 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReferring Change Detection in Remote Sensing Imagery
Dec 12, 2025Change detection in remote sensing imagery is essential for applications such as urban planning, environmental monitoring, and disaster management. Traditional change detection methods typically identify all changes between two temporal images without distinguishing the types of transitions, which can lead to results that may not align with specific user needs. Although semantic change detection methods have attempted to address this by categorizing changes into predefined classes, these methods rely on rigid class definitions and fixed model architectures, making it difficult to mix datasets with different label sets or reuse models across tasks, as the output channels are tightly coupled with the number and type of semantic classes. To overcome these limitations, we introduce Referring Change Detection (RCD), which leverages natural language prompts to detect specific classes of changes in remote sensing images. By integrating language understanding with visual analysis, our approach allows users to specify the exact type of change they are interested in. However, training models for RCD is challenging due to the limited availability of annotated data and severe class imbalance in existing datasets. To address this, we propose a two-stage framework consisting of (I) \textbf{RCDNet}, a cross-modal fusion network designed for referring change detection, and (II) \textbf{RCDGen}, a diffusion-based synthetic data generation pipeline that produces realistic post-change images and change maps for a specified category using only pre-change image, without relying on semantic segmentation masks and thereby significantly lowering the barrier to scalable data creation. Experiments across multiple datasets show that our framework enables scalable and targeted change detection. Project website is here: https://yilmazkorkmaz1.github.io/RCD.
Shuffle PatchMix Augmentation with Confidence-Margin Weighted Pseudo-Labels for Enhanced Source-Free Domain Adaptation
May 30, 2025This work investigates Source-Free Domain Adaptation (SFDA), where a model adapts to a target domain without access to source data. A new augmentation technique, Shuffle PatchMix (SPM), and a novel reweighting strategy are introduced to enhance performance. SPM shuffles and blends image patches to generate diverse and challenging augmentations, while the reweighting strategy prioritizes reliable pseudo-labels to mitigate label noise. These techniques are particularly effective on smaller datasets like PACS, where overfitting and pseudo-label noise pose greater risks. State-of-the-art results are achieved on three major benchmarks: PACS, VisDA-C, and DomainNet-126. Notably, on PACS, improvements of 7.3% (79.4% to 86.7%) and 7.2% are observed in single-target and multi-target settings, respectively, while gains of 2.8% and 0.7% are attained on DomainNet-126 and VisDA-C. This combination of advanced augmentation and robust pseudo-label reweighting establishes a new benchmark for SFDA. The code is available at: https://github.com/PrasannaPulakurthi/SPM
Effective Dual-Region Augmentation for Reduced Reliance on Large Amounts of Labeled Data
Apr 17, 2025This paper introduces a novel dual-region augmentation approach designed to reduce reliance on large-scale labeled datasets while improving model robustness and adaptability across diverse computer vision tasks, including source-free domain adaptation (SFDA) and person re-identification (ReID). Our method performs targeted data transformations by applying random noise perturbations to foreground objects and spatially shuffling background patches. This effectively increases the diversity of the training data, improving model robustness and generalization. Evaluations on the PACS dataset for SFDA demonstrate that our augmentation strategy consistently outperforms existing methods, achieving significant accuracy improvements in both single-target and multi-target adaptation settings. By augmenting training data through structured transformations, our method enables model generalization across domains, providing a scalable solution for reducing reliance on manually annotated datasets. Furthermore, experiments on Market-1501 and DukeMTMC-reID datasets validate the effectiveness of our approach for person ReID, surpassing traditional augmentation techniques.
Video-ColBERT: Contextualized Late Interaction for Text-to-Video Retrieval
Mar 24, 2025In this work, we tackle the problem of text-to-video retrieval (T2VR). Inspired by the success of late interaction techniques in text-document, text-image, and text-video retrieval, our approach, Video-ColBERT, introduces a simple and efficient mechanism for fine-grained similarity assessment between queries and videos. Video-ColBERT is built upon 3 main components: a fine-grained spatial and temporal token-wise interaction, query and visual expansions, and a dual sigmoid loss during training. We find that this interaction and training paradigm leads to strong individual, yet compatible, representations for encoding video content. These representations lead to increases in performance on common text-to-video retrieval benchmarks compared to other bi-encoder methods.
Entropic Open-set Active Learning
Dec 21, 2023Active Learning (AL) aims to enhance the performance of deep models by selecting the most informative samples for annotation from a pool of unlabeled data. Despite impressive performance in closed-set settings, most AL methods fail in real-world scenarios where the unlabeled data contains unknown categories. Recently, a few studies have attempted to tackle the AL problem for the open-set setting. However, these methods focus more on selecting known samples and do not efficiently utilize unknown samples obtained during AL rounds. In this work, we propose an Entropic Open-set AL (EOAL) framework which leverages both known and unknown distributions effectively to select informative samples during AL rounds. Specifically, our approach employs two different entropy scores. One measures the uncertainty of a sample with respect to the known-class distributions. The other measures the uncertainty of the sample with respect to the unknown-class distributions. By utilizing these two entropy scores we effectively separate the known and unknown samples from the unlabeled data resulting in better sampling. Through extensive experiments, we show that the proposed method outperforms existing state-of-the-art methods on CIFAR-10, CIFAR-100, and TinyImageNet datasets. Code is available at \url{https://github.com/bardisafa/EOAL}.
Unsupervised Video Domain Adaptation with Masked Pre-Training and Collaborative Self-Training
Dec 06, 2023



In this work, we tackle the problem of unsupervised domain adaptation (UDA) for video action recognition. Our approach, which we call UNITE, uses an image teacher model to adapt a video student model to the target domain. UNITE first employs self-supervised pre-training to promote discriminative feature learning on target domain videos using a teacher-guided masked distillation objective. We then perform self-training on masked target data, using the video student model and image teacher model together to generate improved pseudolabels for unlabeled target videos. Our self-training process successfully leverages the strengths of both models to achieve strong transfer performance across domains. We evaluate our approach on multiple video domain adaptation benchmarks and observe significant improvements upon previously reported results.
STMT: A Spatial-Temporal Mesh Transformer for MoCap-Based Action Recognition
Mar 31, 2023



We study the problem of human action recognition using motion capture (MoCap) sequences. Unlike existing techniques that take multiple manual steps to derive standardized skeleton representations as model input, we propose a novel Spatial-Temporal Mesh Transformer (STMT) to directly model the mesh sequences. The model uses a hierarchical transformer with intra-frame off-set attention and inter-frame self-attention. The attention mechanism allows the model to freely attend between any two vertex patches to learn non-local relationships in the spatial-temporal domain. Masked vertex modeling and future frame prediction are used as two self-supervised tasks to fully activate the bi-directional and auto-regressive attention in our hierarchical transformer. The proposed method achieves state-of-the-art performance compared to skeleton-based and point-cloud-based models on common MoCap benchmarks. Code is available at https://github.com/zgzxy001/STMT.
Synthetic-to-Real Domain Adaptation for Action Recognition: A Dataset and Baseline Performances
Mar 17, 2023

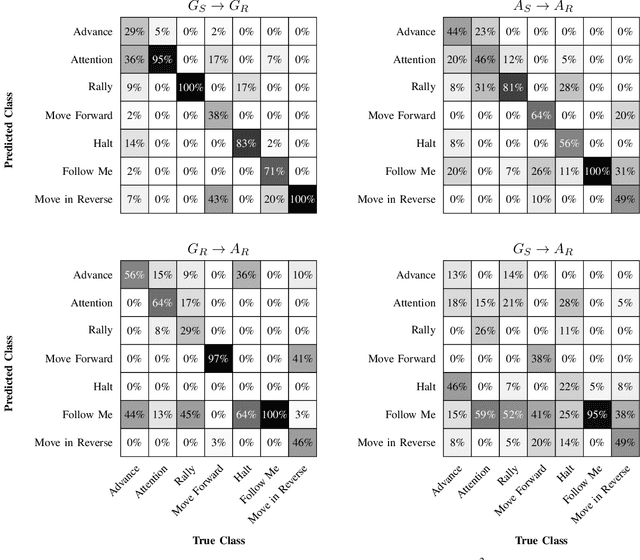
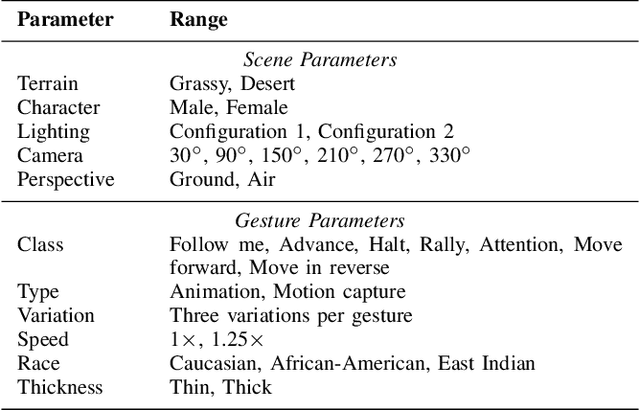
Human action recognition is a challenging problem, particularly when there is high variability in factors such as subject appearance, backgrounds and viewpoint. While deep neural networks (DNNs) have been shown to perform well on action recognition tasks, they typically require large amounts of high-quality labeled data to achieve robust performance across a variety of conditions. Synthetic data has shown promise as a way to avoid the substantial costs and potential ethical concerns associated with collecting and labeling enormous amounts of data in the real-world. However, synthetic data may differ from real data in important ways. This phenomenon, known as \textit{domain shift}, can limit the utility of synthetic data in robotics applications. To mitigate the effects of domain shift, substantial effort is being dedicated to the development of domain adaptation (DA) techniques. Yet, much remains to be understood about how best to develop these techniques. In this paper, we introduce a new dataset called Robot Control Gestures (RoCoG-v2). The dataset is composed of both real and synthetic videos from seven gesture classes, and is intended to support the study of synthetic-to-real domain shift for video-based action recognition. Our work expands upon existing datasets by focusing the action classes on gestures for human-robot teaming, as well as by enabling investigation of domain shift in both ground and aerial views. We present baseline results using state-of-the-art action recognition and domain adaptation algorithms and offer initial insight on tackling the synthetic-to-real and ground-to-air domain shifts.
AZTR: Aerial Video Action Recognition with Auto Zoom and Temporal Reasoning
Mar 02, 2023We propose a novel approach for aerial video action recognition. Our method is designed for videos captured using UAVs and can run on edge or mobile devices. We present a learning-based approach that uses customized auto zoom to automatically identify the human target and scale it appropriately. This makes it easier to extract the key features and reduces the computational overhead. We also present an efficient temporal reasoning algorithm to capture the action information along the spatial and temporal domains within a controllable computational cost. Our approach has been implemented and evaluated both on the desktop with high-end GPUs and on the low power Robotics RB5 Platform for robots and drones. In practice, we achieve 6.1-7.4% improvement over SOTA in Top-1 accuracy on the RoCoG-v2 dataset, 8.3-10.4% improvement on the UAV-Human dataset and 3.2% improvement on the Drone Action dataset.
Open-Set Automatic Target Recognition
Nov 10, 2022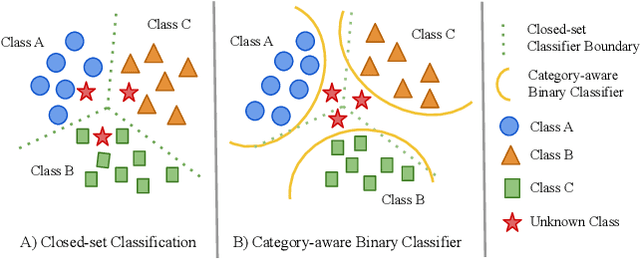

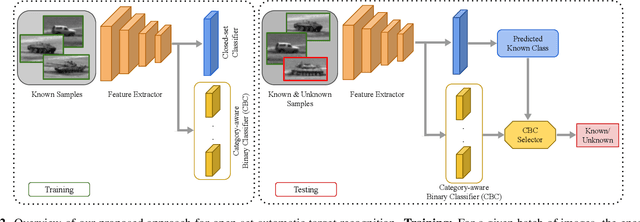

Automatic Target Recognition (ATR) is a category of computer vision algorithms which attempts to recognize targets on data obtained from different sensors. ATR algorithms are extensively used in real-world scenarios such as military and surveillance applications. Existing ATR algorithms are developed for traditional closed-set methods where training and testing have the same class distribution. Thus, these algorithms have not been robust to unknown classes not seen during the training phase, limiting their utility in real-world applications. To this end, we propose an Open-set Automatic Target Recognition framework where we enable open-set recognition capability for ATR algorithms. In addition, we introduce a plugin Category-aware Binary Classifier (CBC) module to effectively tackle unknown classes seen during inference. The proposed CBC module can be easily integrated with any existing ATR algorithms and can be trained in an end-to-end manner. Experimental results show that the proposed approach outperforms many open-set methods on the DSIAC and CIFAR-10 datasets. To the best of our knowledge, this is the first work to address the open-set classification problem for ATR algorithms. Source code is available at: https://github.com/bardisafa/Open-set-ATR.