 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGender Bias in Masked Language Models for Multiple Languages
May 04, 2022
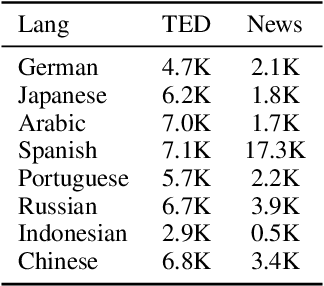


Masked Language Models (MLMs) pre-trained by predicting masked tokens on large corpora have been used successfully in natural language processing tasks for a variety of languages. Unfortunately, it was reported that MLMs also learn discriminative biases regarding attributes such as gender and race. Because most studies have focused on MLMs in English, the bias of MLMs in other languages has rarely been investigated. Manual annotation of evaluation data for languages other than English has been challenging due to the cost and difficulty in recruiting annotators. Moreover, the existing bias evaluation methods require the stereotypical sentence pairs consisting of the same context with attribute words (e.g. He/She is a nurse). We propose Multilingual Bias Evaluation (MBE) score, to evaluate bias in various languages using only English attribute word lists and parallel corpora between the target language and English without requiring manually annotated data. We evaluated MLMs in eight languages using the MBE and confirmed that gender-related biases are encoded in MLMs for all those languages. We manually created datasets for gender bias in Japanese and Russian to evaluate the validity of the MBE. The results show that the bias scores reported by the MBE significantly correlates with that computed from the above manually created datasets and the existing English datasets for gender bias.
Neural Combinatory Constituency Parsing
Jun 12, 2021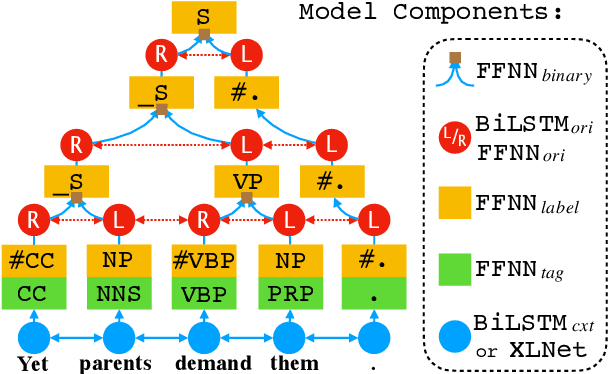

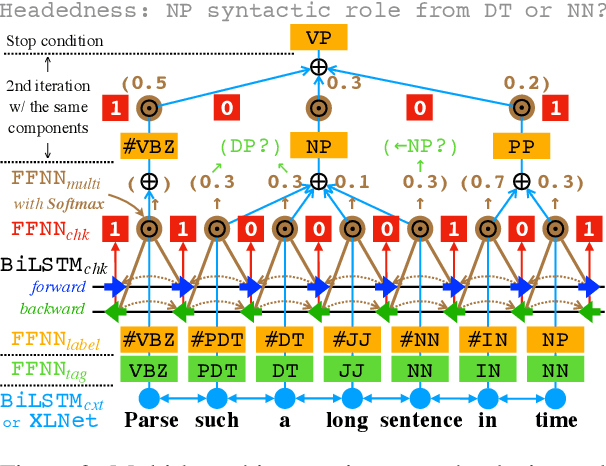

We propose two fast neural combinatory models for constituency parsing: binary and multi-branching. Our models decompose the bottom-up parsing process into 1) classification of tags, labels, and binary orientations or chunks and 2) vector composition based on the computed orientations or chunks. These models have theoretical sub-quadratic complexity and empirical linear complexity. The binary model achieves an F1 score of 92.54 on Penn Treebank, speeding at 1327.2 sents/sec. Both the models with XLNet provide near state-of-the-art accuracies for English. Syntactic branching tendency and headedness of a language are observed during the training and inference processes for Penn Treebank, Chinese Treebank, and Keyaki Treebank (Japanese).
From Masked Language Modeling to Translation: Non-English Auxiliary Tasks Improve Zero-shot Spoken Language Understanding
May 15, 2021



The lack of publicly available evaluation data for low-resource languages limits progress in Spoken Language Understanding (SLU). As key tasks like intent classification and slot filling require abundant training data, it is desirable to reuse existing data in high-resource languages to develop models for low-resource scenarios. We introduce xSID, a new benchmark for cross-lingual Slot and Intent Detection in 13 languages from 6 language families, including a very low-resource dialect. To tackle the challenge, we propose a joint learning approach, with English SLU training data and non-English auxiliary tasks from raw text, syntax and translation for transfer. We study two setups which differ by type and language coverage of the pre-trained embeddings. Our results show that jointly learning the main tasks with masked language modeling is effective for slots, while machine translation transfer works best for intent classification.
Simultaneous Multi-Pivot Neural Machine Translation
Apr 15, 2021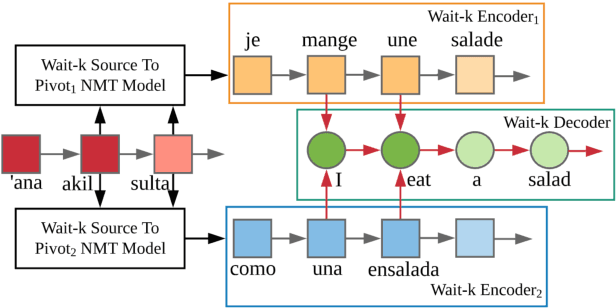


Parallel corpora are indispensable for training neural machine translation (NMT) models, and parallel corpora for most language pairs do not exist or are scarce. In such cases, pivot language NMT can be helpful where a pivot language is used such that there exist parallel corpora between the source and pivot and pivot and target languages. Naturally, the quality of pivot language translation is more inferior to what could be achieved with a direct parallel corpus of a reasonable size for that pair. In a real-time simultaneous translation setting, the quality of pivot language translation deteriorates even further given that the model has to output translations the moment a few source words become available. To solve this issue, we propose multi-pivot translation and apply it to a simultaneous translation setting involving pivot languages. Our approach involves simultaneously translating a source language into multiple pivots, which are then simultaneously translated together into the target language by leveraging multi-source NMT. Our experiments in a low-resource setting using the N-way parallel UN corpus for Arabic to English NMT via French and Spanish as pivots reveals that in a simultaneous pivot NMT setting, using two pivot languages can lead to an improvement of up to 5.8 BLEU.
Towards Multimodal Simultaneous Neural Machine Translation
Apr 07, 2020



Simultaneous translation involves translating a sentence before the speaker's utterance is completed in order to realize real-time understanding in multiple languages. This task is significantly harder than the general full sentence translation because of the shortage of input information during decoding. To alleviate this shortage, we propose multimodal simultaneous neural machine translation (MSNMT) which leverages visual information as an additional modality. Although the usefulness of images as an additional modality is moderate for full sentence translation, we verified, for the first time, its importance for simultaneous translation. Our experiments with the Multi30k dataset showed that MSNMT in a simultaneous setting significantly outperforms its text-only counterpart in situations where 5 or fewer input tokens are needed to begin translation. We then verified the importance of visual information during decoding by (a) performing an adversarial evaluation of MSNMT where we studied how models behave with incongruent input modality and (b) analyzing the image attention.
Exploiting Out-of-Domain Parallel Data through Multilingual Transfer Learning for Low-Resource Neural Machine Translation
Jul 06, 2019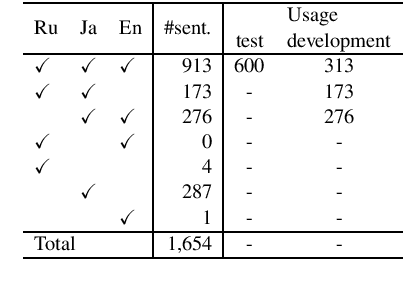
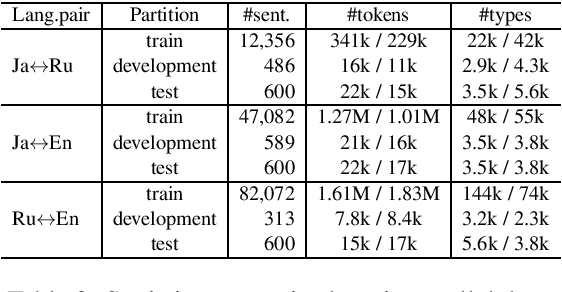
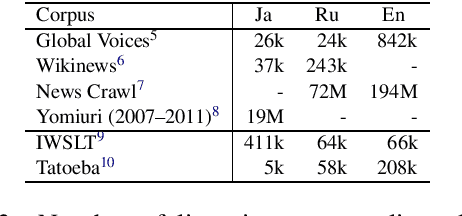
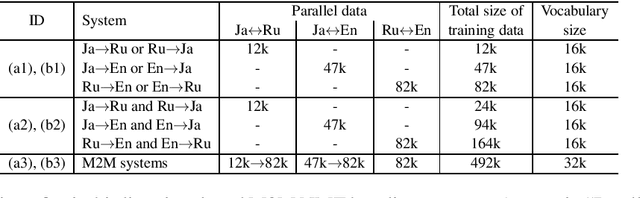
This paper proposes a novel multilingual multistage fine-tuning approach for low-resource neural machine translation (NMT), taking a challenging Japanese--Russian pair for benchmarking. Although there are many solutions for low-resource scenarios, such as multilingual NMT and back-translation, we have empirically confirmed their limited success when restricted to in-domain data. We therefore propose to exploit out-of-domain data through transfer learning, by using it to first train a multilingual NMT model followed by multistage fine-tuning on in-domain parallel and back-translated pseudo-parallel data. Our approach, which combines domain adaptation, multilingualism, and back-translation, helps improve the translation quality by more than 3.7 BLEU points, over a strong baseline, for this extremely low-resource scenario.