 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Unsupervised Domain Adaptation in NLP---A Survey
Paper and Code
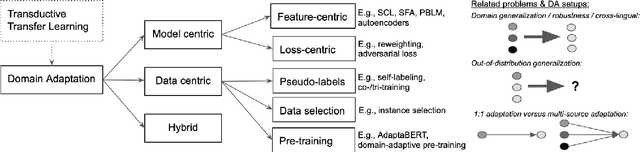
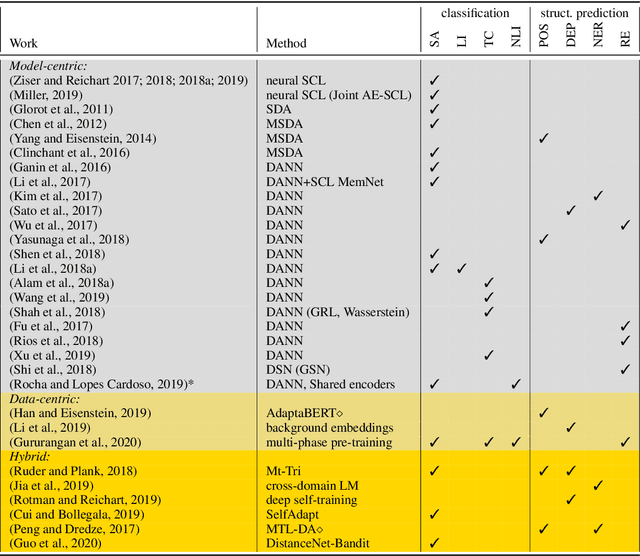
Deep neural networks excel at learning from labeled data and achieve state-of-the-art results on a wide array of Natural Language Processing tasks. In contrast, learning from unlabeled data, especially under domain shift, remains a challenge. Motivated by the latest advances, in this survey we review neural unsupervised domain adaptation techniques which do not require labeled target domain data. This is a more challenging yet a more widely applicable setup. We outline methods, from early approaches in traditional non-neural methods to pre-trained model transfer. We also revisit the notion of domain, and we uncover a bias in the type of Natural Language Processing tasks which received most attention. Lastly, we outline future directions, particularly the broader need for out-of-distribution generalization of future intelligent NLP.