 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Target-Aware Analysis of Data Augmentation for Hate Speech Detection
Paper and Code
Oct 10, 2024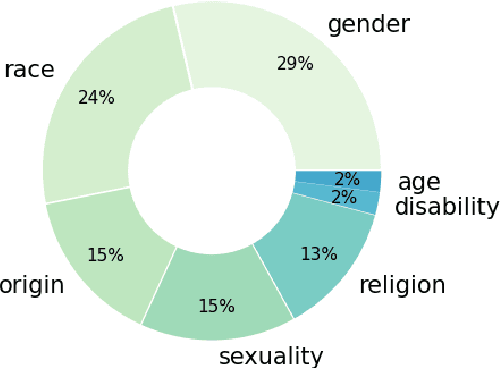

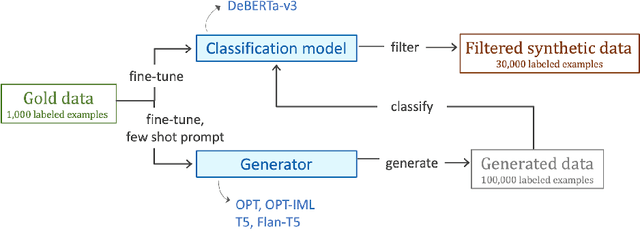

Hate speech is one of the main threats posed by the widespread use of social networks, despite efforts to limit it. Although attention has been devoted to this issue, the lack of datasets and case studies centered around scarcely represented phenomena, such as ableism or ageism, can lead to hate speech detection systems that do not perform well on underrepresented identity groups. Given the unpreceded capabilities of LLMs in producing high-quality data, we investigate the possibility of augmenting existing data with generative language models, reducing target imbalance. We experiment with augmenting 1,000 posts from the Measuring Hate Speech corpus, an English dataset annotated with target identity information, adding around 30,000 synthetic examples using both simple data augmentation methods and different types of generative models, comparing autoregressive and sequence-to-sequence approaches. We find traditional DA methods to often be preferable to generative models, but the combination of the two tends to lead to the best results. Indeed, for some hate categories such as origin, religion, and disability, hate speech classification using augmented data for training improves by more than 10% F1 over the no augmentation baseline. This work contributes to the development of systems for hate speech detection that are not only better performing but also fairer and more inclusive towards targets that have been neglected so far.