 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBit-level BPE: Below the byte boundary
Jun 09, 2025Byte-level fallbacks for subword tokenization have become a common practice in large language models. In particular, it has been demonstrated to be incredibly effective as a pragmatic solution for preventing OOV, especially in the context of larger models. However, breaking a character down to individual bytes significantly increases the sequence length for long-tail tokens in languages such as Chinese, Japanese, and Korean (CJK) and other character-diverse contexts such as emoji. The increased sequence length results in longer computation during both training and inference. In this work, we propose a simple compression technique that reduces the sequence length losslessly.
Two Counterexamples to Tokenization and the Noiseless Channel
Feb 29, 2024In Tokenization and the Noiseless Channel (Zouhar et al., 2023a), R\'enyi efficiency is suggested as an intrinsic mechanism for evaluating a tokenizer: for NLP tasks, the tokenizer which leads to the highest R\'enyi efficiency of the unigram distribution should be chosen. The R\'enyi efficiency is thus treated as a predictor of downstream performance (e.g., predicting BLEU for a machine translation task), without the expensive step of training multiple models with different tokenizers. Although useful, the predictive power of this metric is not perfect, and the authors note there are additional qualities of a good tokenization scheme that R\'enyi efficiency alone cannot capture. We describe two variants of BPE tokenization which can arbitrarily increase R\'enyi efficiency while decreasing the downstream model performance. These counterexamples expose cases where R\'enyi efficiency fails as an intrinsic tokenization metric and thus give insight for building more accurate predictors.
Learning How to Translate North Korean through South Korean
Jan 27, 2022
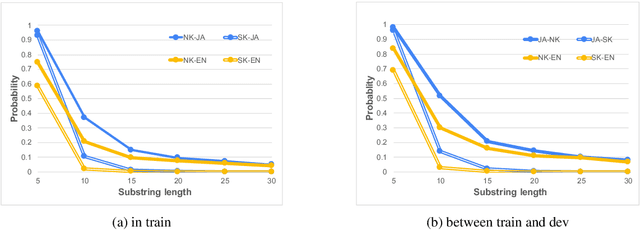

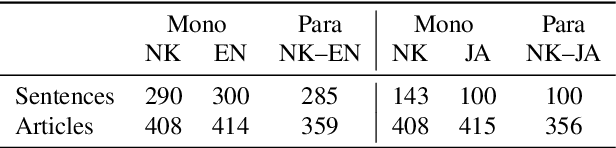
South and North Korea both use the Korean language. However, Korean NLP research has focused on South Korean only, and existing NLP systems of the Korean language, such as neural machine translation (NMT) models, cannot properly handle North Korean inputs. Training a model using North Korean data is the most straightforward approach to solving this problem, but there is insufficient data to train NMT models. In this study, we create data for North Korean NMT models using a comparable corpus. First, we manually create evaluation data for automatic alignment and machine translation. Then, we investigate automatic alignment methods suitable for North Korean. Finally, we verify that a model trained by North Korean bilingual data without human annotation can significantly boost North Korean translation accuracy compared to existing South Korean models in zero-shot settings.
StyleKQC: A Style-Variant Paraphrase Corpus for Korean Questions and Commands
Mar 24, 2021
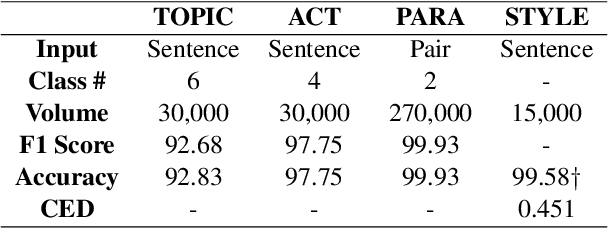
Paraphrasing is often performed with less concern for controlled style conversion. Especially for questions and commands, style-variant paraphrasing can be crucial in tone and manner, which also matters with industrial applications such as dialog system. In this paper, we attack this issue with a corpus construction scheme that simultaneously considers the core content and style of directives, namely intent and formality, for the Korean language. Utilizing manually generated natural language queries on six daily topics, we expand the corpus to formal and informal sentences by human rewriting and transferring. We verify the validity and industrial applicability of our approach by checking the adequate classification and inference performance that fit with the fine-tuning approaches, at the same time proposing a supervised formality transfer task.
Open Korean Corpora: A Practical Report
Dec 31, 2020
Korean is often referred to as a low-resource language in the research community. While this claim is partially true, it is also because the availability of resources is inadequately advertised and curated. This work curates and reviews a list of Korean corpora, first describing institution-level resource development, then further iterate through a list of current open datasets for different types of tasks. We then propose a direction on how open-source dataset construction and releases should be done for less-resourced languages to promote research.
Machines Getting with the Program: Understanding Intent Arguments of Non-Canonical Directives
Dec 01, 2019
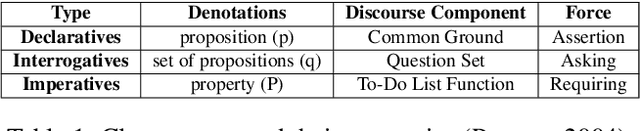
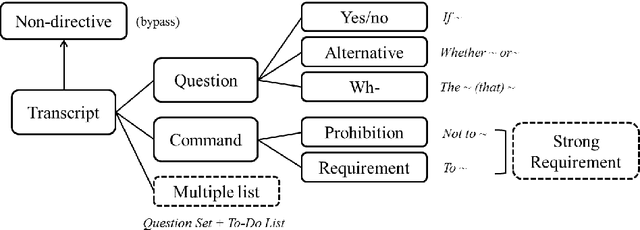
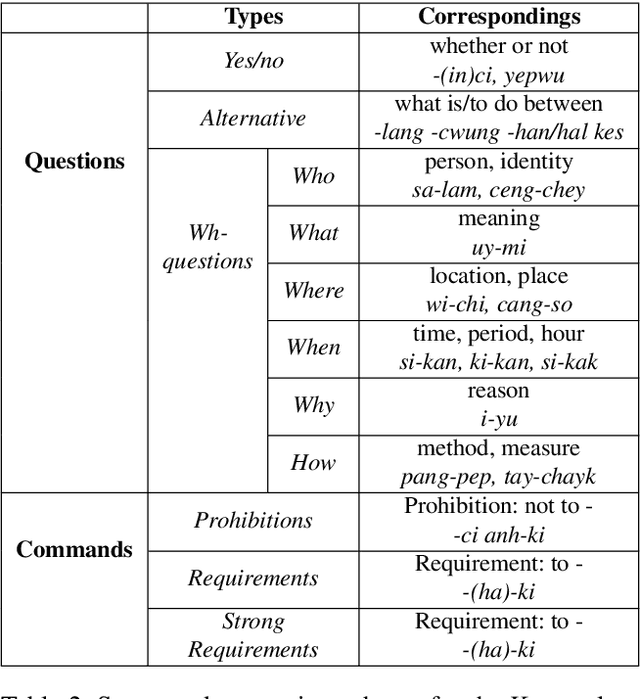
Modern dialog managers face the challenge of having to fulfill human-level conversational skills as part of common user expectations, including but not limited to discourse with no clear objective. Along with these requirements, agents are expected to extrapolate intent from the user's dialogue even when subjected to non-canonical forms of speech. This depends on the agent's comprehension of paraphrased forms of such utterances. In low-resource languages, the lack of data is a bottleneck that prevents advancements of the comprehension performance for these types of agents. In this paper, we demonstrate the necessity of being able to extract the intent argument of non-canonical directives, and also define guidelines for building paired corpora for this purpose. Following the guidelines, we label a dataset consisting of 30K instances of question/command-intent pairs, including annotations for a classification task for predicting the utterance type. We also propose a method for mitigating class imbalance in the final dataset, and demonstrate the potential applications of the corpus generation method and dataset.