 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Combinatory Constituency Parsing
Jun 12, 2021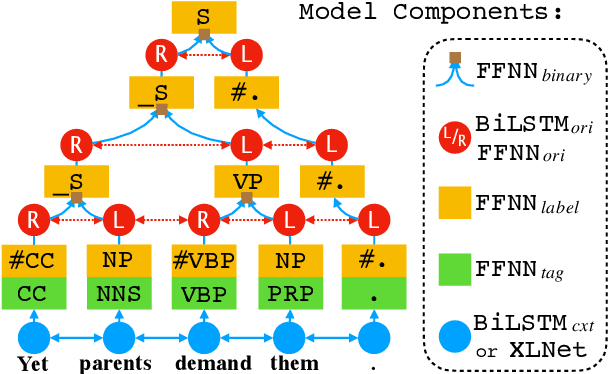

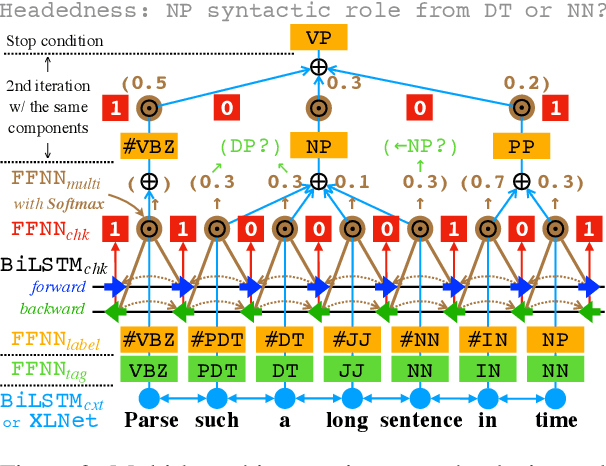

We propose two fast neural combinatory models for constituency parsing: binary and multi-branching. Our models decompose the bottom-up parsing process into 1) classification of tags, labels, and binary orientations or chunks and 2) vector composition based on the computed orientations or chunks. These models have theoretical sub-quadratic complexity and empirical linear complexity. The binary model achieves an F1 score of 92.54 on Penn Treebank, speeding at 1327.2 sents/sec. Both the models with XLNet provide near state-of-the-art accuracies for English. Syntactic branching tendency and headedness of a language are observed during the training and inference processes for Penn Treebank, Chinese Treebank, and Keyaki Treebank (Japanese).
Simpson's Bias in NLP Training
Mar 13, 2021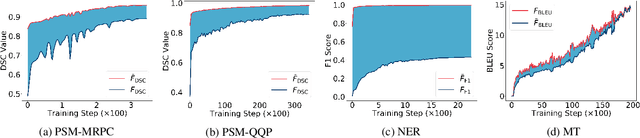
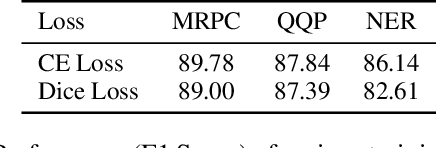
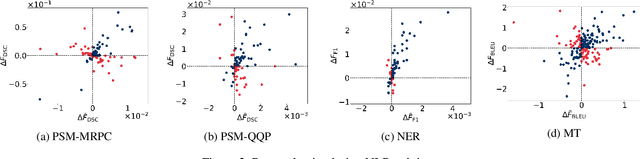
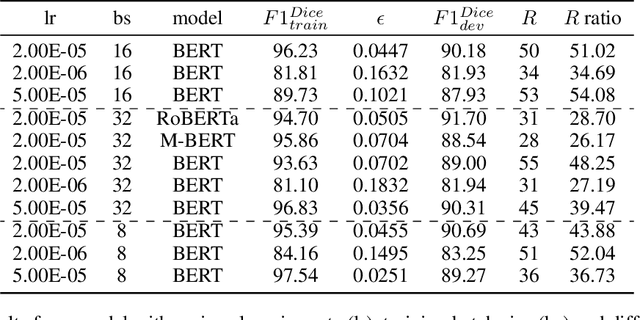
In most machine learning tasks, we evaluate a model $M$ on a given data population $S$ by measuring a population-level metric $F(S;M)$. Examples of such evaluation metric $F$ include precision/recall for (binary) recognition, the F1 score for multi-class classification, and the BLEU metric for language generation. On the other hand, the model $M$ is trained by optimizing a sample-level loss $G(S_t;M)$ at each learning step $t$, where $S_t$ is a subset of $S$ (a.k.a. the mini-batch). Popular choices of $G$ include cross-entropy loss, the Dice loss, and sentence-level BLEU scores. A fundamental assumption behind this paradigm is that the mean value of the sample-level loss $G$, if averaged over all possible samples, should effectively represent the population-level metric $F$ of the task, such as, that $\mathbb{E}[ G(S_t;M) ] \approx F(S;M)$. In this paper, we systematically investigate the above assumption in several NLP tasks. We show, both theoretically and experimentally, that some popular designs of the sample-level loss $G$ may be inconsistent with the true population-level metric $F$ of the task, so that models trained to optimize the former can be substantially sub-optimal to the latter, a phenomenon we call it, Simpson's bias, due to its deep connections with the classic paradox known as Simpson's reversal paradox in statistics and social sciences.
Chinese-Japanese Unsupervised Neural Machine Translation Using Sub-character Level Information
Mar 01, 2019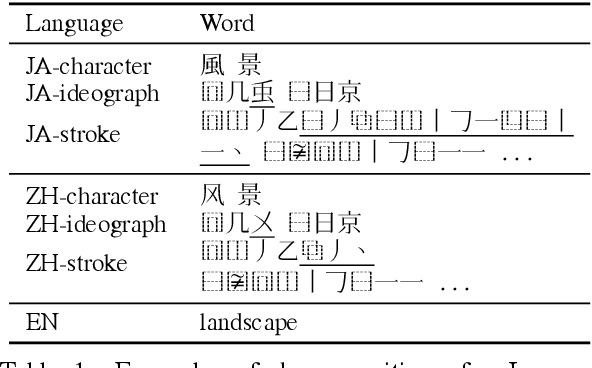
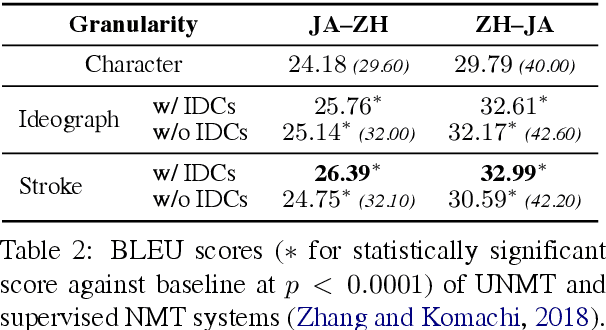
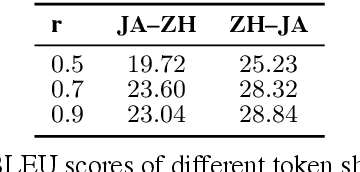

Unsupervised neural machine translation (UNMT) requires only monolingual data of similar language pairs during training and can produce bi-directional translation models with relatively good performance on alphabetic languages (Lample et al., 2018). However, no research has been done to logographic language pairs. This study focuses on Chinese-Japanese UNMT trained by data containing sub-character (ideograph or stroke) level information which is decomposed from character level data. BLEU scores of both character and sub-character level systems were compared against each other and the results showed that despite the effectiveness of UNMT on character level data, sub-character level data could further enhance the performance, in which the stroke level system outperformed the ideograph level system.
Neural Machine Translation of Logographic Languages Using Sub-character Level Information
Sep 07, 2018



Recent neural machine translation (NMT) systems have been greatly improved by encoder-decoder models with attention mechanisms and sub-word units. However, important differences between languages with logographic and alphabetic writing systems have long been overlooked. This study focuses on these differences and uses a simple approach to improve the performance of NMT systems utilizing decomposed sub-character level information for logographic languages. Our results indicate that our approach not only improves the translation capabilities of NMT systems between Chinese and English, but also further improves NMT systems between Chinese and Japanese, because it utilizes the shared information brought by similar sub-character units.