 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtending the Subwording Model of Multilingual Pretrained Models for New Languages
Nov 29, 2022Multilingual pretrained models are effective for machine translation and cross-lingual processing because they contain multiple languages in one model. However, they are pretrained after their tokenizers are fixed; therefore it is difficult to change the vocabulary after pretraining. When we extend the pretrained models to new languages, we must modify the tokenizers simultaneously. In this paper, we add new subwords to the SentencePiece tokenizer to apply a multilingual pretrained model to new languages (Inuktitut in this paper). In our experiments, we segmented Inuktitut sentences into subwords without changing the segmentation of already pretrained languages, and applied the mBART-50 pretrained model to English-Inuktitut translation.
Exploiting Out-of-Domain Parallel Data through Multilingual Transfer Learning for Low-Resource Neural Machine Translation
Jul 06, 2019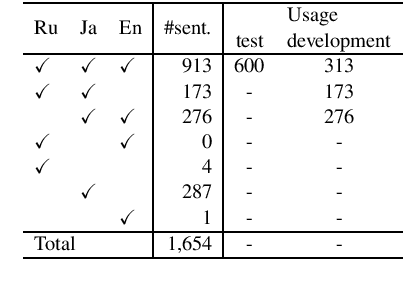
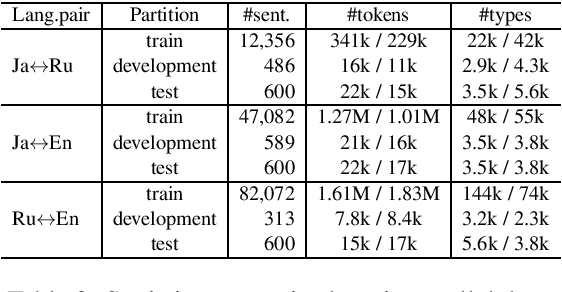
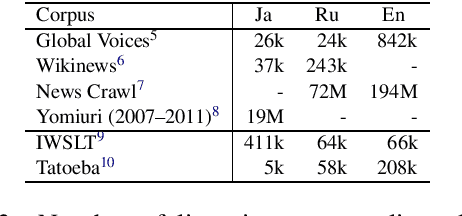
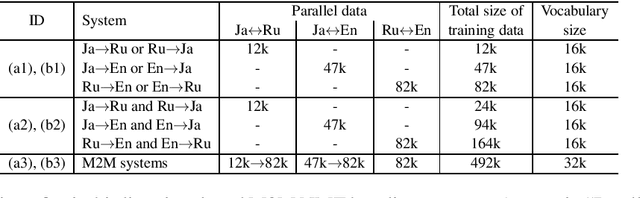
This paper proposes a novel multilingual multistage fine-tuning approach for low-resource neural machine translation (NMT), taking a challenging Japanese--Russian pair for benchmarking. Although there are many solutions for low-resource scenarios, such as multilingual NMT and back-translation, we have empirically confirmed their limited success when restricted to in-domain data. We therefore propose to exploit out-of-domain data through transfer learning, by using it to first train a multilingual NMT model followed by multistage fine-tuning on in-domain parallel and back-translated pseudo-parallel data. Our approach, which combines domain adaptation, multilingualism, and back-translation, helps improve the translation quality by more than 3.7 BLEU points, over a strong baseline, for this extremely low-resource scenario.