 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMMORRF: Multimodal Multilingual Modularized Reciprocal Rank Fusion
Mar 26, 2025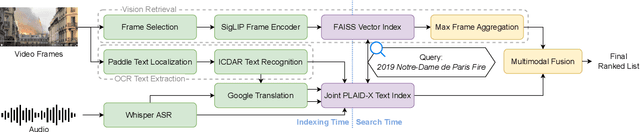


Videos inherently contain multiple modalities, including visual events, text overlays, sounds, and speech, all of which are important for retrieval. However, state-of-the-art multimodal language models like VAST and LanguageBind are built on vision-language models (VLMs), and thus overly prioritize visual signals. Retrieval benchmarks further reinforce this bias by focusing on visual queries and neglecting other modalities. We create a search system MMMORRF that extracts text and features from both visual and audio modalities and integrates them with a novel modality-aware weighted reciprocal rank fusion. MMMORRF is both effective and efficient, demonstrating practicality in searching videos based on users' information needs instead of visual descriptive queries. We evaluate MMMORRF on MultiVENT 2.0 and TVR, two multimodal benchmarks designed for more targeted information needs, and find that it improves nDCG@20 by 81% over leading multimodal encoders and 37% over single-modality retrieval, demonstrating the value of integrating diverse modalities.
MultiVENT 2.0: A Massive Multilingual Benchmark for Event-Centric Video Retrieval
Oct 15, 2024Efficiently retrieving and synthesizing information from large-scale multimodal collections has become a critical challenge. However, existing video retrieval datasets suffer from scope limitations, primarily focusing on matching descriptive but vague queries with small collections of professionally edited, English-centric videos. To address this gap, we introduce $\textbf{MultiVENT 2.0}$, a large-scale, multilingual event-centric video retrieval benchmark featuring a collection of more than 218,000 news videos and 3,906 queries targeting specific world events. These queries specifically target information found in the visual content, audio, embedded text, and text metadata of the videos, requiring systems leverage all these sources to succeed at the task. Preliminary results show that state-of-the-art vision-language models struggle significantly with this task, and while alternative approaches show promise, they are still insufficient to adequately address this problem. These findings underscore the need for more robust multimodal retrieval systems, as effective video retrieval is a crucial step towards multimodal content understanding and generation tasks.
Why Did the Chicken Cross the Road? Rephrasing and Analyzing Ambiguous Questions in VQA
Nov 14, 2022Resolving ambiguities in questions is key to successfully answering them. Focusing on questions about images, we create a dataset of ambiguous examples; we annotate these examples, grouping the answers by the underlying question they address and rephrasing the question for each group to reduce ambiguity. An analysis of our data reveals a linguistically-aligned ontology of reasons for ambiguity in visual questions. We then develop an English question-generation model which we demonstrate via automatic and human evaluation produces less ambiguous questions. We further show that the question generation objective we use allows the model to integrate answer group information without any direct supervision.