 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the Effects of Alignment on Numerical Bias in Large Language Models
Jan 26, 2026"LLM-as-a-judge," which utilizes large language models (LLMs) as evaluators, has proven effective in many evaluation tasks. However, evaluator LLMs exhibit numerical bias, a phenomenon where certain evaluation scores are generated disproportionately often, leading reduced evaluation performance. This study investigates the cause of this bias. Given that most evaluator LLMs are aligned through instruction tuning and preference tuning, and that prior research suggests alignment reduces output diversity, we hypothesize that numerical bias arises from alignment. To test this, we compare outputs from pre- and post-alignment LLMs, and observe that alignment indeed increases numerical bias. We also explore mitigation strategies for post-alignment LLMs, including temperature scaling, distribution calibration, and score range adjustment. Among these, score range adjustment is most effective in reducing bias and improving performance, though still heuristic. Our findings highlight the need for further work on optimal score range selection and more robust mitigation strategies.
Assessing the Capabilities of LLMs in Humor:A Multi-dimensional Analysis of Oogiri Generation and Evaluation
Nov 12, 2025



Computational humor is a frontier for creating advanced and engaging natural language processing (NLP) applications, such as sophisticated dialogue systems. While previous studies have benchmarked the humor capabilities of Large Language Models (LLMs), they have often relied on single-dimensional evaluations, such as judging whether something is simply ``funny.'' This paper argues that a multifaceted understanding of humor is necessary and addresses this gap by systematically evaluating LLMs through the lens of Oogiri, a form of Japanese improvisational comedy games. To achieve this, we expanded upon existing Oogiri datasets with data from new sources and then augmented the collection with Oogiri responses generated by LLMs. We then manually annotated this expanded collection with 5-point absolute ratings across six dimensions: Novelty, Clarity, Relevance, Intelligence, Empathy, and Overall Funniness. Using this dataset, we assessed the capabilities of state-of-the-art LLMs on two core tasks: their ability to generate creative Oogiri responses and their ability to evaluate the funniness of responses using a six-dimensional evaluation. Our results show that while LLMs can generate responses at a level between low- and mid-tier human performance, they exhibit a notable lack of Empathy. This deficit in Empathy helps explain their failure to replicate human humor assessment. Correlation analyses of human and model evaluation data further reveal a fundamental divergence in evaluation criteria: LLMs prioritize Novelty, whereas humans prioritize Empathy. We release our annotated corpus to the community to pave the way for the development of more emotionally intelligent and sophisticated conversational agents.
Pruning Multilingual Large Language Models for Multilingual Inference
Sep 25, 2024Multilingual large language models (MLLMs), trained on multilingual balanced data, demonstrate better zero-shot learning performance in non-English languages compared to large language models trained on English-dominant data. However, the disparity in performance between English and non-English languages remains a challenge yet to be fully addressed. A distinctive characteristic of MLLMs is their high-quality translation capabilities, indicating an acquired proficiency in aligning between languages. This study explores how to enhance the zero-shot performance of MLLMs in non-English languages by leveraging their alignment capability between English and non-English languages. To achieve this, we first analyze the behavior of MLLMs when performing translation and reveal that there are large magnitude features that play a critical role in the translation process. Inspired by these findings, we retain the weights associated with operations involving the large magnitude features and prune other weights to force MLLMs to rely on these features for tasks beyond translation. We empirically demonstrate that this pruning strategy can enhance the MLLMs' performance in non-English language.
A Single Linear Layer Yields Task-Adapted Low-Rank Matrices
Mar 22, 2024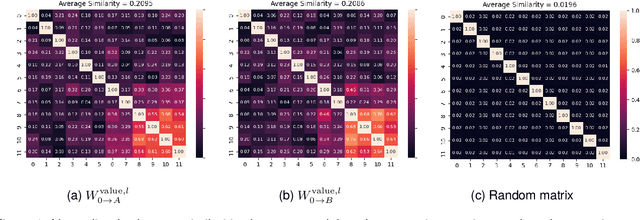
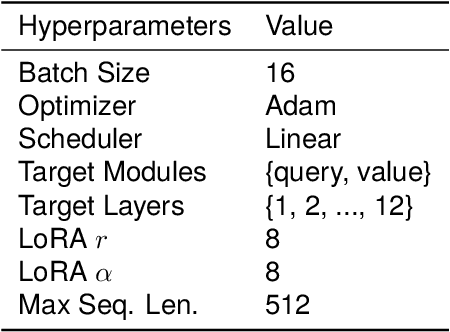

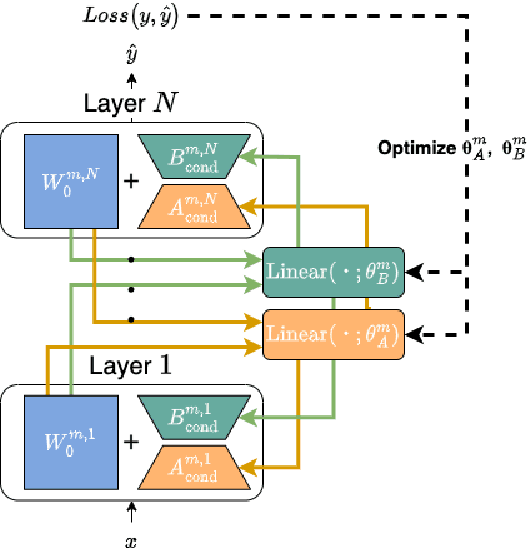
Low-Rank Adaptation (LoRA) is a widely used Parameter-Efficient Fine-Tuning (PEFT) method that updates an initial weight matrix $W_0$ with a delta matrix $\Delta W$ consisted by two low-rank matrices $A$ and $B$. A previous study suggested that there is correlation between $W_0$ and $\Delta W$. In this study, we aim to delve deeper into relationships between $W_0$ and low-rank matrices $A$ and $B$ to further comprehend the behavior of LoRA. In particular, we analyze a conversion matrix that transform $W_0$ into low-rank matrices, which encapsulates information about the relationships. Our analysis reveals that the conversion matrices are similar across each layer. Inspired by these findings, we hypothesize that a single linear layer, which takes each layer's $W_0$ as input, can yield task-adapted low-rank matrices. To confirm this hypothesis, we devise a method named Conditionally Parameterized LoRA (CondLoRA) that updates initial weight matrices with low-rank matrices derived from a single linear layer. Our empirical results show that CondLoRA maintains a performance on par with LoRA, despite the fact that the trainable parameters of CondLoRA are fewer than those of LoRA. Therefore, we conclude that "a single linear layer yields task-adapted low-rank matrices."
Learning How to Translate North Korean through South Korean
Jan 27, 2022
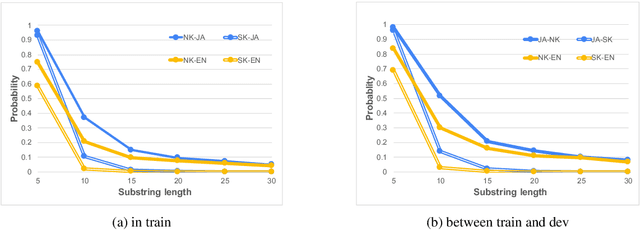

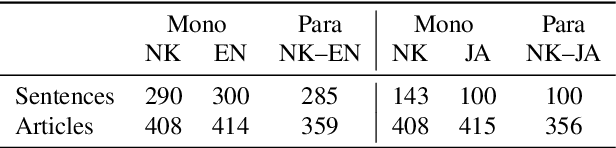
South and North Korea both use the Korean language. However, Korean NLP research has focused on South Korean only, and existing NLP systems of the Korean language, such as neural machine translation (NMT) models, cannot properly handle North Korean inputs. Training a model using North Korean data is the most straightforward approach to solving this problem, but there is insufficient data to train NMT models. In this study, we create data for North Korean NMT models using a comparable corpus. First, we manually create evaluation data for automatic alignment and machine translation. Then, we investigate automatic alignment methods suitable for North Korean. Finally, we verify that a model trained by North Korean bilingual data without human annotation can significantly boost North Korean translation accuracy compared to existing South Korean models in zero-shot settings.