 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChinese-Japanese Unsupervised Neural Machine Translation Using Sub-character Level Information
Paper and Code
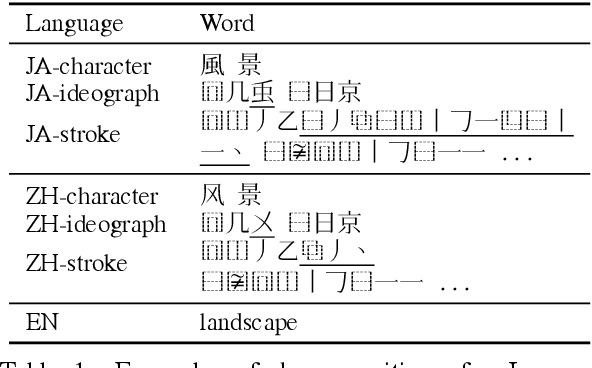
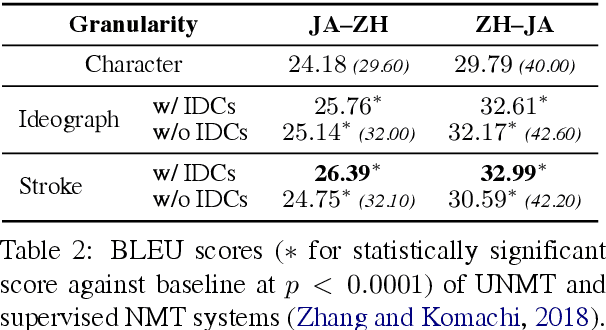
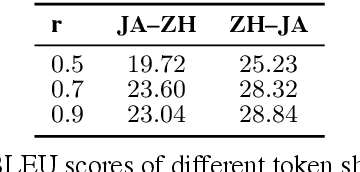

Unsupervised neural machine translation (UNMT) requires only monolingual data of similar language pairs during training and can produce bi-directional translation models with relatively good performance on alphabetic languages (Lample et al., 2018). However, no research has been done to logographic language pairs. This study focuses on Chinese-Japanese UNMT trained by data containing sub-character (ideograph or stroke) level information which is decomposed from character level data. BLEU scores of both character and sub-character level systems were compared against each other and the results showed that despite the effectiveness of UNMT on character level data, sub-character level data could further enhance the performance, in which the stroke level system outperformed the ideograph level system.