 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the Effects of Alignment on Numerical Bias in Large Language Models
Jan 26, 2026"LLM-as-a-judge," which utilizes large language models (LLMs) as evaluators, has proven effective in many evaluation tasks. However, evaluator LLMs exhibit numerical bias, a phenomenon where certain evaluation scores are generated disproportionately often, leading reduced evaluation performance. This study investigates the cause of this bias. Given that most evaluator LLMs are aligned through instruction tuning and preference tuning, and that prior research suggests alignment reduces output diversity, we hypothesize that numerical bias arises from alignment. To test this, we compare outputs from pre- and post-alignment LLMs, and observe that alignment indeed increases numerical bias. We also explore mitigation strategies for post-alignment LLMs, including temperature scaling, distribution calibration, and score range adjustment. Among these, score range adjustment is most effective in reducing bias and improving performance, though still heuristic. Our findings highlight the need for further work on optimal score range selection and more robust mitigation strategies.
Neural Combinatory Constituency Parsing
Jun 12, 2021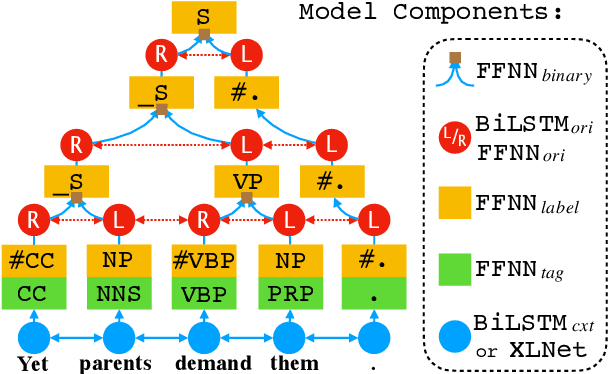

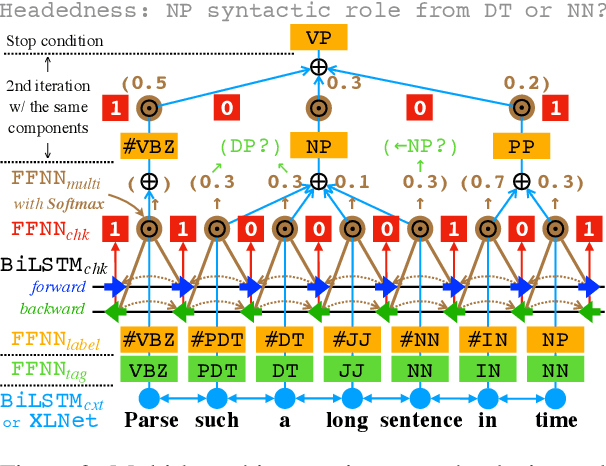

We propose two fast neural combinatory models for constituency parsing: binary and multi-branching. Our models decompose the bottom-up parsing process into 1) classification of tags, labels, and binary orientations or chunks and 2) vector composition based on the computed orientations or chunks. These models have theoretical sub-quadratic complexity and empirical linear complexity. The binary model achieves an F1 score of 92.54 on Penn Treebank, speeding at 1327.2 sents/sec. Both the models with XLNet provide near state-of-the-art accuracies for English. Syntactic branching tendency and headedness of a language are observed during the training and inference processes for Penn Treebank, Chinese Treebank, and Keyaki Treebank (Japanese).