 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMMORRF: Multimodal Multilingual Modularized Reciprocal Rank Fusion
Mar 26, 2025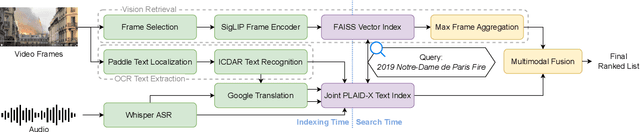


Videos inherently contain multiple modalities, including visual events, text overlays, sounds, and speech, all of which are important for retrieval. However, state-of-the-art multimodal language models like VAST and LanguageBind are built on vision-language models (VLMs), and thus overly prioritize visual signals. Retrieval benchmarks further reinforce this bias by focusing on visual queries and neglecting other modalities. We create a search system MMMORRF that extracts text and features from both visual and audio modalities and integrates them with a novel modality-aware weighted reciprocal rank fusion. MMMORRF is both effective and efficient, demonstrating practicality in searching videos based on users' information needs instead of visual descriptive queries. We evaluate MMMORRF on MultiVENT 2.0 and TVR, two multimodal benchmarks designed for more targeted information needs, and find that it improves nDCG@20 by 81% over leading multimodal encoders and 37% over single-modality retrieval, demonstrating the value of integrating diverse modalities.