 speakers, and (ii) a corpus of Italian children consists of 5,268 utterances from 78 children. Our results show that the selected error model can discriminate correct sounds from incorrect sounds in both native and nonnative speech, and therefore can be used to detect pronunciation errors in non-native speech. The phone error rates show improvement in using the error language model. The ASR system shows better accuracy after applying the error model on our selected corpora.