 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachines Getting with the Program: Understanding Intent Arguments of Non-Canonical Directives
Paper and Code
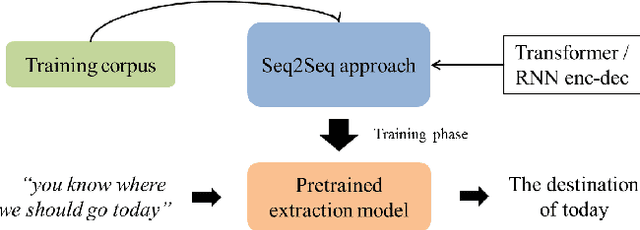
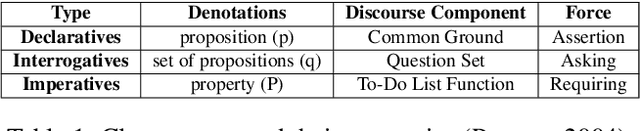
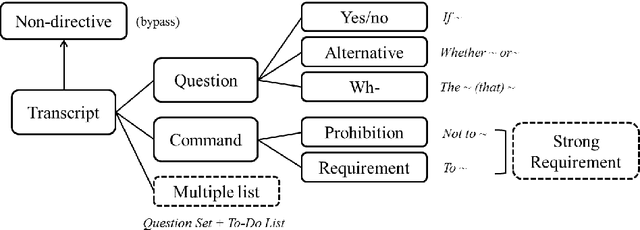
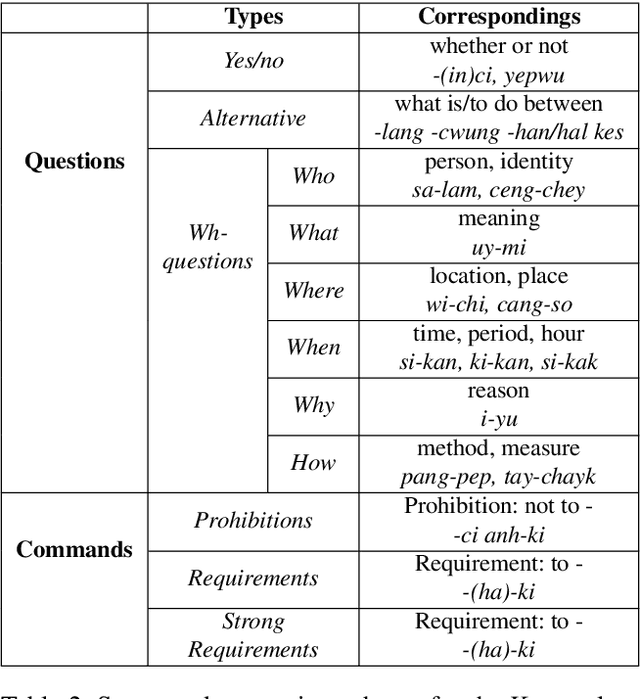
Modern dialog managers face the challenge of having to fulfill human-level conversational skills as part of common user expectations, including but not limited to discourse with no clear objective. Along with these requirements, agents are expected to extrapolate intent from the user's dialogue even when subjected to non-canonical forms of speech. This depends on the agent's comprehension of paraphrased forms of such utterances. In low-resource languages, the lack of data is a bottleneck that prevents advancements of the comprehension performance for these types of agents. In this paper, we demonstrate the necessity of being able to extract the intent argument of non-canonical directives, and also define guidelines for building paired corpora for this purpose. Following the guidelines, we label a dataset consisting of 30K instances of question/command-intent pairs, including annotations for a classification task for predicting the utterance type. We also propose a method for mitigating class imbalance in the final dataset, and demonstrate the potential applications of the corpus generation method and dataset.