 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Target-Aware Analysis of Data Augmentation for Hate Speech Detection
Oct 10, 2024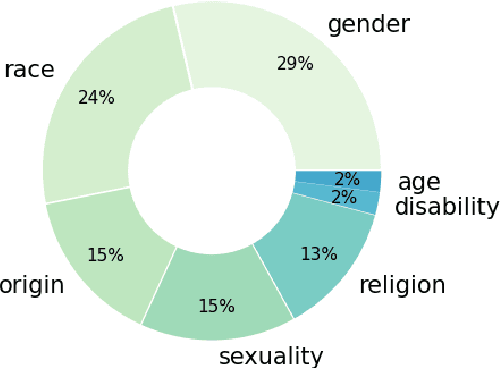

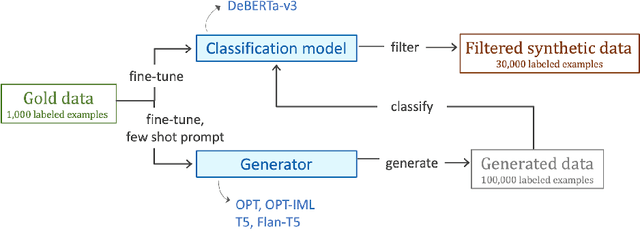

Hate speech is one of the main threats posed by the widespread use of social networks, despite efforts to limit it. Although attention has been devoted to this issue, the lack of datasets and case studies centered around scarcely represented phenomena, such as ableism or ageism, can lead to hate speech detection systems that do not perform well on underrepresented identity groups. Given the unpreceded capabilities of LLMs in producing high-quality data, we investigate the possibility of augmenting existing data with generative language models, reducing target imbalance. We experiment with augmenting 1,000 posts from the Measuring Hate Speech corpus, an English dataset annotated with target identity information, adding around 30,000 synthetic examples using both simple data augmentation methods and different types of generative models, comparing autoregressive and sequence-to-sequence approaches. We find traditional DA methods to often be preferable to generative models, but the combination of the two tends to lead to the best results. Indeed, for some hate categories such as origin, religion, and disability, hate speech classification using augmented data for training improves by more than 10% F1 over the no augmentation baseline. This work contributes to the development of systems for hate speech detection that are not only better performing but also fairer and more inclusive towards targets that have been neglected so far.
Variationist: Exploring Multifaceted Variation and Bias in Written Language Data
Jun 25, 2024



Exploring and understanding language data is a fundamental stage in all areas dealing with human language. It allows NLP practitioners to uncover quality concerns and harmful biases in data before training, and helps linguists and social scientists to gain insight into language use and human behavior. Yet, there is currently a lack of a unified, customizable tool to seamlessly inspect and visualize language variation and bias across multiple variables, language units, and diverse metrics that go beyond descriptive statistics. In this paper, we introduce Variationist, a highly-modular, extensible, and task-agnostic tool that fills this gap. Variationist handles at once a potentially unlimited combination of variable types and semantics across diversity and association metrics with regards to the language unit of choice, and orchestrates the creation of up to five-dimensional interactive charts for over 30 variable type-semantics combinations. Through our case studies on computational dialectology, human label variation, and text generation, we show how Variationist enables researchers from different disciplines to effortlessly answer specific research questions or unveil undesired associations in language data. A Python library, code, documentation, and tutorials are made publicly available to the research community.