 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOverview of the TREC 2024 NeuCLIR Track
Sep 17, 2025The principal goal of the TREC Neural Cross-Language Information Retrieval (NeuCLIR) track is to study the effect of neural approaches on cross-language information access. The track has created test collections containing Chinese, Persian, and Russian news stories and Chinese academic abstracts. NeuCLIR includes four task types: Cross-Language Information Retrieval (CLIR) from news, Multilingual Information Retrieval (MLIR) from news, Report Generation from news, and CLIR from technical documents. A total of 274 runs were submitted by five participating teams (and as baselines by the track coordinators) for eight tasks across these four task types. Task descriptions and the available results are presented.
An Interdisciplinary Approach to Human-Centered Machine Translation
Jun 16, 2025Machine Translation (MT) tools are widely used today, often in contexts where professional translators are not present. Despite progress in MT technology, a gap persists between system development and real-world usage, particularly for non-expert users who may struggle to assess translation reliability. This paper advocates for a human-centered approach to MT, emphasizing the alignment of system design with diverse communicative goals and contexts of use. We survey the literature in Translation Studies and Human-Computer Interaction to recontextualize MT evaluation and design to address the diverse real-world scenarios in which MT is used today.
MURR: Model Updating with Regularized Replay for Searching a Document Stream
Apr 14, 2025The Internet produces a continuous stream of new documents and user-generated queries. These naturally change over time based on events in the world and the evolution of language. Neural retrieval models that were trained once on a fixed set of query-document pairs will quickly start misrepresenting newly-created content and queries, leading to less effective retrieval. Traditional statistical sparse retrieval can update collection statistics to reflect these changes in the use of language in documents and queries. In contrast, continued fine-tuning of the language model underlying neural retrieval approaches such as DPR and ColBERT creates incompatibility with previously-encoded documents. Re-encoding and re-indexing all previously-processed documents can be costly. In this work, we explore updating a neural dual encoder retrieval model without reprocessing past documents in the stream. We propose MURR, a model updating strategy with regularized replay, to ensure the model can still faithfully search existing documents without reprocessing, while continuing to update the model for the latest topics. In our simulated streaming environments, we show that fine-tuning models using MURR leads to more effective and more consistent retrieval results than other strategies as the stream of documents and queries progresses.
PLAID SHIRTTT for Large-Scale Streaming Dense Retrieval
May 02, 2024



PLAID, an efficient implementation of the ColBERT late interaction bi-encoder using pretrained language models for ranking, consistently achieves state-of-the-art performance in monolingual, cross-language, and multilingual retrieval. PLAID differs from ColBERT by assigning terms to clusters and representing those terms as cluster centroids plus compressed residual vectors. While PLAID is effective in batch experiments, its performance degrades in streaming settings where documents arrive over time because representations of new tokens may be poorly modeled by the earlier tokens used to select cluster centroids. PLAID Streaming Hierarchical Indexing that Runs on Terabytes of Temporal Text (PLAID SHIRTTT) addresses this concern using multi-phase incremental indexing based on hierarchical sharding. Experiments on ClueWeb09 and the multilingual NeuCLIR collection demonstrate the effectiveness of this approach both for the largest collection indexed to date by the ColBERT architecture and in the multilingual setting, respectively.
On the Evaluation of Machine-Generated Reports
May 02, 2024



Large Language Models (LLMs) have enabled new ways to satisfy information needs. Although great strides have been made in applying them to settings like document ranking and short-form text generation, they still struggle to compose complete, accurate, and verifiable long-form reports. Reports with these qualities are necessary to satisfy the complex, nuanced, or multi-faceted information needs of users. In this perspective paper, we draw together opinions from industry and academia, and from a variety of related research areas, to present our vision for automatic report generation, and -- critically -- a flexible framework by which such reports can be evaluated. In contrast with other summarization tasks, automatic report generation starts with a detailed description of an information need, stating the necessary background, requirements, and scope of the report. Further, the generated reports should be complete, accurate, and verifiable. These qualities, which are desirable -- if not required -- in many analytic report-writing settings, require rethinking how to build and evaluate systems that exhibit these qualities. To foster new efforts in building these systems, we present an evaluation framework that draws on ideas found in various evaluations. To test completeness and accuracy, the framework uses nuggets of information, expressed as questions and answers, that need to be part of any high-quality generated report. Additionally, evaluation of citations that map claims made in the report to their source documents ensures verifiability.
Efficiency-Effectiveness Tradeoff of Probabilistic Structured Queries for Cross-Language Information Retrieval
Apr 29, 2024



Probabilistic Structured Queries (PSQ) is a cross-language information retrieval (CLIR) method that uses translation probabilities statistically derived from aligned corpora. PSQ is a strong baseline for efficient CLIR using sparse indexing. It is, therefore, useful as the first stage in a cascaded neural CLIR system whose second stage is more effective but too inefficient to be used on its own to search a large text collection. In this reproducibility study, we revisit PSQ by introducing an efficient Python implementation. Unconstrained use of all translation probabilities that can be estimated from aligned parallel text would in the limit assign a weight to every vocabulary term, precluding use of an inverted index to serve queries efficiently. Thus, PSQ's effectiveness and efficiency both depend on how translation probabilities are pruned. This paper presents experiments over a range of modern CLIR test collections to demonstrate that achieving Pareto optimal PSQ effectiveness-efficiency tradeoffs benefits from multi-criteria pruning, which has not been fully explored in prior work. Our Python PSQ implementation is available on GitHub(https://github.com/hltcoe/PSQ) and unpruned translation tables are available on Huggingface Models(https://huggingface.co/hltcoe/psq_translation_tables).
Overview of the TREC 2023 NeuCLIR Track
Apr 11, 2024
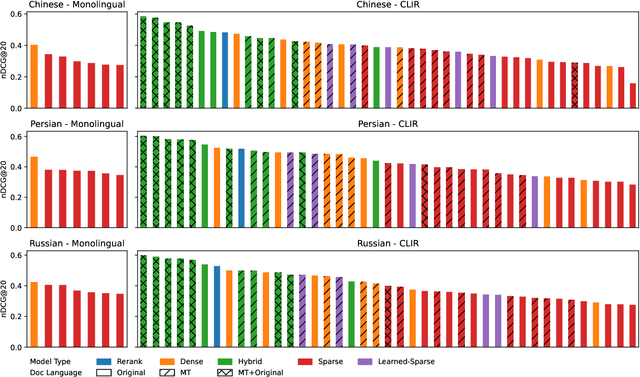
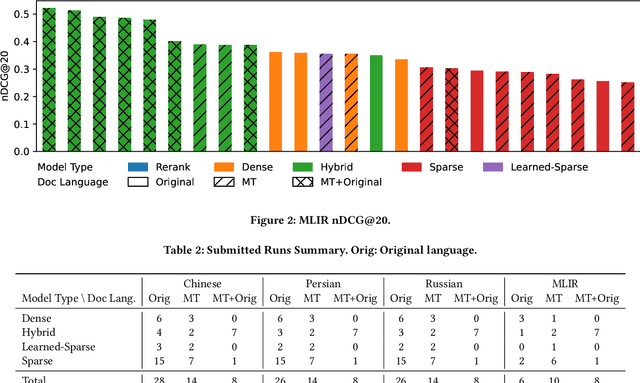
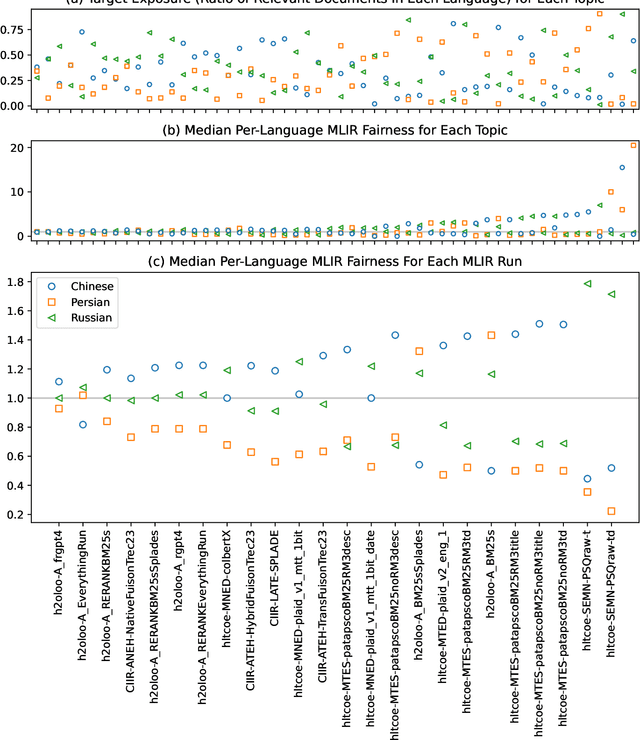
The principal goal of the TREC Neural Cross-Language Information Retrieval (NeuCLIR) track is to study the impact of neural approaches to cross-language information retrieval. The track has created four collections, large collections of Chinese, Persian, and Russian newswire and a smaller collection of Chinese scientific abstracts. The principal tasks are ranked retrieval of news in one of the three languages, using English topics. Results for a multilingual task, also with English topics but with documents from all three newswire collections, are also reported. New in this second year of the track is a pilot technical documents CLIR task for ranked retrieval of Chinese technical documents using English topics. A total of 220 runs across all tasks were submitted by six participating teams and, as baselines, by track coordinators. Task descriptions and results are presented.
Translate-Distill: Learning Cross-Language Dense Retrieval by Translation and Distillation
Jan 09, 2024



Prior work on English monolingual retrieval has shown that a cross-encoder trained using a large number of relevance judgments for query-document pairs can be used as a teacher to train more efficient, but similarly effective, dual-encoder student models. Applying a similar knowledge distillation approach to training an efficient dual-encoder model for Cross-Language Information Retrieval (CLIR), where queries and documents are in different languages, is challenging due to the lack of a sufficiently large training collection when the query and document languages differ. The state of the art for CLIR thus relies on translating queries, documents, or both from the large English MS MARCO training set, an approach called Translate-Train. This paper proposes an alternative, Translate-Distill, in which knowledge distillation from either a monolingual cross-encoder or a CLIR cross-encoder is used to train a dual-encoder CLIR student model. This richer design space enables the teacher model to perform inference in an optimized setting, while training the student model directly for CLIR. Trained models and artifacts are publicly available on Huggingface.
Known by the Company it Keeps: Proximity-Based Indexing for Physical Content in Archival Repositories
Jun 10, 2023

Despite the plethora of born-digital content, vast troves of important content remain accessible only on physical media such as paper or microfilm. The traditional approach to indexing undigitized content is using manually created metadata that describes content at some level of aggregation (e.g., folder, box, or collection). Searchers led in this way to some subset of the content often must then manually examine substantial quantities of physical media to find what they are looking for. This paper proposes a complementary approach, in which selective digitization of a small portion of the content is used as a basis for proximity-based indexing as a way of bringing the user closer to the specific content for which they are looking. Experiments with 35 boxes of partially digitized US State Department records indicate that box-level indexes built in this way can provide a useful basis for search.
Overview of the TREC 2022 NeuCLIR Track
Apr 24, 2023
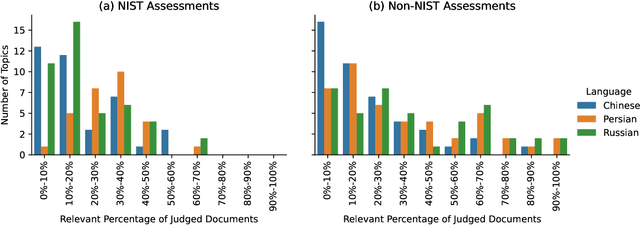
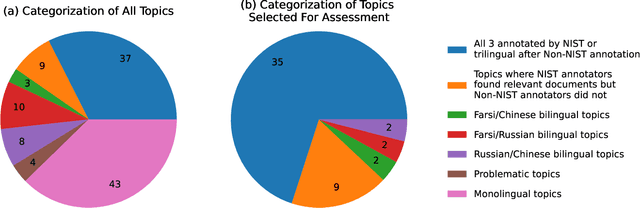
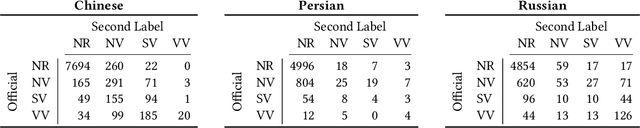
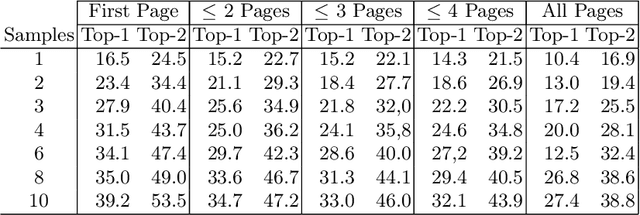
This is the first year of the TREC Neural CLIR (NeuCLIR) track, which aims to study the impact of neural approaches to cross-language information retrieval. The main task in this year's track was ad hoc ranked retrieval of Chinese, Persian, or Russian newswire documents using queries expressed in English. Topics were developed using standard TREC processes, except that topics developed by an annotator for one language were assessed by a different annotator when evaluating that topic on a different language. There were 172 total runs submitted by twelve teams.