 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified Multimodal Uncertain Inference
Apr 13, 2026We introduce Unified Multimodal Uncertain Inference (UMUI), a multimodal inference task spanning text, audio, and video, where models must produce calibrated probability estimates of hypotheses conditioned on a premise in any modality or combination. While uncertain inference has been explored in text, extension to other modalities has been limited to single-modality binary entailment judgments, leaving no framework for fine-grained probabilistic reasoning in or across other modalities. To address this, we curate a human-annotated evaluation set with scalar probability judgments across audio, visual, and audiovisual settings, and additionally evaluate on existing text and audio benchmarks. We introduce CLUE (Calibrated Latent Uncertainty Estimation), which combines self-consistent teacher calibration and distribution-based confidence probing to produce calibrated predictions. We demonstrate that our 3B-parameter model achieves equivalent or stronger performance than baselines up to 32B parameters across all modalities.
A Brief Comparison of Training-Free Multi-Vector Sequence Compression Methods
Mar 23, 2026While multi-vector retrieval models outperform single-vector models of comparable size in retrieval quality, their practicality is limited by substantially larger index sizes, driven by the additional sequence-length dimension in their document embeddings. Because document embedding size dictates both memory overhead and query latency, compression is essential for deployment. In this work, we present an evaluation of training-free methods targeting the token sequence length, a dimension unique to multi-vector retrieval. Our findings suggest that token merging is strictly superior to token pruning for reducing index size while maintaining retrieval effectiveness.
Multi-Vector Index Compression in Any Modality
Feb 24, 2026We study efficient multi-vector retrieval for late interaction in any modality. Late interaction has emerged as a dominant paradigm for information retrieval in text, images, visual documents, and videos, but its computation and storage costs grow linearly with document length, making it costly for image-, video-, and audio-rich corpora. To address this limitation, we explore query-agnostic methods for compressing multi-vector document representations under a constant vector budget. We introduce four approaches for index compression: sequence resizing, memory tokens, hierarchical pooling, and a novel attention-guided clustering (AGC). AGC uses an attention-guided mechanism to identify the most semantically salient regions of a document as cluster centroids and to weight token aggregation. Evaluating these methods on retrieval tasks spanning text (BEIR), visual-document (ViDoRe), and video (MSR-VTT, MultiVENT 2.0), we show that attention-guided clustering consistently outperforms other parameterized compression methods (sequence resizing and memory tokens), provides greater flexibility in index size than non-parametric hierarchical clustering, and achieves competitive or improved performance compared to a full, uncompressed index. The source code is available at: github.com/hanxiangqin/omni-col-press.
RANKVIDEO: Reasoning Reranking for Text-to-Video Retrieval
Feb 03, 2026Reranking is a critical component of modern retrieval systems, which typically pair an efficient first-stage retriever with a more expressive model to refine results. While large reasoning models have driven rapid progress in text-centric reranking, reasoning-based reranking for video retrieval remains underexplored. To address this gap, we introduce RANKVIDEO, a reasoning-based reranker for video retrieval that explicitly reasons over query-video pairs using video content to assess relevance. RANKVIDEO is trained using a two-stage curriculum consisting of perception-grounded supervised fine-tuning followed by reranking training that combines pointwise, pairwise, and teacher confidence distillation objectives, and is supported by a data synthesis pipeline for constructing reasoning-intensive query-video pairs. Experiments on the large-scale MultiVENT 2.0 benchmark demonstrate that RANKVIDEO consistently improves retrieval performance within a two-stage framework, yielding an average improvement of 31% on nDCG@10 and outperforming text-only and vision-language reranking alternatives, while more efficient.
HLTCOE Evaluation Team at TREC 2025: VQA Track
Dec 08, 2025The HLTCOE Evaluation team participated in TREC VQA's Answer Generation (AG) task, for which we developed a listwise learning framework that aims to improve semantic precision and ranking consistency in answer generation. Given a video-question pair, a base multimodal model first generates multiple candidate answers, which are then reranked using a model trained with a novel Masked Pointer Cross-Entropy Loss with Rank Weights. This objective integrates pointer-based candidate selection, rank-dependent weighting, and masked cross-entropy under vocabulary restriction, enabling stable and interpretable listwise optimization. By bridging generative modeling with discriminative ranking, our method produces coherent, fine-grained answer lists. Experiments reveal consistent gains in accuracy and ranking stability, especially for questions requiring temporal reasoning and semantic disambiguation.
WikiVideo: Article Generation from Multiple Videos
Apr 01, 2025We present the challenging task of automatically creating a high-level Wikipedia-style article that aggregates information from multiple diverse videos about real-world events, such as natural disasters or political elections. Videos are intuitive sources for retrieval-augmented generation (RAG), but most contemporary RAG workflows focus heavily on text and existing methods for video-based summarization focus on low-level scene understanding rather than high-level event semantics. To close this gap, we introduce WikiVideo, a benchmark consisting of expert-written articles and densely annotated videos that provide evidence for articles' claims, facilitating the integration of video into RAG pipelines and enabling the creation of in-depth content that is grounded in multimodal sources. We further propose Collaborative Article Generation (CAG), a novel interactive method for article creation from multiple videos. CAG leverages an iterative interaction between an r1-style reasoning model and a VideoLLM to draw higher level inferences about the target event than is possible with VideoLLMs alone, which fixate on low-level visual features. We benchmark state-of-the-art VideoLLMs and CAG in both oracle retrieval and RAG settings and find that CAG consistently outperforms alternative methods, while suggesting intriguing avenues for future work.
MMMORRF: Multimodal Multilingual Modularized Reciprocal Rank Fusion
Mar 26, 2025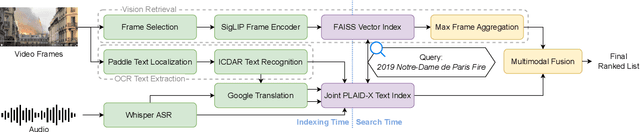


Videos inherently contain multiple modalities, including visual events, text overlays, sounds, and speech, all of which are important for retrieval. However, state-of-the-art multimodal language models like VAST and LanguageBind are built on vision-language models (VLMs), and thus overly prioritize visual signals. Retrieval benchmarks further reinforce this bias by focusing on visual queries and neglecting other modalities. We create a search system MMMORRF that extracts text and features from both visual and audio modalities and integrates them with a novel modality-aware weighted reciprocal rank fusion. MMMORRF is both effective and efficient, demonstrating practicality in searching videos based on users' information needs instead of visual descriptive queries. We evaluate MMMORRF on MultiVENT 2.0 and TVR, two multimodal benchmarks designed for more targeted information needs, and find that it improves nDCG@20 by 81% over leading multimodal encoders and 37% over single-modality retrieval, demonstrating the value of integrating diverse modalities.
Video-ColBERT: Contextualized Late Interaction for Text-to-Video Retrieval
Mar 24, 2025In this work, we tackle the problem of text-to-video retrieval (T2VR). Inspired by the success of late interaction techniques in text-document, text-image, and text-video retrieval, our approach, Video-ColBERT, introduces a simple and efficient mechanism for fine-grained similarity assessment between queries and videos. Video-ColBERT is built upon 3 main components: a fine-grained spatial and temporal token-wise interaction, query and visual expansions, and a dual sigmoid loss during training. We find that this interaction and training paradigm leads to strong individual, yet compatible, representations for encoding video content. These representations lead to increases in performance on common text-to-video retrieval benchmarks compared to other bi-encoder methods.
MultiVENT 2.0: A Massive Multilingual Benchmark for Event-Centric Video Retrieval
Oct 15, 2024Efficiently retrieving and synthesizing information from large-scale multimodal collections has become a critical challenge. However, existing video retrieval datasets suffer from scope limitations, primarily focusing on matching descriptive but vague queries with small collections of professionally edited, English-centric videos. To address this gap, we introduce $\textbf{MultiVENT 2.0}$, a large-scale, multilingual event-centric video retrieval benchmark featuring a collection of more than 218,000 news videos and 3,906 queries targeting specific world events. These queries specifically target information found in the visual content, audio, embedded text, and text metadata of the videos, requiring systems leverage all these sources to succeed at the task. Preliminary results show that state-of-the-art vision-language models struggle significantly with this task, and while alternative approaches show promise, they are still insufficient to adequately address this problem. These findings underscore the need for more robust multimodal retrieval systems, as effective video retrieval is a crucial step towards multimodal content understanding and generation tasks.
Grounding Partially-Defined Events in Multimodal Data
Oct 07, 2024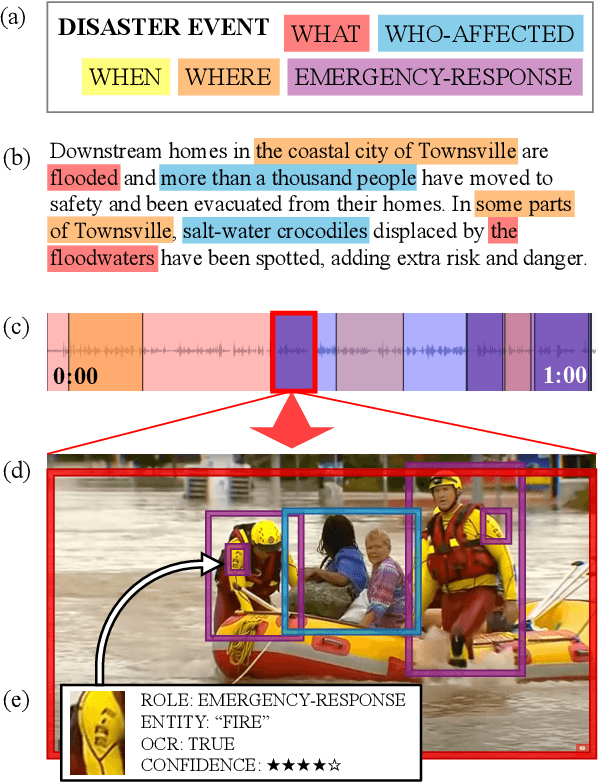

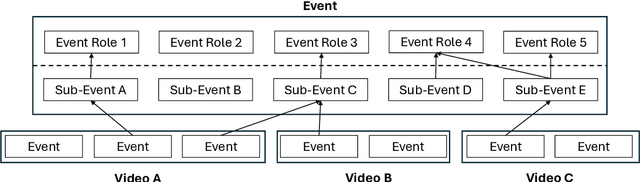
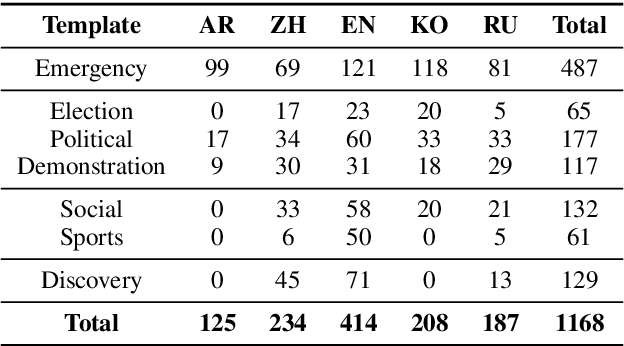
How are we able to learn about complex current events just from short snippets of video? While natural language enables straightforward ways to represent under-specified, partially observable events, visual data does not facilitate analogous methods and, consequently, introduces unique challenges in event understanding. With the growing prevalence of vision-capable AI agents, these systems must be able to model events from collections of unstructured video data. To tackle robust event modeling in multimodal settings, we introduce a multimodal formulation for partially-defined events and cast the extraction of these events as a three-stage span retrieval task. We propose a corresponding benchmark for this task, MultiVENT-G, that consists of 14.5 hours of densely annotated current event videos and 1,168 text documents, containing 22.8K labeled event-centric entities. We propose a collection of LLM-driven approaches to the task of multimodal event analysis, and evaluate them on MultiVENT-G. Results illustrate the challenges that abstract event understanding poses and demonstrates promise in event-centric video-language systems.