 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Event Individuation for Document-Level Information Extraction
Paper and Code
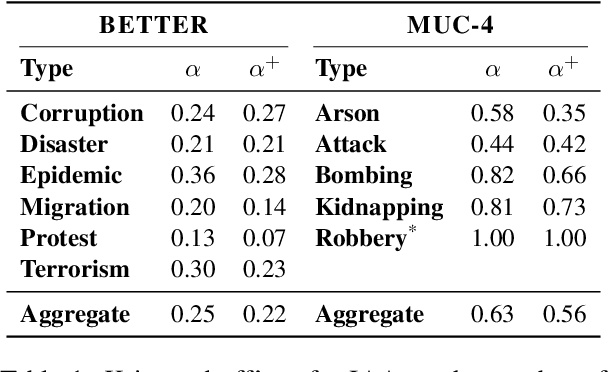

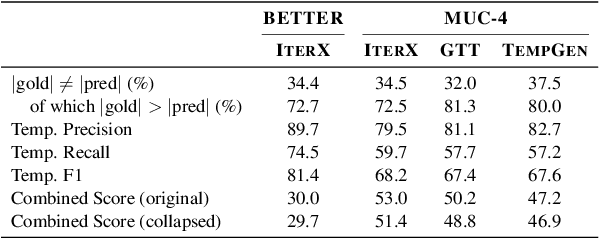
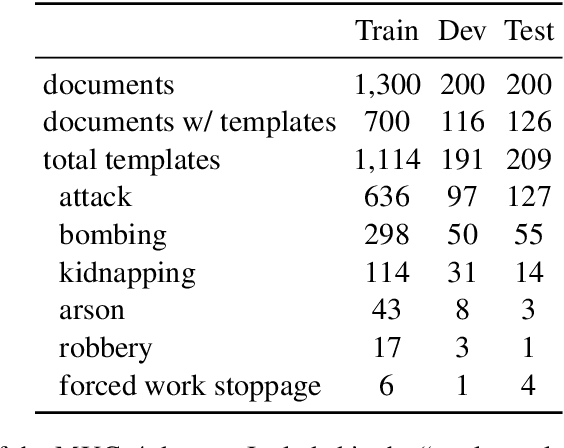
As information extraction (IE) systems have grown more capable at whole-document extraction, the classic task of \emph{template filling} has seen renewed interest as a benchmark for evaluating them. In this position paper, we call into question the suitability of template filling for this purpose. We argue that the task demands definitive answers to thorny questions of \emph{event individuation} -- the problem of distinguishing distinct events -- about which even human experts disagree. We show through annotation studies and error analysis that this raises concerns about the usefulness of template filling evaluation metrics, the quality of datasets for the task, and the ability of models to learn it. Finally, we consider possible solutions.