 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFACTUM: Mechanistic Detection of Citation Hallucination in Long-Form RAG
Jan 09, 2026Retrieval-Augmented Generation (RAG) models are critically undermined by citation hallucinations, a deceptive failure where a model confidently cites a source that fails to support its claim. Existing work often attributes hallucination to a simple over-reliance on the model's parametric knowledge. We challenge this view and introduce FACTUM (Framework for Attesting Citation Trustworthiness via Underlying Mechanisms), a framework of four mechanistic scores measuring the distinct contributions of a model's attention and FFN pathways, and the alignment between them. Our analysis reveals two consistent signatures of correct citation: a significantly stronger contribution from the model's parametric knowledge and greater use of the attention sink for information synthesis. Crucially, we find the signature of a correct citation is not static but evolves with model scale. For example, the signature of a correct citation for the Llama-3.2-3B model is marked by higher pathway alignment, whereas for the Llama-3.1-8B model, it is characterized by lower alignment, where pathways contribute more distinct, orthogonal information. By capturing this complex, evolving signature, FACTUM outperforms state-of-the-art baselines by up to 37.5% in AUC. Our findings reframe citation hallucination as a complex, scale-dependent interplay between internal mechanisms, paving the way for more nuanced and reliable RAG systems.
StressRoBERTa: Cross-Condition Transfer Learning from Depression, Anxiety, and PTSD to Stress Detection
Dec 29, 2025The prevalence of chronic stress represents a significant public health concern, with social media platforms like Twitter serving as important venues for individuals to share their experiences. This paper introduces StressRoBERTa, a cross-condition transfer learning approach for automatic detection of self-reported chronic stress in English tweets. The investigation examines whether continual training on clinically related conditions (depression, anxiety, PTSD), disorders with high comorbidity with chronic stress, improves stress detection compared to general language models and broad mental health models. RoBERTa is continually trained on the Stress-SMHD corpus (108M words from users with self-reported diagnoses of depression, anxiety, and PTSD) and fine-tuned on the SMM4H 2022 Task 8 dataset. StressRoBERTa achieves 82% F1-score, outperforming the best shared task system (79% F1) by 3 percentage points. The results demonstrate that focused cross-condition transfer from stress-related disorders (+1% F1 over vanilla RoBERTa) provides stronger representations than general mental health training. Evaluation on Dreaddit (81% F1) further demonstrates transfer from clinical mental health contexts to situational stress discussions.
MMMORRF: Multimodal Multilingual Modularized Reciprocal Rank Fusion
Mar 26, 2025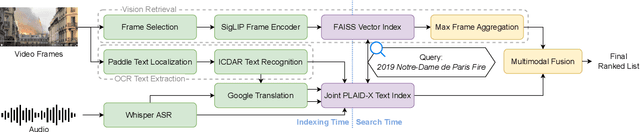


Videos inherently contain multiple modalities, including visual events, text overlays, sounds, and speech, all of which are important for retrieval. However, state-of-the-art multimodal language models like VAST and LanguageBind are built on vision-language models (VLMs), and thus overly prioritize visual signals. Retrieval benchmarks further reinforce this bias by focusing on visual queries and neglecting other modalities. We create a search system MMMORRF that extracts text and features from both visual and audio modalities and integrates them with a novel modality-aware weighted reciprocal rank fusion. MMMORRF is both effective and efficient, demonstrating practicality in searching videos based on users' information needs instead of visual descriptive queries. We evaluate MMMORRF on MultiVENT 2.0 and TVR, two multimodal benchmarks designed for more targeted information needs, and find that it improves nDCG@20 by 81% over leading multimodal encoders and 37% over single-modality retrieval, demonstrating the value of integrating diverse modalities.
On the Evaluation of Machine-Generated Reports
May 02, 2024



Large Language Models (LLMs) have enabled new ways to satisfy information needs. Although great strides have been made in applying them to settings like document ranking and short-form text generation, they still struggle to compose complete, accurate, and verifiable long-form reports. Reports with these qualities are necessary to satisfy the complex, nuanced, or multi-faceted information needs of users. In this perspective paper, we draw together opinions from industry and academia, and from a variety of related research areas, to present our vision for automatic report generation, and -- critically -- a flexible framework by which such reports can be evaluated. In contrast with other summarization tasks, automatic report generation starts with a detailed description of an information need, stating the necessary background, requirements, and scope of the report. Further, the generated reports should be complete, accurate, and verifiable. These qualities, which are desirable -- if not required -- in many analytic report-writing settings, require rethinking how to build and evaluate systems that exhibit these qualities. To foster new efforts in building these systems, we present an evaluation framework that draws on ideas found in various evaluations. To test completeness and accuracy, the framework uses nuggets of information, expressed as questions and answers, that need to be part of any high-quality generated report. Additionally, evaluation of citations that map claims made in the report to their source documents ensures verifiability.
PLAID SHIRTTT for Large-Scale Streaming Dense Retrieval
May 02, 2024



PLAID, an efficient implementation of the ColBERT late interaction bi-encoder using pretrained language models for ranking, consistently achieves state-of-the-art performance in monolingual, cross-language, and multilingual retrieval. PLAID differs from ColBERT by assigning terms to clusters and representing those terms as cluster centroids plus compressed residual vectors. While PLAID is effective in batch experiments, its performance degrades in streaming settings where documents arrive over time because representations of new tokens may be poorly modeled by the earlier tokens used to select cluster centroids. PLAID Streaming Hierarchical Indexing that Runs on Terabytes of Temporal Text (PLAID SHIRTTT) addresses this concern using multi-phase incremental indexing based on hierarchical sharding. Experiments on ClueWeb09 and the multilingual NeuCLIR collection demonstrate the effectiveness of this approach both for the largest collection indexed to date by the ColBERT architecture and in the multilingual setting, respectively.