 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual vs Crosslingual Retrieval of Fact-Checked Claims: A Tale of Two Approaches
May 28, 2025Retrieval of previously fact-checked claims is a well-established task, whose automation can assist professional fact-checkers in the initial steps of information verification. Previous works have mostly tackled the task monolingually, i.e., having both the input and the retrieved claims in the same language. However, especially for languages with a limited availability of fact-checks and in case of global narratives, such as pandemics, wars, or international politics, it is crucial to be able to retrieve claims across languages. In this work, we examine strategies to improve the multilingual and crosslingual performance, namely selection of negative examples (in the supervised) and re-ranking (in the unsupervised setting). We evaluate all approaches on a dataset containing posts and claims in 47 languages (283 language combinations). We observe that the best results are obtained by using LLM-based re-ranking, followed by fine-tuning with negative examples sampled using a sentence similarity-based strategy. Most importantly, we show that crosslinguality is a setup with its own unique characteristics compared to the multilingual setup.
Translation in the Hands of Many:Centering Lay Users in Machine Translation Interactions
Feb 19, 2025Converging societal and technical factors have transformed language technologies into user-facing applications employed across languages. Machine Translation (MT) has become a global tool, with cross-lingual services now also supported by dialogue systems powered by multilingual Large Language Models (LLMs). This accessibility has expanded MT's reach to a vast base of lay users, often with little to no expertise in the languages or the technology itself. Despite this, the understanding of MT consumed by this diverse group of users -- their needs, experiences, and interactions with these systems -- remains limited. This paper traces the shift in MT user profiles, focusing on non-expert users and how their engagement with these systems may change with LLMs. We identify three key factors -- usability, trust, and literacy -- that shape these interactions and must be addressed to align MT with user needs. By exploring these dimensions, we offer insights to guide future MT with a user-centered approach.
Fine-grained Fallacy Detection with Human Label Variation
Feb 19, 2025
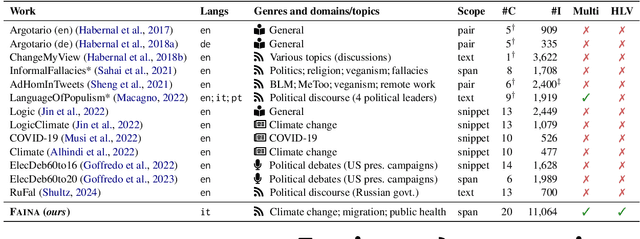
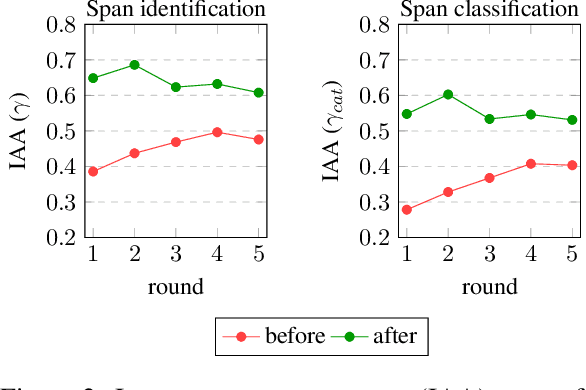
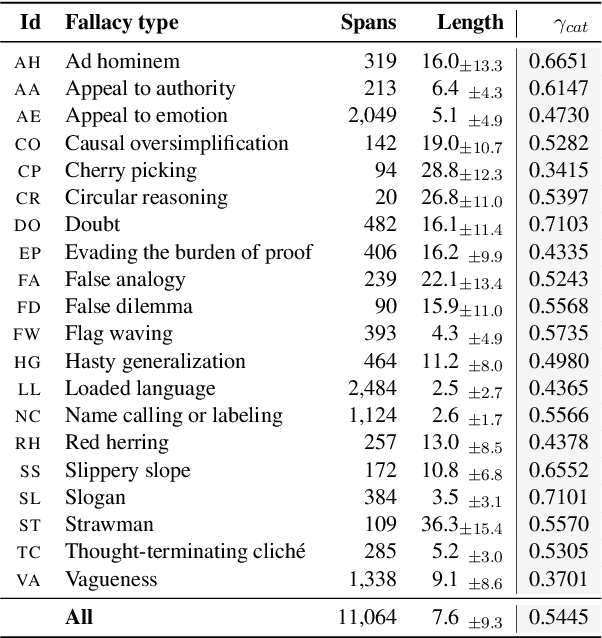
We introduce Faina, the first dataset for fallacy detection that embraces multiple plausible answers and natural disagreement. Faina includes over 11K span-level annotations with overlaps across 20 fallacy types on social media posts in Italian about migration, climate change, and public health given by two expert annotators. Through an extensive annotation study that allowed discussion over multiple rounds, we minimize annotation errors whilst keeping signals of human label variation. Moreover, we devise a framework that goes beyond "single ground truth" evaluation and simultaneously accounts for multiple (equally reliable) test sets and the peculiarities of the task, i.e., partial span matches, overlaps, and the varying severity of labeling errors. Our experiments across four fallacy detection setups show that multi-task and multi-label transformer-based approaches are strong baselines across all settings. We release our data, code, and annotation guidelines to foster research on fallacy detection and human label variation more broadly.
Variationist: Exploring Multifaceted Variation and Bias in Written Language Data
Jun 25, 2024



Exploring and understanding language data is a fundamental stage in all areas dealing with human language. It allows NLP practitioners to uncover quality concerns and harmful biases in data before training, and helps linguists and social scientists to gain insight into language use and human behavior. Yet, there is currently a lack of a unified, customizable tool to seamlessly inspect and visualize language variation and bias across multiple variables, language units, and diverse metrics that go beyond descriptive statistics. In this paper, we introduce Variationist, a highly-modular, extensible, and task-agnostic tool that fills this gap. Variationist handles at once a potentially unlimited combination of variable types and semantics across diversity and association metrics with regards to the language unit of choice, and orchestrates the creation of up to five-dimensional interactive charts for over 30 variable type-semantics combinations. Through our case studies on computational dialectology, human label variation, and text generation, we show how Variationist enables researchers from different disciplines to effortlessly answer specific research questions or unveil undesired associations in language data. A Python library, code, documentation, and tutorials are made publicly available to the research community.
NLP for Language Varieties of Italy: Challenges and the Path Forward
Sep 20, 2022



Italy is characterized by a one-of-a-kind linguistic diversity landscape in Europe, which implicitly encodes local knowledge, cultural traditions, artistic expression, and history of its speakers. However, over 30 language varieties in Italy are at risk of disappearing within few generations. Language technology has a main role in preserving endangered languages, but it currently struggles with such varieties as they are under-resourced and mostly lack standardized orthography, being mainly used in spoken settings. In this paper, we introduce the linguistic context of Italy and discuss challenges facing the development of NLP technologies for Italy's language varieties. We provide potential directions and advocate for a shift in the paradigm from machine-centric to speaker-centric NLP. Finally, we propose building a local community towards responsible, participatory development of speech and language technologies for languages and dialects of Italy.
From Masked Language Modeling to Translation: Non-English Auxiliary Tasks Improve Zero-shot Spoken Language Understanding
May 15, 2021



The lack of publicly available evaluation data for low-resource languages limits progress in Spoken Language Understanding (SLU). As key tasks like intent classification and slot filling require abundant training data, it is desirable to reuse existing data in high-resource languages to develop models for low-resource scenarios. We introduce xSID, a new benchmark for cross-lingual Slot and Intent Detection in 13 languages from 6 language families, including a very low-resource dialect. To tackle the challenge, we propose a joint learning approach, with English SLU training data and non-English auxiliary tasks from raw text, syntax and translation for transfer. We study two setups which differ by type and language coverage of the pre-trained embeddings. Our results show that jointly learning the main tasks with masked language modeling is effective for slots, while machine translation transfer works best for intent classification.
Massive Choice, Ample Tasks :A Toolkit for Multi-task Learning in NLP
Jun 08, 2020



Transfer learning, particularly approaches that combine multi-task learning with pre-trained contextualized embeddings and fine-tuning, have advanced the field of Natural Language Processing tremendously in recent years. In this paper we present MaChAmp, a toolkit for easy use of fine-tuning BERT-like models in multi-task settings. The benefits of MaChAmp are its flexible configuration options, and the support of a variety of NLP tasks in a uniform toolkit, from text classification to sequence labeling and dependency parsing.
Neural Unsupervised Domain Adaptation in NLP---A Survey
May 31, 2020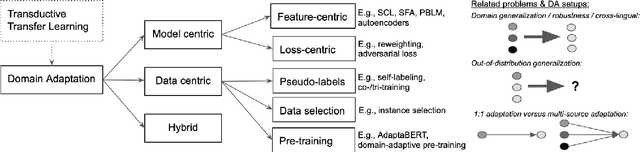
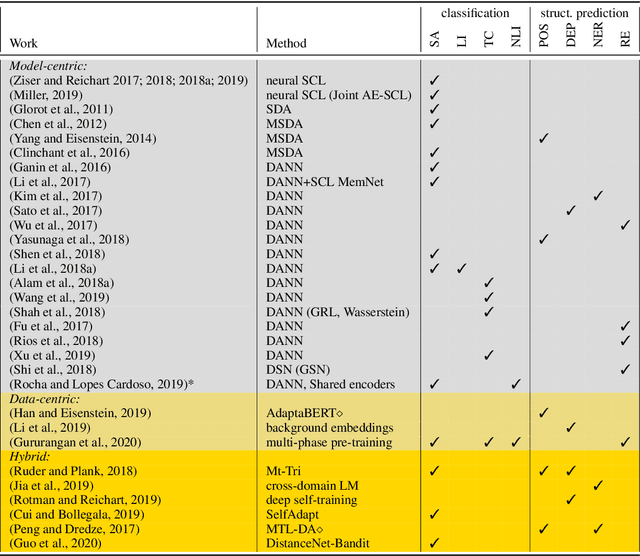
Deep neural networks excel at learning from labeled data and achieve state-of-the-art results on a wide array of Natural Language Processing tasks. In contrast, learning from unlabeled data, especially under domain shift, remains a challenge. Motivated by the latest advances, in this survey we review neural unsupervised domain adaptation techniques which do not require labeled target domain data. This is a more challenging yet a more widely applicable setup. We outline methods, from early approaches in traditional non-neural methods to pre-trained model transfer. We also revisit the notion of domain, and we uncover a bias in the type of Natural Language Processing tasks which received most attention. Lastly, we outline future directions, particularly the broader need for out-of-distribution generalization of future intelligent NLP.